python 网络爬虫requests模块
一、requests模块
requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。
1.1 模块介绍及请求过程
requests模块模拟浏览器发送请求
请求流程:指定url --> 发起请求 --> 获取响应对象中存储的数据 --> 持久化存储
1.2 爬取百度首页
#!/usr/bin/env python
# -*- coding:utf-8-*- import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://www.baidu.com/' response = requests.get(url=url)
response.encoding = 'utf-8' # 修改字符编码
page_text = response.text # 获取的类型为字符型<class 'str'> with open('./baidu.html', mode='w', encoding='utf-8') as f:
f.write(page_text) # page_text = response.content # 返回二进制数据类型 <class 'bytes'>
# response.status_code # 获取响应状态码
# response.headers['Content-Type'] == 'text/json' # 类型是 'text/json' 则可以使用response.json方法
# response.json # 如果响应头中存储了json数据,该方法可以返回json数据
1.3 爬取百度指定词条搜索后的页面数据
#!/usr/bin/env python
# -*- coding:utf-8-*-
import requests headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&'
kw = input('请输入要搜索的内容:')
param = {'wd': kw}
response = requests.get(url=url, params=param, headers=headers) page_text = response.content
fileName = kw+'.html'
with open(fileName, 'wb') as fp:
fp.write(page_text)
print(fileName+'爬取成功。')
1.4 获取百度翻译的翻译结果使用post方法
页面使用的ajax的请求方式,通过浏览器抓包得到请求的地址和提交From表单的内容。

#!/usr/bin/env python
# -*- coding:utf-8-*- import requests headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://fanyi.baidu.com/sug' kw = input('请输入要翻译的内容:')
data = {
'kw': kw
}
response = requests.post(url=url, data=data, headers=headers)
dic = response.json()
print(dic['data'])
-----------------------------------执行结果--------------------------------------
请输入要翻译的内容:美女
[{'k': '美女', 'v': '[měi nǚ] beauty; belle; beautiful woman; femme fat'}, {'k': '美女与野兽', 'v': '名 Beauty and the Beast;'}, {'k': '美女蛇', 'v': 'merino;'}]
--------------------------------------------------------------------------------
1.5 爬取豆瓣电影排名电影
#!/usr/bin/env python
# -*- coding:utf-8-*- import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
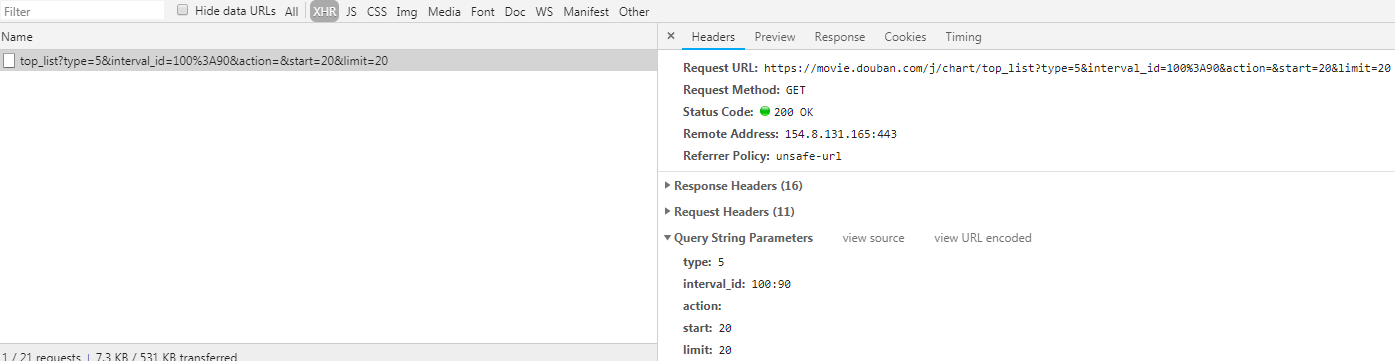
} url = 'https://movie.douban.com/j/chart/top_list' param = {
'type': '',
'interval_id': '100:90',
'action': '',
'start': '',
'limit': ''
} json_data = requests.get(url=url, headers=headers, params=param).json() print(json_data)
python 网络爬虫requests模块的更多相关文章
- Python网络爬虫-requests模块
requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在爬虫领域中占据着半壁江山的地位. 如何使用reques ...
- Python网络爬虫-requests模块(II)
有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/env ...
- python网络编程----requests模块
python访问网站可以用标准模块--urllib模块(这里省略),和requests(安装-pip install requests)模块,requests模块是在urllib的基础上进行的封装,比 ...
- 06 Python网络爬虫requets模块高级用法
一. 基于requests模块的cookie操作 - cookie概念: 当用户通过浏览器访问一个域名的时候,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就 ...
- Python网络爬虫-xpath模块
一.正解解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- Python网络爬虫:空姐网、糗百、xxx结果图与源码
如前面所述,我们上手写了空姐网爬虫,糗百爬虫,先放一下传送门: Python网络爬虫requests.bs4爬取空姐网图片Python爬虫框架Scrapy之爬取糗事百科大量段子数据Python爬虫框架 ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
- 《实战Python网络爬虫》- 感想
端午节假期过了,之前一直在做出行准备,后面旅游完又休息了一下,最近才恢复状态. 端午假期最后一天收到一个快递,回去打开,发现是微信抽奖中的一本书,黄永祥的<实战Python网络爬虫>. 去 ...
随机推荐
- 美图DPOS以太坊教程(Docker版)
一.前言 最近,需要接触区块链项目的主链开发,在EOS.BTC.ethereum.超级账本这几种区块链技术当中,相互对比后,最终还是以go-ethereum为解决方案. 以ethereum为基准去找解 ...
- 前端开发使用Photoshop切图详细步骤
切图的主要目的是从设计师提供的psd中获取网页制作所要的资源 一.界面设置 1. 新建文件,调整界面大小,背景设置为透明 2. 自动选择,把组切换为图层 3. 添加窗口内容,一共四项:图层.历史纪录. ...
- c# 通过GroupBy 进行分组
有时候我们需要数据根据一些字段进行分组,这时候用orderBy很方便.不多说了.直接上代码: class Ma { public int number { get; set; } public str ...
- SELECT查询结果集INSERT到数据表
简介 将查询语句查询的结果集作为数据插入到数据表中. 一.通过INSERT SELECT语句形式向表中添加数据 例如,创建一张新表AddressList来存储班级学生的通讯录信息,然后这些信息恰好存在 ...
- Go 在 TiDB 的实践
https://blog.csdn.net/RA681t58CJxsgCkJ31/article/details/79215751 更多TiDB链接: https://my.oschina.net/z ...
- python3.6和pip3安装
CenOS7 安装依赖环境 yum -y install openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc 编译 ...
- Mysql查询缓存Query_cache的功用
MySQL的查询缓存并非缓存执行计划,而是查询及其结果集,这就意味着只有相同的查询操作才能命中缓存,因此MySQL的查询缓存命中率很低,另一方面,对于大结果集的查询,其查询结果可以从cache中直接读 ...
- MongoDB之 复制集搭建
MongoDB复制集搭建步骤,本次搭建使用3台机器,一个是主节点,一个是从节点,一个是仲裁者. 主节点负责与前台客户端进行数据读写交互,从节点只负责容灾,构建高可用,冗余备份.仲裁者的作用是当主节点宕 ...
- 自定义上传控件(兼容IE8)
上传控件是 <input type="file"/> 而实际开发过程中,都会自定义一个控件,因为这个控件本身难看,而且不同浏览器效果不一样. 如IE8显示如下: 谷歌浏 ...
- 1001.A+B Format(10)
1001.A+B Format(20) github链接:[example link](https://github.com/wgc12/object-oriented 1.对题目的理解: 首先这道题 ...