StreamSets学习系列之StreamSets的Core Tarball方式安装(图文详解)
不多说,直接上干货!
前期博客
StreamSets学习系列之StreamSets支持多种安装方式【Core Tarball、Cloudera Parcel 、Full Tarball 、Full RPM 、Docker Image和Source Code 】(图文详解)

核心安装包(Core Tarball)
该安装包包含核心的SDC软件,使该软件具有最小的软件连接器集合,当然你可以手动下载额外的节点(Stage)
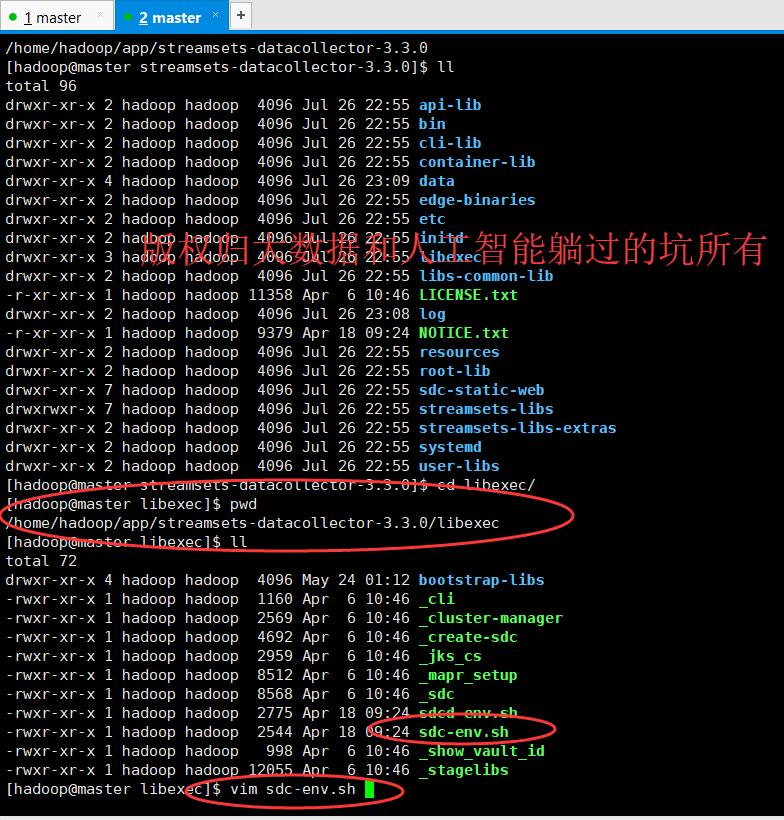
① 通过Streamsets的UI进行安装,UI上点击的位置为:在该软件界面的右边(图标是一个礼物盒子。。。)。
② 也可以通过使用CLI进行安装,安装过程如下所示:
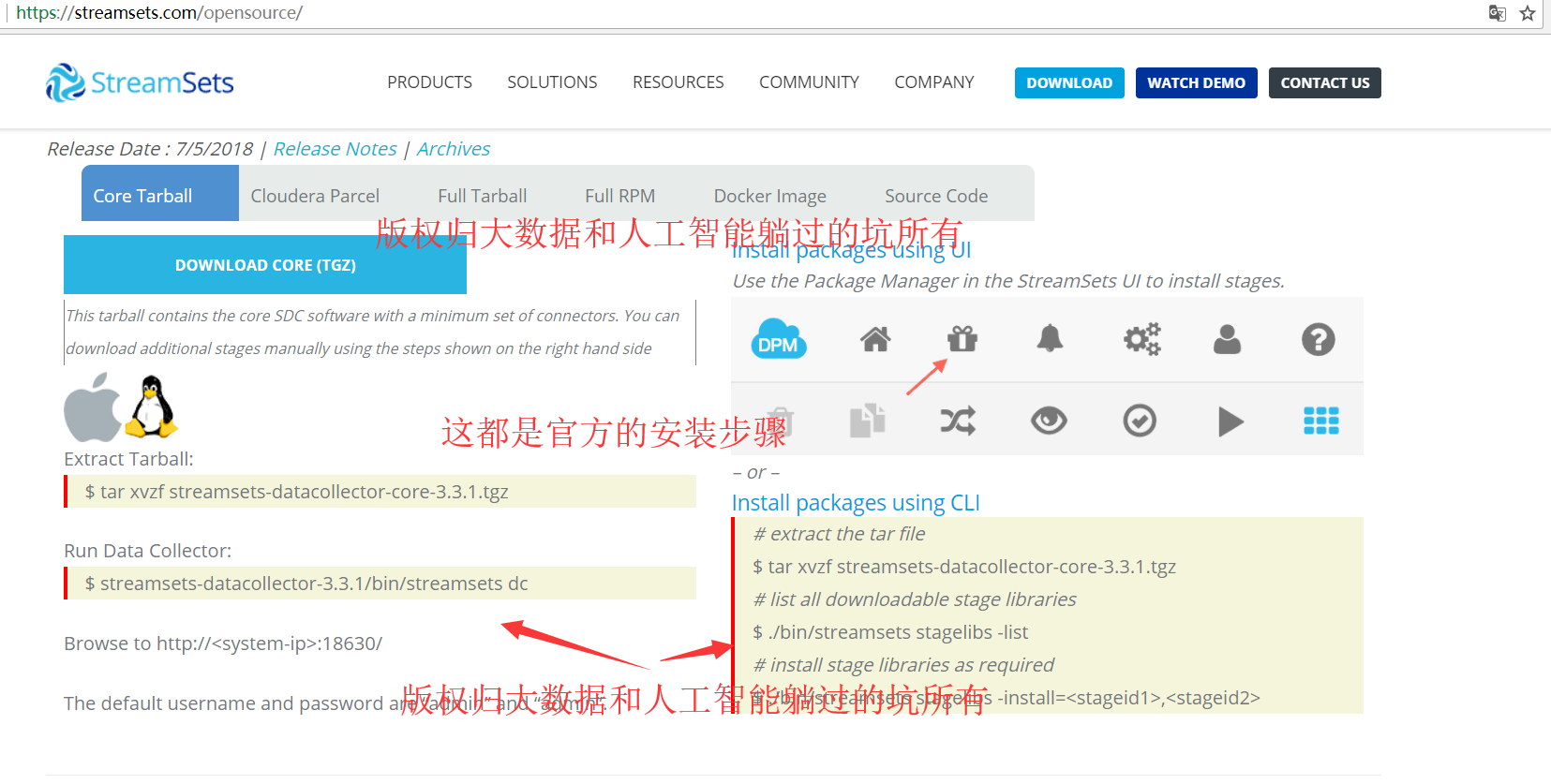
第一步、下载该【核心安装包】,比如版本为:streamsets-datacollector-core-3.3.0.tgz


第二步、解压该安装包
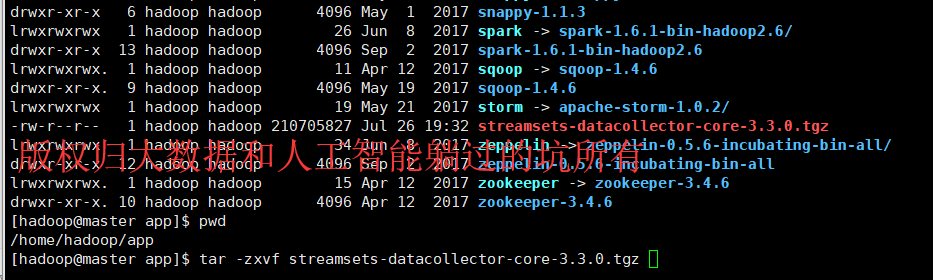
[hadoop@master app]$ tar -zxvf streamsets-datacollector-core-3.3..tgz

[hadoop@master streamsets-datacollector-3.3.]$ ./bin/streamsets dc
Java 1.8 detected; adding $SDC_JAVA8_OPTS of "-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144" to $SDC_JAVA_OPTS
Configuration of maximum open file limit is too low: (expected at least ). Please consult https://goo.gl/LgvGFl
[hadoop@master streamsets-datacollector-3.3.]$
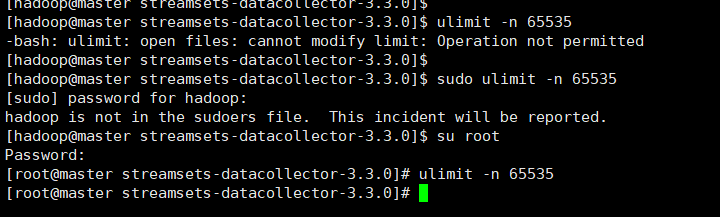
注:在这个启动的过程中会出现启动报错的情况,错误提示是:最大的文件数为1024,而streamsets需要更大的文件数,因此就要必要的设置一下环境了。
设置方式有两种:
(1)修改配置文件,然后重启centos永久生效,
(2)通过一个命令进行生效:
ulimit -n Browse to http://<system-ip>:18630/ The default username and password are “admin” and “admin”.

[hadoop@master streamsets-datacollector-3.3.]$ pwd
/home/hadoop/app/streamsets-datacollector-3.3.
[hadoop@master streamsets-datacollector-3.3.]$ ./bin/streamsets dc
Java 1.8 detected; adding $SDC_JAVA8_OPTS of "-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144" to $SDC_JAVA_OPTS
Logging initialized @6514ms to org.eclipse.jetty.util.log.Slf4jLog
Running on URI : 'http://master:18630'
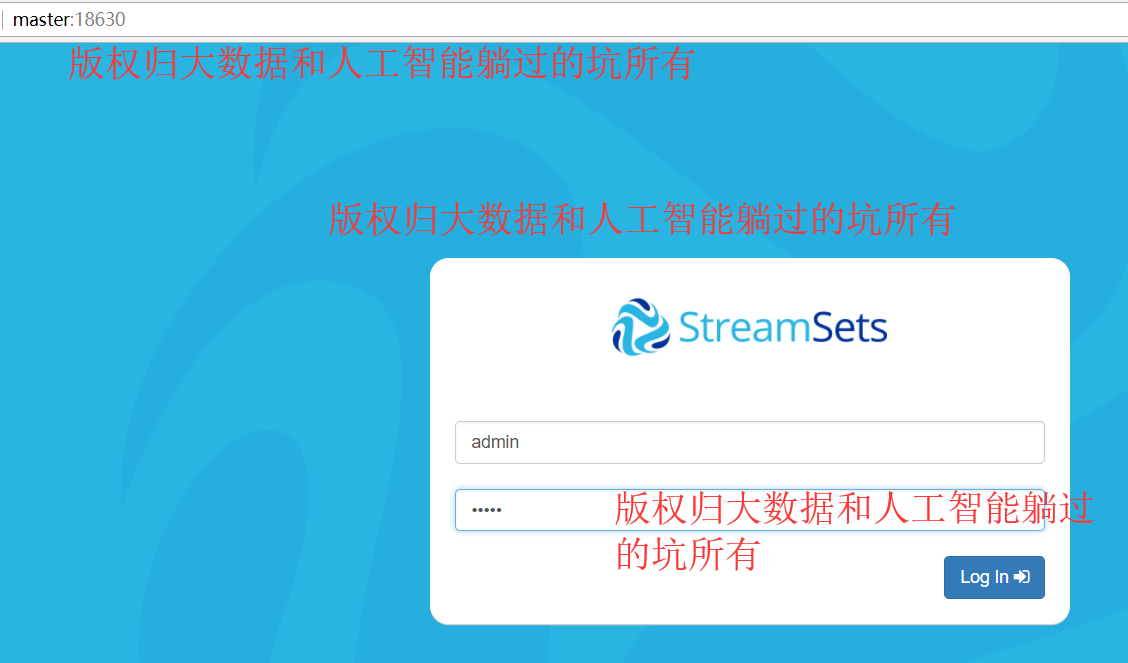
通过这种方式:你就可以看到正真的streamsets真面目了。。。。后面我们看看他真面目里面的一些细节。。。。这个工具主要进行数据移动及数据清洗有很大的帮助。
或者

[hadoop@master streamsets-datacollector-3.3.]$ pwd
/home/hadoop/app/streamsets-datacollector-3.3.
[hadoop@master streamsets-datacollector-3.3.]$ nohup /home/hadoop/app/streamsets-datacollector-3.3./bin/streamsets dc &
[]
[hadoop@master streamsets-da
也许,你在启动过程中,会出现
StreamSets学习系列之启动StreamSets时出现Caused by: java.security.AccessControlException: access denied ("java.util.PropertyPermission" "test.to.ensure.security.is.configured.correctly" "read")错误的解决办法
安装成功的后续步骤(建议去做):
1、添加sdc用户的进程操作文件描述符的并行度
[root@master streamsets-datacollector-3.3.]# vim /etc/security/limits.conf
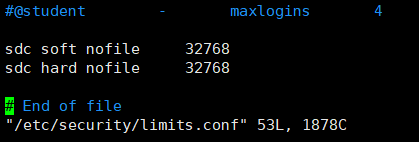
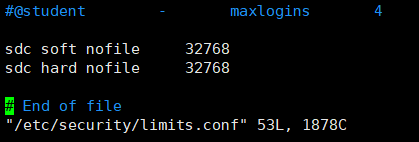
sdc soft nofile
sdc hard nofile
2、vim /etc/profile
[root@master streamsets-datacollector-3.3.]# vim /etc/profile
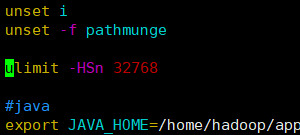
[root@master streamsets-datacollector-3.3.]# source /etc/profile
3、创建文件目录,用于放日志信息
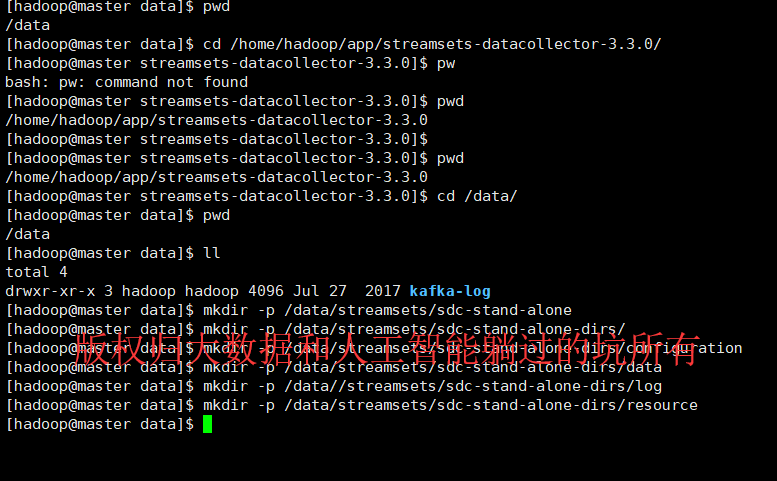
[root@master data]# su hadoop
[hadoop@master data]$ pwd
/data
[hadoop@master data]$ cd /home/hadoop/app/streamsets-datacollector-3.3./
[hadoop@master streamsets-datacollector-3.3.]$ pw
bash: pw: command not found
[hadoop@master streamsets-datacollector-3.3.]$ pwd
/home/hadoop/app/streamsets-datacollector-3.3.
[hadoop@master streamsets-datacollector-3.3.]$
[hadoop@master streamsets-datacollector-3.3.]$ pwd
/home/hadoop/app/streamsets-datacollector-3.3.
[hadoop@master streamsets-datacollector-3.3.]$ cd /data/
[hadoop@master data]$ pwd
/data
[hadoop@master data]$ ll
total
drwxr-xr-x hadoop hadoop Jul kafka-log
[hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone
[hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/
[hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/configuration
[hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/data
[hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/log
[hadoop@master data]$ mkdir -p /data/streamsets/sdc-stand-alone-dirs/resource
[hadoop@master data]$
修改配置文件
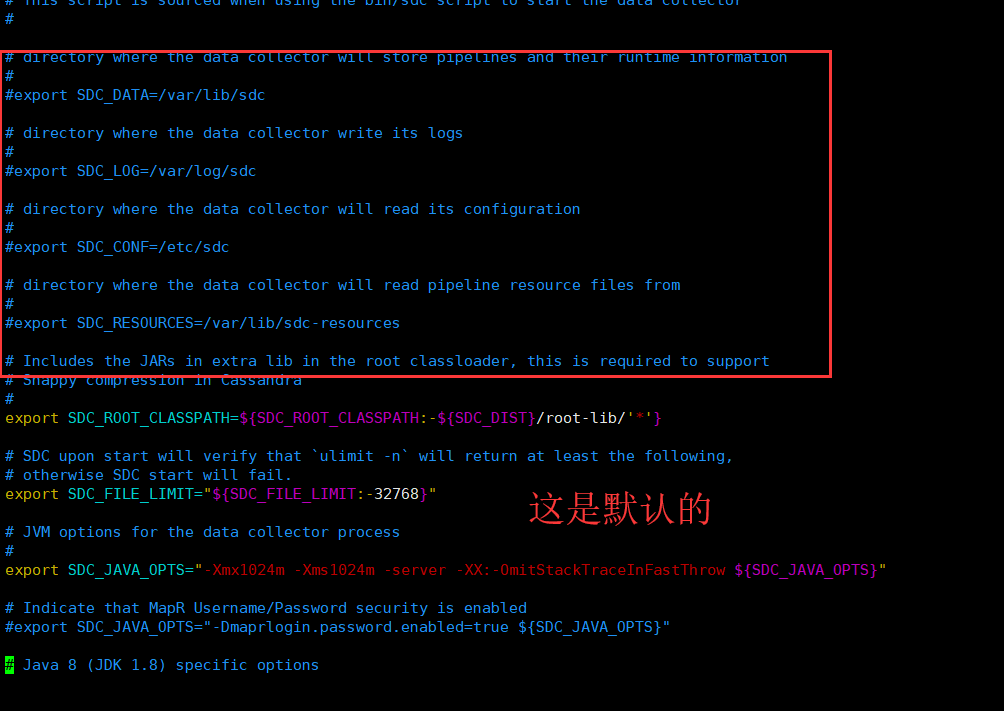
# directory where the data collector will store pipelines and their runtime information
#
#export SDC_DATA=/var/lib/sdc # directory where the data collector write its logs
#
#export SDC_LOG=/var/log/sdc # directory where the data collector will read its configuration
#
#export SDC_CONF=/etc/sdc # directory where the data collector will read pipeline resource files from
#
#export SDC_RESOURCES=/var/lib/sdc-resources
改为
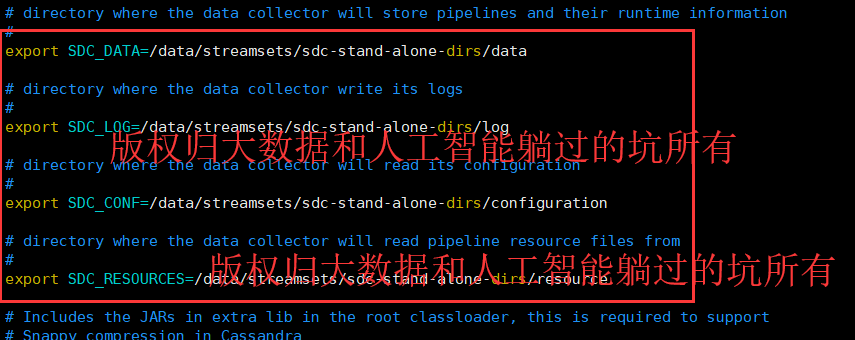
# directory where the data collector will store pipelines and their runtime information
#
export SDC_DATA=/data/streamsets/sdc-stand-alone-dirs/data # directory where the data collector write its logs
#
export SDC_LOG=/data/streamsets/sdc-stand-alone-dirs/log # directory where the data collector will read its configuration
#
export SDC_CONF=/data/streamsets/sdc-stand-alone-dirs/configuration # directory where the data collector will read pipeline resource files from
#
export SDC_RESOURCES=/data/streamsets/sdc-stand-alone-dirs/resource
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



StreamSets学习系列之StreamSets的Core Tarball方式安装(图文详解)的更多相关文章
- TortoiseGit学习系列之TortoiseGit基本操作拉取项目(图文详解)
前面博客 TortoiseGit学习系列之TortoiseGit基本操作克隆项目(图文详解) TortoiseGit学习系列之TortoiseGit基本操作修改提交项目(图文详解) TortoiseG ...
- Git学习系列之Git基本操作拉取项目(图文详解)
前面博客 Git学习系列之Git基本操作推送项目(图文详解) 当然,如果多人协作,或者多个客户端进行修改,那么我们还要拉取(Pull ... )别人推送到在线仓库的内容下来. 大神们是不推荐使用 pu ...
- TortoiseGit学习系列之TortoiseGit基本操作修改提交项目(图文详解)
前面博客 TortoiseGit学习系列之TortoiseGit基本操作克隆项目(图文详解) TortoiseGit基本操作修改提交项目 项目克隆完成后(可以将克隆 clone 理解为 下载,检出 c ...
- Git学习系列之Git基本操作推送项目(图文详解)
前面博客 Git学习系列之Git基本操作提交项目(图文详解) 如果完成到一定程度,那么可以推送到远端在线仓库. 推送之前,请确保你已经设置了全局的 user.name 和 user.email, 如果 ...
- SPSS学习系列之SPSS Statistics的菜单栏介绍(图文详解)
不多说,直接上干货! 以下是菜单栏 1.以下是文件栏: 2.以下是编辑栏 3.以下是查看栏 4.以下是数据栏: 5.以下是转换栏: 6.以下是分析栏: 7.以下是直销栏: 8.以下是图形栏: 9. ...
- StreamSets学习系列之StreamSets的集群安装(图文详解)
不多说,直接上干货! 若是集群安装 需要在对应节点执行相同的操作. 见 StreamSets学习系列之StreamSets支持多种安装方式[Core Tarball.Cloudera Parcel . ...
- StreamSets学习系列之StreamSets的Create New Pipeline(图文详解)
不多说,直接上干货! 前期博客 StreamSets学习系列之StreamSets支持多种安装方式[Core Tarball.Cloudera Parcel .Full Tarball .Full R ...
- Python操作redis学习系列之(集合)set,redis set详解 (六)
# -*- coding: utf-8 -*- import redis r = redis.Redis(host=") 1. Sadd 命令将一个或多个成员元素加入到集合中,已经存在于集合 ...
- 反射实现Model修改前后的内容对比 【API调用】腾讯云短信 Windows操作系统下Redis服务安装图文详解 Redis入门学习
反射实现Model修改前后的内容对比 在开发过程中,我们会遇到这样一个问题,编辑了一个对象之后,我们想要把这个对象修改了哪些内容保存下来,以便将来查看和追责. 首先我们要创建一个User类 1 p ...
随机推荐
- js点击空白处触发事件
我们经常会出现点击空白处关闭弹出框或触发事件 <div class="aa" style="width: 200px;height: 200px;backgroun ...
- 1.9yield方法
yield()方法的作用放弃当前的cpu资源,将他让给其他的任务去占用cpu的执行时间,但放弃的时间不确定,有可能刚放弃,马上又获得cpu时间片 测试 package com.cky.thread; ...
- rhel5.4+oracle 10g rac
各种报错各种愁啊 ... 1> 不知道什么原因,在节点2执行root.sh 报错 .无解 . 还原虚拟机,重新安装 .唯一与以前不同的是,执行orainroot.sh后 接着在节点2执行.再去分 ...
- spring boot jpa 多条件组合查询带分页的案例
spring data jpa 是一个封装了hebernate的dao框架,用于单表操作特别的方便,当然也支持多表,只不过要写sql.对于单表操作,jpake可以通过各种api进行搞定,下面是一个对一 ...
- 关于Linux学习中的问题和体会
本科期间未开展过与之相关的课程,所以初次接触Linux难免有些问题!参照老师给的学习资料中内容,逐步解决了一些问题,但还有一些问题没解决,下面列举出自己遇到的一些问题. 1.在环境变量与文件查找专题中 ...
- redis简单使用
主要参考资料:http://wiki.jikexueyuan.com/project/redis-guide/data-type.html一.redis 安装1.在官网下载安装包2.解压安装包 tar ...
- vc6中向vs2010迁移的几个问题(2)
1. 库文件的迁移 参考:http://www.cnblogs.com/icmzn/p/6724969.html 2. 其他项目中的可能遇到的问题: 2.1 无法打开包括文件:“fstream.h”: ...
- hdu 4542 打表+含k个约数最小数
http://acm.hdu.edu.cn/showproblem.php?pid=4542 给出一个数K和两个操作 如果操作是0,就求出一个最小的正整数X,满足X的约数个数为K. 如果操作是1,就求 ...
- python之基础1
一.python介绍 介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,Guido开始写能够解释Python语言语法的解释器.Python这个名字 ...
- WPF如何设置Image.Source为资源图片
img.Source = new BitmapImage(new Uri(path,UriKind.RelativeOrAbsolute));