数据压缩之经典——哈夫曼编码(Huffman)
(笔记图片截图自课程Image and video processing: From Mars to Hollywood with a stop at the hospital的教学视频,使用时请注意版权要求。)
JPEG用哈夫曼编码(Huffman Encoder)作为其符号编码。哈弗曼编码是压缩算法中的经典,它理论上可以将数据编成平均长度最小的无前缀码(Prefix-Free Code)。
为什么要进行编码?
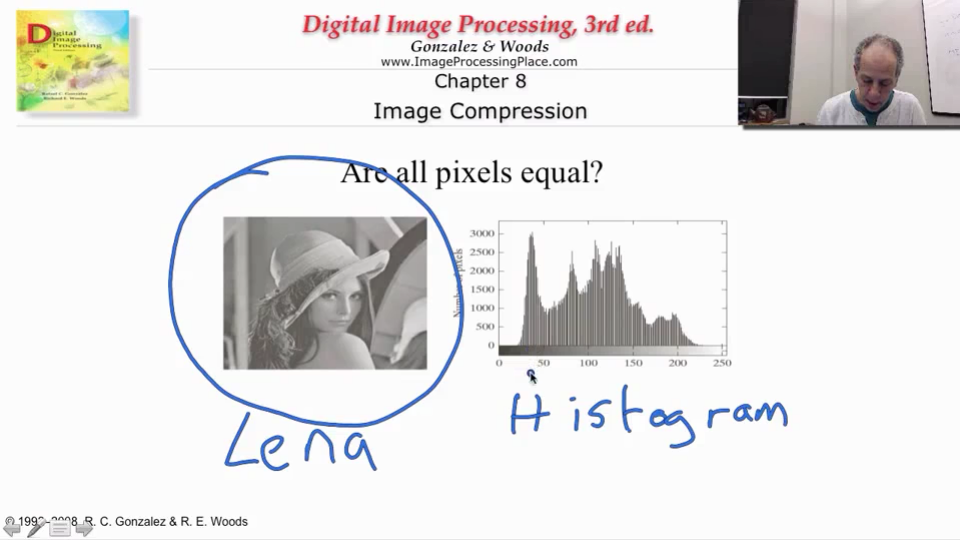
关于Lena:莱娜图(Lenna)是指刊于1972年11月号《花花公子》(Playboy)杂志上的一张裸体插图照片的一部分,是一张大小为512x512像素的标准测试图。该图在数位影像处里学习与研究中颇为知名,常被用作数位影像处里各种实验(例如资料压缩和降噪)及科学出版物的例图。(几乎每一本图像处理相关的书都会出现这张图片~)
Lena的直方图(Histogram):从Lena的直方图中可以看出,图片中每个灰度值出现的概率是不相同的。这里,中间灰度值部分出现的概率比较高,两边灰度值出现概率非常低。所以,如果每个灰度值都进行同样长度的编码,似乎就太浪费了。
概率高的符号用短码,概率低的符号用长码

正是因为每个灰度值出现的概率不一样,我们用更短的编码来表示经常出现的灰度值,用更长的编码来表示几乎不出现的灰度值,平均下来编码长度就会比等长编码短,从而节省了空间。
Huffman编码生成方式

1. 将要编码的符号按出现概率高到低排列;
2. 将出现概率最低的两个符号进行组合,两者概率加起来得到组合概率;
3. 将得到的组合概率与其他符号的概率再进行排序;
4. 重复(2),直到出现组合概率为1。
听起来很抽象?实战一次吧。
首先,按照各符号出现概率大小进行排列;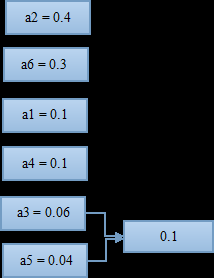
找到概率最小的两个符号,进行组合。这里是a3和a5最小,两者组合起来概率为0.1;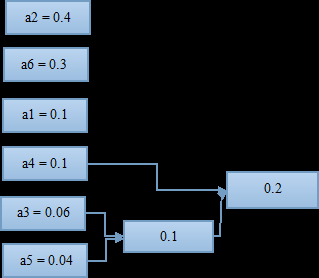
将组合好的两个符号看作一个新的符号,与其他符号再进行一次排列,找到出现概率最小的两个;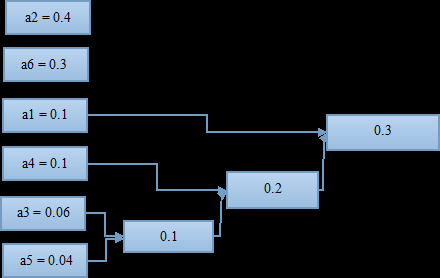
将两个出现概率小的符号再进行一次组合,有得到一个组合概率;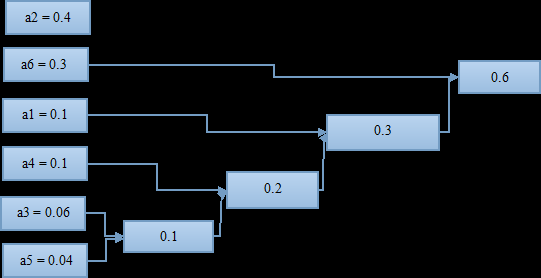
如此进行下去,知道组合到概率为1;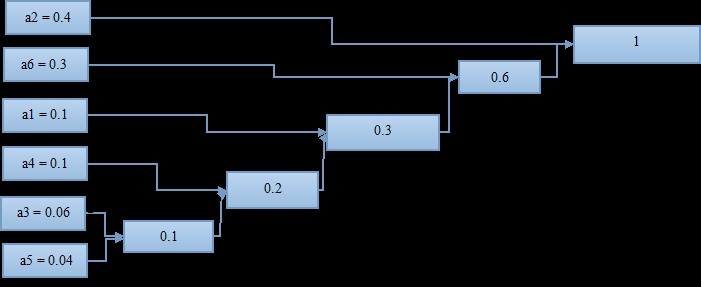
至此,这棵哈夫曼“树”算是画完了,可以进行编码了;
从概率为1(最右)开始,上面分叉编号1,下面分叉编号0(反过来也可以),编号到最左边。
从右到左读数:
a2 = 1;
a6 = 01;
a1 = 001;
a4 = 0001;
a3 = 00001;
a5 = 00000;
哈夫曼编码的一大好处是,它是Prefix-Free的,也就是每个符号之间不加分隔符,解码器也能识别;
对上面6个符号,如果采用统一长度编码,一个符号需要3bit;
用哈夫曼进行编码,
平均码长 = 1*0.4 + 2*0.3 + 3*0.1 + 4*0.1 + 5*0.06 + 5*0.04 = 2.2bit;
压缩比 = 2.2/3=0.7333333333;
如果概率分布更集中,压缩效果更明显。
理论最小平均码长(信息熵)
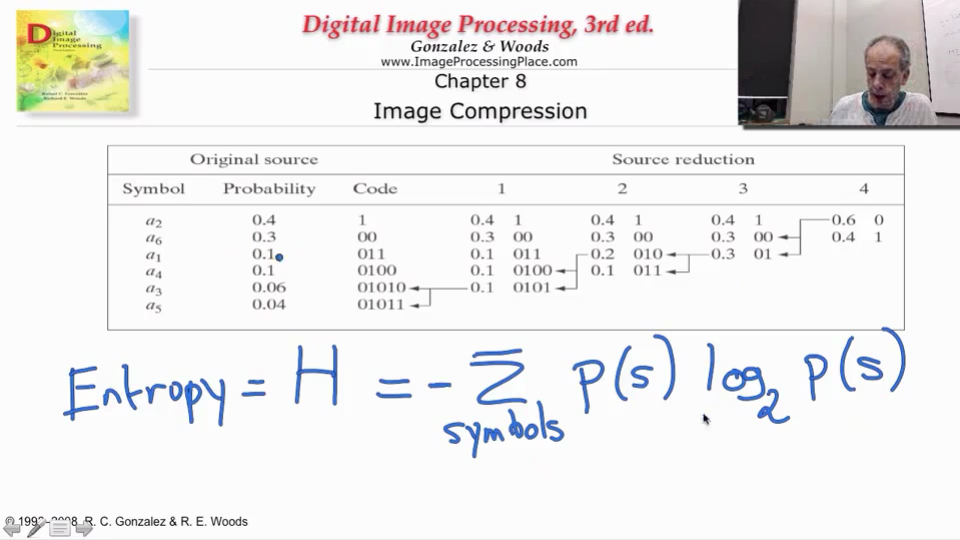
我还依稀记得,香农老人家语重心长地教诲我:哈夫曼编码的最小平均码长,是熵(信息论)。
不过实践经验告诉我,一般哈夫曼编码出来的平均码长,会比这个理论值大那么一丢丢。
三叉Huffman编码方法
经历完上学期的“信息论”考试,我才知道,地球上还存在N叉哈夫曼编码。
一般二叉都会使用二叉哈夫曼编码,也就是用0、1作为分叉。
但考试非要考三叉哈夫曼编码,也就是用0、1、2来进行编码。
方法很简单:方法与二叉Huffman编码一致,如果待编码的符号数不是3的倍数,就自行补上几个“概率为0”的符号,使符号的总个数为3的倍数。
转载:http://mooc.guokr.com/note/5192/
数据压缩之经典——哈夫曼编码(Huffman)的更多相关文章
- 赫夫曼\哈夫曼\霍夫曼编码 (Huffman Tree)
哈夫曼树 给定n个权值作为n的叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离 ...
- 哈夫曼编码(Huffman coding)的那些事,(编码技术介绍和程序实现)
前言 哈夫曼编码(Huffman coding)是一种可变长的前缀码.哈夫曼编码使用的算法是David A. Huffman还是在MIT的学生时提出的,并且在1952年发表了名为<A Metho ...
- 采用霍夫曼编码(Huffman)画出字符串各字符编码的过程并求出各字符编码 --多媒体技术与应用
题目:有一个字符串:cabcedeacacdeddaaaba,问题: (1)采用霍夫曼编码画出编码的过程,并写出各字符的编码 (2)根据求得的编码,求得各编码需要的总位数 (3)求出整个字符串总编码长 ...
- 霍夫曼编码(Huffman)
题目:有一个字符串:cabcedeacacdeddaaaba,问题: (1)采用霍夫曼编码画出编码的过程,并写出各字符的编码 (2)根据求得的编码,求得各编码需要的总位数 (3)求出整个字符串总编码长 ...
- Python 算法(2) 哈夫曼编码 Huffman Encoding
这个问题原始是用来实现一个可变长度的编码问题,但可以总结成这样一个问题,假设我们有很多的叶子节点,每个节点都有一个权值w(可以是任何有意义的数值,比如它出现的概率),我们要用这些叶子节点构造一棵树,那 ...
- 哈夫曼编码的理解(Huffman Coding)
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,可变字长编码(VLC)的一种.Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最 ...
- 霍夫曼编码(Huffman Coding)
霍夫曼编码(Huffman Coding)是一种编码方法,霍夫曼编码是可变字长编码(VLC)的一种. 霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符 ...
- Java 树结构实际应用 二(哈夫曼树和哈夫曼编码)
赫夫曼树 1 基本介绍 1) 给定 n 个权值作为 n 个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为 最优二叉树,也称为哈夫曼树(Huffman Tree), ...
- HDU2527 哈夫曼编码
Safe Or Unsafe Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
随机推荐
- 日期控件 DatePicker 在ie8不能用
过个年,日期控件DatePicker在ie8下突然不能用了,程序也没升级,很是奇怪. 把ie8的“禁用脚本调试”去掉,再次运行,发现提示有脚本错误. 想着可能是兼容性问题,于是把兼容性视图打开运行,还 ...
- URLEncoder.encode转译后“空格”变“加号”的问题的解决方案
我用dst_fname=URLEncoder.encode(dst_fname);对字符串dst_fname进行编码,但是发现空格全部都变成了加号,我们提需求的傻B非得要空格的,但是不编码有很多非常特 ...
- iOS.KVC.setValue:forKey:
Foundation Framework 定义了 NSObject(NSKeyValueCoding), - (void)setValue:(id)value forKey:(NSString *)k ...
- java byte转string 涉及到字节流中有中文
最近遇到一个问题,我用java写了一个客户端通过socket向服务器端发送消息,发送的内容是字节流,编码格式是GBK,服务器在收到消息后,如果格式正确,会返回固定的消息格式,同样也是字节流,编码格式也 ...
- SQL Server 2008重新保存表时出错
在使用SQL Server 2008时,修改了表的字段名和类型名之后,点击保存按钮之后出现如下对话框:
- 来看看N多设计师笔下的Spider Man
很多电影在大获成功后,其中的人物都成了火热的IP,漫威的各类超级英雄就是个很好的例子,今天突发奇想看看各种漫画人物在插画师手中同一人物会有什么样的不同,所以以蜘蛛侠为主题,搜集了很多插画师笔下的蜘蛛侠 ...
- python Trie树和双数组TRIE树的实现. 拥有3个功能:插入,删除,给前缀智能找到所有能匹配的单词
#coding=utf- #字典嵌套牛逼,别人写的,这样每一层非常多的东西,搜索就快了,树高26.所以整体搜索一个不关多大的单词表 #还是O(). ''' Python 字典 setdefault() ...
- fastcgi vc6.0demo
#include <WinSock2.h> #include <stdio.h> #pragma comment(lib, "ws2_32.lib") ty ...
- ContactDetail 和 ContactEditor 界面头像响应点击过程
1,联系人详情界面 ContactDetailFragment中处理,ViewAdapter装载数据显示头像 private final class ViewAdapter extends BaseA ...
- 使用yarn 安装 Vue-DevTools
1. 从 github 下载 vuejs/vue-devtools https://github.com/vuejs/vue-devtools/archive/dev.zip 2.安装yarn 及 编 ...