用scikit-learn学习BIRCH聚类
在BIRCH聚类算法原理中,我们对BIRCH聚类算法的原理做了总结,本文就对scikit-learn中BIRCH算法的使用做一个总结。
1. scikit-learn之BIRCH类
在scikit-learn中,BIRCH类实现了原理篇里讲到的基于特征树CF Tree的聚类。因此要使用BIRCH来聚类,关键是对CF Tree结构参数的处理。
在CF Tree中,几个关键的参数为内部节点的最大CF数B, 叶子节点的最大CF数L, 叶节点每个CF的最大样本半径阈值T。这三个参数定了,CF Tree的结构也基本确定了,最后的聚类效果也基本确定。可以说BIRCH的调参就是调试B,L和T。
至于类别数K,此时反而是可选的,不输入K,则BIRCH会对CF Tree里各叶子节点CF中样本的情况自己决定类别数K值,如果输入K值,则BIRCH会CF Tree里各叶子节点CF进行合并,直到类别数为K。
2. BIRCH类参数
在scikit-learn中,BIRCH类的重要参数不多,下面一并讲解。
1) threshold:即叶节点每个CF的最大样本半径阈值T,它决定了每个CF里所有样本形成的超球体的半径阈值。一般来说threshold越小,则CF Tree的建立阶段的规模会越大,即BIRCH算法第一阶段所花的时间和内存会越多。但是选择多大以达到聚类效果则需要通过调参决定。默认值是0.5.如果样本的方差较大,则一般需要增大这个默认值。
2) branching_factor:即CF Tree内部节点的最大CF数B,以及叶子节点的最大CF数L。这里scikit-learn对这两个参数进行了统一取值。也就是说,branching_factor决定了CF Tree里所有节点的最大CF数。默认是50。如果样本量非常大,比如大于10万,则一般需要增大这个默认值。选择多大的branching_factor以达到聚类效果则需要通过和threshold一起调参决定
3)n_clusters:即类别数K,在BIRCH算法是可选的,如果类别数非常多,我们也没有先验知识,则一般输入None,此时BIRCH算法第4阶段不会运行。但是如果我们有类别的先验知识,则推荐输入这个可选的类别值。默认是3,即最终聚为3类。
4)compute_labels:布尔值,表示是否标示类别输出,默认是True。一般使用默认值挺好,这样可以看到聚类效果。
在评估各个参数组合的聚类效果时,还是推荐使用Calinski-Harabasz Index,Calinski-Harabasz Index在scikit-learn中对应的方法是metrics.calinski_harabaz_score.
3. BIRCH运用实例
这里我们用一个例子来学习BIRCH算法。完整代码参见我的github:https://github.com/ljpzzz/machinelearning/blob/master/classic-machine-learning/birch_cluster.ipynb
首先,我们载入一些随机数据,并看看数据的分布图:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets.samples_generator import make_blobs
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]], cluster_std=[0.4, 0.3, 0.4, 0.3],
random_state =9)
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
输出图如下:
现在我们用BIRCH算法来聚类,首先我们选择不输入可选的类别数K,看看聚类效果和Calinski-Harabasz 分数。
from sklearn.cluster import Birch
y_pred = Birch(n_clusters = None).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
from sklearn import metrics
print "Calinski-Harabasz Score", metrics.calinski_harabaz_score(X, y_pred)
输出图如下:
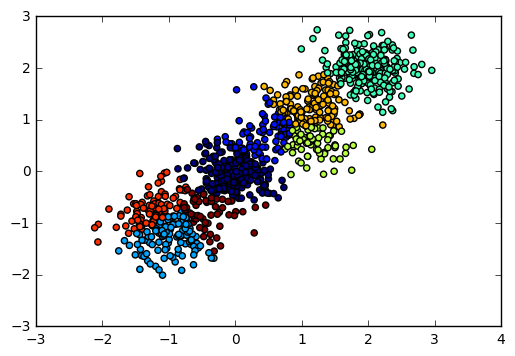
对应的Calinski-Harabasz 分数输出为:
Calinski-Harabasz Score 2220.95253905
由于我们知道数据是4个簇随机产生的,因此我们可以通过输入可选的类别数4来看看BIRCH聚类的输出。代码如下:
y_pred = Birch(n_clusters = 4).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
print "Calinski-Harabasz Score", metrics.calinski_harabaz_score(X, y_pred)
输出图如下:
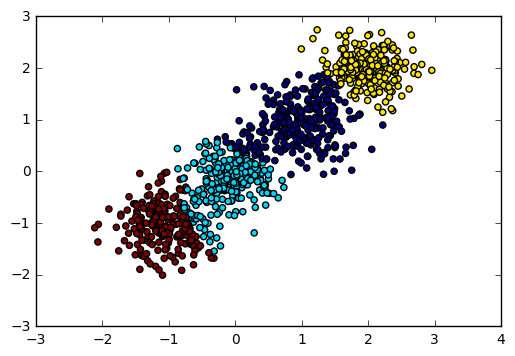
对应的Calinski-Harabasz 分数输出为:
Calinski-Harabasz Score 2816.40765268
可见如果我们不输入类别数的话,在某些时候BIRCH算法的聚类效果并不一定好,因此这个可选的类别数K一般还是需要调参的。
对于threshold和branching_factor我们前面还没有去调参,使用了默认的threshold值0.5和默认的branching_factor值50.
现在我们将threshold从0.5降低为0.3,让BIRCH算法第一阶段的CF Tree规模变大,并观察Calinski-Harabasz 分数。
y_pred = Birch(n_clusters = 4, threshold = 0.3).fit_predict(X)
print "Calinski-Harabasz Score", metrics.calinski_harabaz_score(X, y_pred)
对应的Calinski-Harabasz 分数输出为:
Calinski-Harabasz Score 3295.63492273
可见此时的聚类效果有了进一步的提升,那么是不是threshold越小越好呢?我们看看threshold从0.3降低为0.1时的情况。
y_pred = Birch(n_clusters = 4, threshold = 0.1).fit_predict(X)
print "Calinski-Harabasz Score", metrics.calinski_harabaz_score(X, y_pred)
对应的Calinski-Harabasz 分数输出为:
Calinski-Harabasz Score 2155.10021808
也就是说threshold不是越小聚类效果越好。
我们基于threshold为0.3的情况,调试下branching_factor,将branching_factor从50降低为20.让BIRCH算法第一阶段的CF Tree规模变大。
y_pred = Birch(n_clusters = 4, threshold = 0.3, branching_factor = 20).fit_predict(X)
print "Calinski-Harabasz Score", metrics.calinski_harabaz_score(X, y_pred)
对应的Calinski-Harabasz 分数输出为:
Calinski-Harabasz Score 3301.80231064
可见调试branching_factor也可以让聚类分数提高。那么和threshold类似,是不是branching_factor越小越好呢?我们将branching_factor从20降低为10,观察聚类分数:
y_pred = Birch(n_clusters = 4, threshold = 0.3, branching_factor = 10).fit_predict(X)
print "Calinski-Harabasz Score", metrics.calinski_harabaz_score(X, y_pred)
对应的Calinski-Harabasz 分数输出为:
Calinski-Harabasz Score 2800.87840962
也就是说和threshold类似,branching_factor不是越小聚类效果越好,需要调参。
以上就是BIRCH算法的一些经验,希望可以帮到朋友们。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
用scikit-learn学习BIRCH聚类的更多相关文章
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- 用scikit-learn学习K-Means聚类
在K-Means聚类算法原理中,我们对K-Means的原理做了总结,本文我们就来讨论用scikit-learn来学习K-Means聚类.重点讲述如何选择合适的k值. 1. K-Means类概述 在sc ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- ArcGIS案例学习笔记-聚类点的空间统计特征
ArcGIS案例学习笔记-聚类点的空间统计特征 联系方式:谢老师,135-4855-4328,xiexiaokui@qq.com 目的:对于聚集点,根据分组字段case field,计算空间统计特征 ...
- Learning How to Learn学习笔记(转)
add by zhj: 工作中提高自己水平的最重要的一点是——快速的学习能力.这篇文章就是探讨这个问题的,掌握了快速学习能力的规律,你自然就有了快速学习能力了. 原文:Learning How to ...
随机推荐
- Visual Studio 2010的MSDN帮助文档离线使用
如果没有在安装vs过程中安装帮助,也可通过Visual Studio帮助菜单中的Manage Help Settings来对帮助进行设置或安装. 可以选择从磁盘安装内容,如果选择从磁盘安装可能会要求提 ...
- 前端网络、JavaScript优化以及开发小技巧
一.网络优化 YSlow有23条规则,中文可以参考这里.这几十条规则最主要是在做消除或减少不必要的网络延迟,将需要传输的数据压缩至最少. 1)合并压缩CSS.JavaScript.图片,静态资源CDN ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
- iframe用法
<iframe src="http://caiyanli.top/" height="500" width="500" frameb ...
- django server之间通过remote user 相互调用
首先,场景是这样的:存在两个django web应用,并且两个应用存在一定的联系.某些情况下彼此需要获取对方的数据. 但是我们的应用肯经都会有对应的鉴权机制.不会让人家随随便便就访问的对吧.好比上车要 ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(80)-自由桌面
系列目录 前言 这次我们来做一个有趣的事情,有朋友跟做了很远,找我要自由桌面的代码,这次我们将演示自由桌面的代码. 自由桌面:用户可以随意增删改桌面的布局.个数(只留自己需要看到的数据),这次纯属Ea ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(64)-补充WebApi与Unity注入-配置文件
系列目录 上一篇演示了WebApi利用Unity注入 很多人问我如何用配置文件来配置注入,本节演示如何利用配置文件来注入,道理是一样的,跳转到上一节下载源码一起来动手! 1.打开源码定位到文件Depe ...
- jQuery学习之路(3)- 事件
▓▓▓▓▓▓ 大致介绍 jQuery增加了并扩展了基本的事件处理机制,不但提供了更加优雅的事件处理语法,而且极大地增强了事件处理能力 ▓▓▓▓▓▓ jQuery中的事件 ▓▓▓▓▓▓ 加载DOM 在j ...
- 玩转spring boot——结合JPA事务
接着上篇 一.准备工作 修改pom.xml文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&q ...
- JavaScript基础知识总结(四)
JavaScript语法 八.函数 函数就是完成某个功能的一组语句,函数由关键字function + 函数名 + 加一组参数定义: 函数在定义后可以被重复调用,通常将常用的功能写成一个函数,利用函数可 ...