Java ConcurrentHashMap 源代码分析
Java ConcurrentHashMap
jdk1.8
之前用到过这个,但是一直不清楚原理,今天抽空看了一下代码
但是由于我一直在使用java8,试了半天,暂时还没复现过put死循环的bug
查了一下,java8似乎修复了这个:不过还是可能导致数据丢失
https://cloud.tencent.com/developer/article/1120823
java8之前都是头插入,而java8却是靠新一位的掩码来把链表分成两个,没有改变相对顺序
果然还是代码理解的不透彻啊
Java 8的ConcurrentMap是真的不好理解
我们现在开始分析ConcurrentHashMap
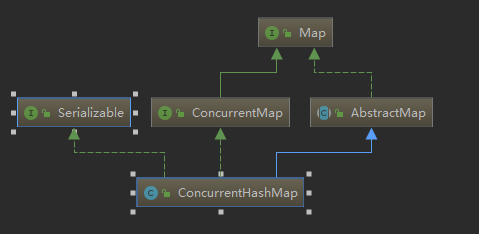
跟HashMap类似
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
先看一下java 8 中的ConcurrentHashMap的 一些定义常量
//定义了最大容量
private static final int MAXIMUM_CAPACITY = 1 << 30;
//定义了每个大小
private static final int DEFAULT_CAPACITY = 16;
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//最多支持多少个并发操作 这个是1.7之前的,1.8基本没用到过这个
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
//同hashmap
private static final float LOAD_FACTOR = 0.75f;
//树阈值
static final int TREEIFY_THRESHOLD = 8;
//红黑树退化链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
//数量到达这些的时候开始变成红黑树
static final int MIN_TREEIFY_CAPACITY = 64;
先来看一下构造方法
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
//只是设置 sizeCtl 如果初始容量过大,那么设置为最大容量,否则设置大小为
//
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
//对齐到2的整数次幂 跟hashmap一样
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
//初始容量,扩容因子,最多并发等级
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//可见如果如果出事容量小于最多并发等级的话,会设置为为最多并发等级那么多的初始容量
//不过这个构造方法应该是兼容以前的构造方法,concurrencyLevel在1.8没太大意义
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
//初始容量/负载因子,应该是用这个来预判最大容量
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
初始化大小是initialCapacity*1.5 + 1然后对齐到2的整数次幂跟HashMap一样
//看一下init
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//这个时候检查创建状态
while ((tab = table) == null || tab.length == 0) {
//没创建才能进来
//sizeCtl<0说明有其他的线程抢先拿到了自旋锁 那么放弃执行
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
//CAS尝试获取 如果 sizeCtl == sc 成功那么交换成-1
//SIZECTL = U.objectFieldOffset (k.getDeclaredField("sizeCtl"));
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
//获取到了
try {
//这里相当于多线程单例模式两个if来判断
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
//创建完成
table = tab = nt;
//减去1/4相当于*0.75
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
下面的函数经常用到相当于这样
int baseOffset = unsafe.arrayBaseOffset(array.getClass());
int indexScale = unsafe.arrayIndexScale(array.getClass());
baseOffset + i*indexScale
主要目的就是获取最新的volatile的数据
//这个函数相当于tab获取i节点最新的对象数据
//
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
// Class<?> ak = Node[].class;
// ABASE = U.arrayBaseOffset(ak); 获取数组第一个元素的偏移地址
// int scale = U.arrayIndexScale(ak); 获取数组中元素的增量地址
// Integer.numberOfLeadingZeros 是获取前导0的数量
// ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
//cas 交换c,v
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
这里定义了Node的状态,通过node.hash来判断
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//ConcurrentHashMap 的key和value不能存放空
//而HashMap中key,Value 都是null
if (key == null || value == null) throw new NullPointerException();
//跟HashMap一样,计算hashcode,然后高16位跟低16位按位异或
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table从来都没有创建过,那么就创建
if (tab == null || (n = tab.length) == 0)
//这里面通过CAS创建的
tab = initTable();
//先获取i 然后获取Node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//i 这个地方不存在节点 那么尝试创建一个节点并cas
//如果成功了就跳出循环了
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//i这个位置不是null 判断是不是应该移动 但是估计这里hash改变过了
// 在 transfer方法中
// 这里面如果是正在扩容,那么这个线程过去帮忙扩容
else if ((fh = f.hash) == MOVED)
//扩容操作
tab = helpTransfer(tab, f);
else {
//开始正式插入k,v
V oldVal = null;
//这里仅仅锁住桶
synchronized (f) {
if (tabAt(tab, i) == f) {
//判断hash>=0 这里面hash >= 0 认为是链表,否则认为是红黑树
if (fh >= 0) {
//这里面判断一共多少个节点
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//一样,先判断hash然后用equals
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
//全相等,赋值跳出链表
oldVal = e.val;
//判断是不是可以覆盖
if (!onlyIfAbsent)
e.val = value;
break;
}
//
Node<K,V> pred = e;
//如果到链表结尾
if ((e = e.next) == null) {
//尾部插入数据
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
//这里是对应红黑树的操作
Node<K,V> p;
binCount = 2;
//在红黑树中放一个值
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//这里判断节点数量
if (binCount != 0) {
//如果大于树的阈值,那就转化为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//判断大小,尝试扩容
addCount(1L, binCount);
return null;
}
/**
* Replaces all linked nodes in bin at given index unless table is
* too small, in which case resizes instead.
*/
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//当tab小于MIN_TREEIFY_CAPACITY阈值的时候尝试resize
//如果tab.length比较小,不会转化为红黑树,直接扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
//检查这个位置
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
//锁上这个桶
synchronized (b) {
//再次确认
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
//遍历这个桶的链表
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
//如果当前节点
if ((p.prev = tl) == null)
hd = p;//第一个元素赋值给hd
else
//把树节点赋值给上一个的下一个,就是连上了
tl.next = p;
tl = p;
}
//用连在一起的treenode创建一个红黑树
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
/**
* Tries to presize table to accommodate the given number of elements.
*
* @param size number of elements (doesn't need to be perfectly accurate)
*/
private final void tryPresize(int size) {
//对齐
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
//判断tab
if (tab == null || (n = tab.length) == 0) {
//当前容量和需要扩大到的容量取max
n = (sc > c) ? sc : c;
//CAS获取锁 然后初始化
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
//相当于*0.75
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
//如果超过了最大容量就不要扩容了
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
//如果tab!=table说明已经迁移完了不用再迁移了
else if (tab == table) {
// RESIZE_STAMP_BITS = 16;
// Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)
//这个函数大概意思就是把第16位置1,为了变成一个负数
int rs = resizeStamp(n);
if (sc < 0) {
//sc < 0 相当于获取到锁
Node<K,V>[] nt;
//这里还是不太理解=================================================
//我还没想出来为什么sc<0还会进来 所以下面是猜测
//RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
//所以RESIZE_STAMP_SHIFT也是16
//这里是我还没有仔细判断 挖个坑
//因为别的地方也有可能获取到锁导致sc<0
//所以这里判断sc是不是真正自己的
//这里sc右移 如果sc!=rs 应该是别的线程已经扩容完毕
//如果上一个没执行完,那么
// sc == (rs << RESIZE_STAMP_SHIFT) + 2
// transfer中 sc的改变只能是每次 -1
// nextTable == null 说明nextTable还没创建所以不执行
// MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 这个判断是防止帮助的线程太多,导致sc变成正数 (个人猜测)
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//多一个线程进入 + 1
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
//开始扩容
transfer(tab, nt);
}
//事实上先执行这个相当于先去获取锁
//如果能获取到那么把sizeCtl设置为一个负数值 + 2 就是刚才计算的那个值
//然后执行一个扩容操作
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
上面的代码会多次调用 transfer方法
第一次是 transfer(tab,null)
从第二次开始 调用 transfer(tab,nt);
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*/
//开始并且将transfer tab的数据逐渐迁移到nextTab中
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
//n为tab的旧长度
int n = tab.length, stride;
//这里在判断是不是多核心cpu
//参考了一下别人的注释:
/*
stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16
stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,
将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
*/
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
//nextTab为null那么先创建一个二倍大的tab
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
//注意这里,nextTable是ConcurrentHashMap中的属性
nextTable = nextTab;
// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置
transferIndex = n;
}
//nextTab的长度
int nextn = nextTab.length;
//这里参考别人的注释
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。
// 所以在putVal中才可以检查
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
//这个循环没看懂 参考了别人的
/*
// 下面这个 while 真的是不好理解
// advance 为 true 表示可以进行下一个位置的迁移了
// 简单理解结局:i 指向了 transferIndex,bound 指向了 transferIndex-stride
*/
while (advance) {
int nextIndex, nextBound;
// 0
if (--i >= bound || finishing)
advance = false;//设为false下次跳出
/*
// 将 transferIndex 值赋给 nextIndex
// 这里 transferIndex 一旦小于等于 0,说明原数组的所有位置都有相应的线程去处理了
*/
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
//在这里领到一个任务
//这次的任务边界
//i是结束位置 bound是开始位置
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
//如果不在oldtab的长度范围内,该线程准备退出
//说明领到的任务失效了
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
//在这里覆盖原来的
table = nextTab;
//长度的0.75
sizeCtl = (n << 1) - (n >>> 1);
return;
}
/*
// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,
// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务
// 进来的时候假如说 sc=sizeCtl = -21xxxxx174 rs<<16==-21xxx174 - 2
// 然后CAS sizeCtl=-21xxxxx175 sc-2=-21xxxxx176
*/
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//这个线程迁移完之后判断是不是完全执行完
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//在这里说明最后进入的线程都已经结束了
finishing = advance = true;
i = n; // recheck before commit
}
}
//oldtab的i位置如果为null 那么把他设为 刚才创建的ForwardingNode
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//这个位置不是null 但是这个位置是一个ForwardingNode
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
//对这个桶加锁 然后开始把数据搬到新的tab
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//hash > 0 说明是链表
if (fh >= 0) {
//这里跟HashMap类似,就是分成两个链表
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//把新链表放在对应的位置上
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
//设置原位置为fwd
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
//红黑树
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 将 ln 放置在新数组的位置 i
setTabAt(nextTab, i, ln);
// 将 hn 放置在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
}
}
}
}
}
相比之下,get就好多了 一个CAS锁都没有
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//先去获取一下hashcode 跟hashmap一样,高16xor低16
int h = spread(key.hashCode());
//判断表是否创建,以及对应的位置有没有节点
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//hashcode相等,判断是不是
if ((eh = e.hash) == h) {
//判断key的hashcode,判断key.equals
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//eh < 0说明是个红黑树节点或者这个地方正在扩容
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//都不是这个地方应该是个链表,尝试遍历
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
注意这里,因为红黑树的节点是继承了Node,所以TreeNode是把这个方法覆盖了
//class TreeNode
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
总体感觉:
ConcurrentMap跟1.7不一样,1.7是使用segment分段锁,这种感觉就是每一个segment里面放一个(1.7)hashmap先通过key找到对应的segment然后再去hashmap里面找,put的时候对应的segment加锁
1.8完全就是每一个小桶里面可以存null treenode node,完全没有使用segment锁,put对应的表的时候,会synchronized对应的桶,然后尝试放进去,扩容的时候,也是使用乐观锁,如果可以扩容,那么把sizectl设置为负数,每次cas获取一个小任务,如果这个时候别的线程在put会检查,如果可以,别的线程也会进来帮你分担任务,不过涉及到大量的unsafe类的操作,流程比较容易理解,但是实现还是不好理解
关于为什么使用tabAt这几个函数:
https://www.cnblogs.com/lc-java/p/9301416.html
java中可以创建volatile数组,不过只是一个指向数组的引用,而不是整个数组,如果改变引用指向的数组,将会受到volatile的保护,但是如果多个线程同时改变数组的元素,volatile 标示符就不能起到之前的保护作用了。
这里面有图,很容易理解这几个Map的区别
<http://www.importnew.com/28263.html>
Unsafe类
https://www.jianshu.com/p/cda24891f9e4
注意事项
https://blog.csdn.net/lx1848/article/details/81256443
Java ConcurrentHashMap 源代码分析的更多相关文章
- Android系统进程间通信Binder机制在应用程序框架层的Java接口源代码分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址:http://blog.csdn.net/luoshengyang/article/details/6642463 在前面几篇文章中,我们详细介绍了A ...
- java TreeMap 源代码分析 平衡二叉树
TreeMap 的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点. TreeSet 和 TreeMap 的关系 为了让大家了解 TreeMap 和 Tre ...
- Java ThreadLocal 源代码分析
Java ThreadLocal 之前在写SSM项目的时候使用过一个叫PageHelper的插件 可以自动完成分页而不用手动写SQL limit 用起来大概是这样的 最开始的时候觉得很困惑,因为直接使 ...
- Java HashMap 源代码分析
Java HashMap jdk 1.8 Java8相对于java7来说HashMap变化比较大,在hash冲突严重的时候java7会退化为链表,Java8会退化为TreeMap 我们先来看一下类图: ...
- Java ArrayList 源代码分析
Java ArrayList 之前曾经参考 数据结构与算法这本书写过ArrayList的demo,本来以为实现起来都差不多,今天抽空看了下jdk中的ArrayList的实现,差距还是很大啊 首先看一下 ...
- Android应用程序进程启动过程的源代码分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址: http://blog.csdn.net/luoshengyang/article/details/6747696 Android 应用程序框架层创 ...
- java源代码分析----jvm.dll装载过程
简述众所周知java.exe是java class文件的执行程序,但实际上java.exe程序只是一个执行的外壳,它会装载jvm.dll(windows下,以下皆以windows平台为例,linux下 ...
- Java源代码分析与生成
源代码分析:可使用ANTLRANTLR是开源的语法分析器,可以用来构造自己的语言,或者对现有的语言进行语法分析. JavaParser 对Java代码进行分析 CodeModel 用于生成Java代码 ...
- JAVA随笔篇一(Timer源代码分析和scheduleAtFixedRate的使用)
写完了基础篇,想了非常久要不要去写进阶篇.去写JSP等等的用法.最后决定先不去写.由于自己并非JAVA方面的大牛.眼下也在边做边学,所以决定先将自己不懂的拿出来学并记下来. Timer是Java自带的 ...
随机推荐
- Git小抄
生存必备 分支 忽略已提交的文件 版本回退 撤销修改 删除文件 修改最后一次提交的说明信息 tag 生存必备 git init git add <file1> <file2> ...
- 外部主机无法访问IIS发布的网站
在IIS中发布网站,在本地可以直接访问,但是其他主机不能访问改发布的网站. 此问题一般是IIS的配置或者防火墙的配置的原因. 如果禁用了以下防火墙入站规则会导致外部主机无法访问本地发布的网 ...
- 乘风破浪:LeetCode真题_019_Remove Nth Node From End of List
乘风破浪:LeetCode真题_019_Remove Nth Node From End of List 一.前言 这次总算到了链表的操作了,之后肯定会有排序算法,二叉树,排序树,图等等的操作,现在我 ...
- NJCTF 2017 web pictures'wall(详解)
题目: 图片墙上有图片 url:http://218.2.197.235:23719/ writeup: 首先各种尝试登陆,发现任意用户及密码都可以登陆,但登陆后的页面提示的是“Root has pr ...
- Linux性能测试工具
Linux性能测试工具 在测试中,我们不仅需要查看系统日志信息,而且还要使用大量的性能监测工具来关注某些地方,如内存.CPU等.在Linux系统中,所有的运行参数保存在虚拟目录/proc中,换句话说, ...
- 【转】深入浅出 iOS 之生命周期
[iOS]深入浅出 iOS 之生命周期 深入浅出 iOS 之生命周期 http://blog.csdn.net/kesalin/article/details/6691766 罗朝辉(http:// ...
- java多态实例
学校有两个打印机,一个彩印,一个黑白印,都打印输出 public class printerDemo { public static void main(String[] args) { colorP ...
- python读取xml文件报错ValueError: multi-byte encodings are not supported
1.在使用python对xml文件进行读取时,提示ValueError: multi-byte encodings are not supported 很多贴子上说把xml的编码格式改为,就可以正常执 ...
- 关于c++ list容器的操作摸索
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/chaoweilanmao/article/details/30793859 #include< ...
- Qt之操作数据库(SQLite)实例
QtSql模块提供了与平台以及数据库种类无关的访问SQL数据库的接口,这个接口由利用Qt的模型视图结构将数据库与用户界面集成的一套类来支持.QSqlDatabase对象象征了数据库的关联.Qt使用驱动 ...