spark环境安装
源码包下载:
http://archive.apache.org/dist/spark/spark-2.1.1/v
集群环境:
master 192.168.1.99
slave1 192.168.1.100
slave2 192.168.1.101
下载安装包:
# Master
wget http://archive.apache.org/dist/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/src
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz -C /usr/local/src
tar -zxvf spark-2.1.-bin-hadoop2..tgz
tar -zxvf scala-2.11.8.tgz
mv spark-2.1.-bin-hadoop2. /usr/local/spark
mv scala-2.11.8 /usr/local/scala
修改配置文件:
cd /usr/local/spark/conf
vim spark-env.sh
export SCALA_HOME=/usr/local/scala
export JAVA_HOME=/usr/local/jdk1.8.0_181
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/spark
SPARK_DRIVER_MEMORY=1G
vim slaves
slave1
salve2
配置环境变量:
#Master slave1 slave2
vim ~/.bashrc
SPARK_HOME=/usr/local/spark
PATH=$PATH:$SPARK_HOME/bin #刷新环境变量
source ~/.bashrc
拷贝安装包:
scp -r /usr/local/spark root@slave1:/usr/local/spark
scp -r /usr/local/spark root@slave2:/usr/local/spark scp -r /usr/local/scala root@slave1:/usr/local/scala
scp -r /usr/local/scala root@slave2:/usr/local/scala
启动集群:
/usr/local/spark/sbin/start-all.sh
集群状态:
#Master
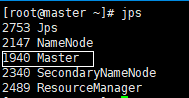
#slave1

#slave2

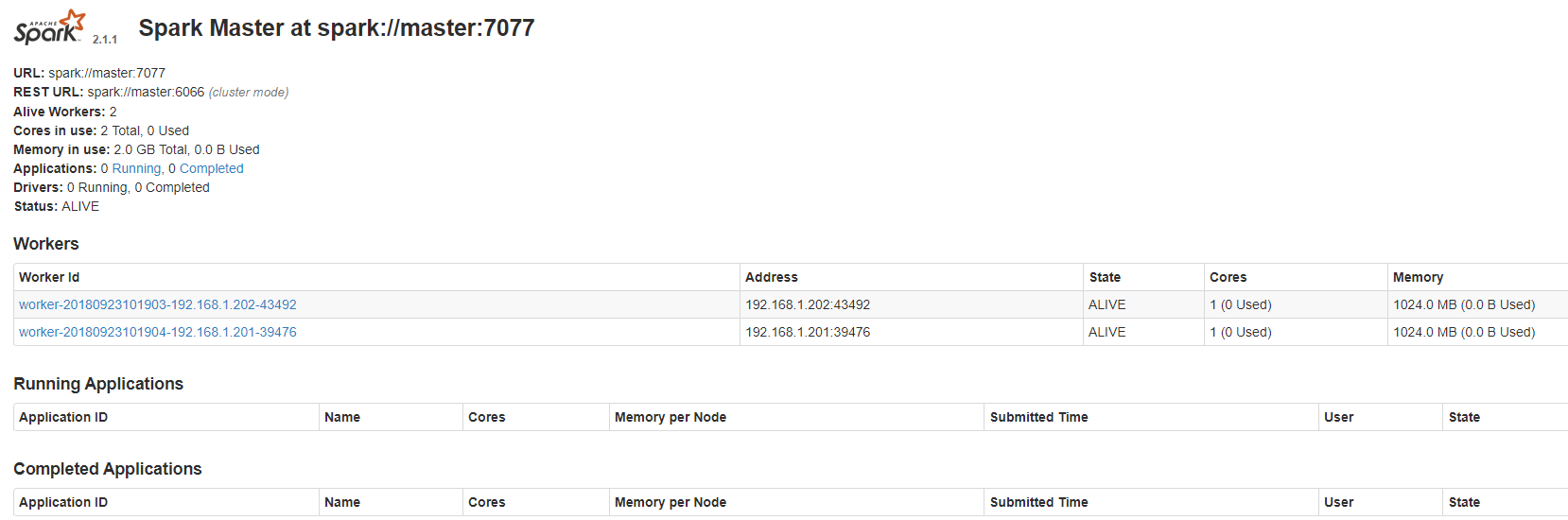
监控网页:
http://master:8080
验证:
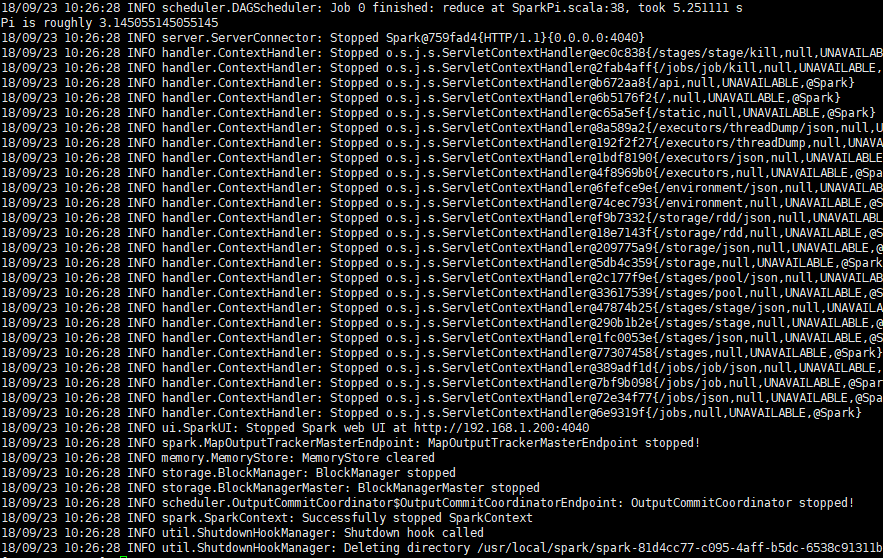
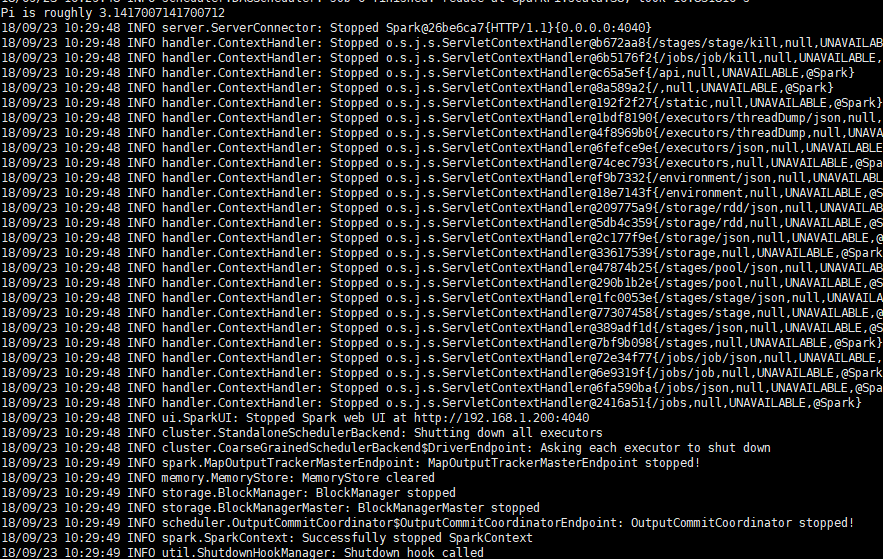
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster /usr/local/spark/examples/jars/spark-examples_2.11-2.1.1.jar 100

spark环境安装的更多相关文章
- 详解 jupyter notebook 集成 spark 环境安装
来自: 代码大湿 代码大湿 1 相关介绍 jupyter notebook是一个Web应用程序,允许你创建和分享,包含活的代码,方程的文件,可视化和解释性文字.用途包括:数据的清洗和转换.数值模拟.统 ...
- 手工命令行 搭建 hadoop 和 spark 环境
环境准备:3台CentOS7,64位,Hadoop2.7需要64位Linux 192.168.20.161 192.168.20.162 192.168.20.163 三台机器分别叫host01. ...
- Windows下安装Spark环境
根据博客总结 https://blog.csdn.net/nxw_tsp/article/details/78281533 需要的安装软件可以在网盘下载: 链接:https://pan.baidu.c ...
- hadoop环境的安装 和 spark环境的安装
hadoop环境的安装1.前提:安装了java spark环境的安装1.前提:安装了java,python2.直接pip install pyspark就可以安装完成.(pip是python的软件安装 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- Spark——Standalone 环境安装及简单使用
Standalone 环境安装 将 spark-3.0.0-bin-hadoop3.2.tgz 文件解压缩在指定位置(/opt/module) tar -zxvf spark-3.0.0-bin-ha ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- 在MacOs上配置Hadoop和Spark环境
在MacOs上配置hadoop和spark环境 Setting up Hadoop with Spark on MacOs Instructions 准备环境 如果没有brew,先google怎样安装 ...
随机推荐
- Dubbo源码导入Eclipse遇到的问题
1.怎么将Dubbo源码导入到Eclipse 方法一: 打开Eclipse,File-->Import-->maven-->Exsting Maven Projects,选择dubb ...
- Dubbo(一) -- 初体验
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架. 一.Dubbo出现的背景 随着互联网的发展,网站应用的规模不断扩大,常规的 ...
- golang 小知识-持续更新中
Golang 中的指针 - Pointer Go 的原生数据类型可以分为基本类型和高级类型,基本类型主要包含 string, bool, int 及 float 系列,高级类型包含 struct,ar ...
- Neutron SDN 手动实现手册
安装架构介绍 本文旨在通过自己搭建类似neutron (openvswitch + gre) 实现SDN 的环境,学习了解其工作原理,模拟核心原理,比如:同一租户自定义网络 instance 互通,手 ...
- Excel 2010版筛选怎么用
很多人在使用excel表格的时候,不知道这个筛选功能怎么用,可以对我们平时做数据和表格带来哪些帮助.那么,接下来,小敏以excel表格2010版为例,跟大家分享一下这个excel表格筛选功能的使用方法 ...
- Python语音合成
注意:通过win32com调用的windows的SAPI,所以本脚本只适应于windows平台 代码很简单 #coding:utf-8 import win32com.client import ti ...
- svn-maven-tomcat自动发布脚本
#!/bin/sh #svn-maven-tomcat自动发布脚本 #变量设置 svnpath=svn://10.60.10.120/研发部/xx-maven svnusername=xxx svnp ...
- 树形DP求各点能走到的最远距离
hdu2196 Computer Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- Windows系统下做定时任务为Oracle数据库每天自动备份
1.创建备份目录d:\backup, 创建批处理命令Bak.bat,编写备份脚本 ? 1 2 exp user/passwd@orcl DIRECT=Y BUFFER=100000 FILE=D:\b ...
- Jmeter性能测试实践之java请求
前言 Apache Jmeter是开源.易用的性能测试工具,之前工作中用过几次对http请求进行性能测试,对jmeter的基本操作有一些了解.最近接到开发的对java请求进行性能测试的需求,所以需要 ...