kudu 存储引擎简析
本文由 网易云发布。
1 概述
本文主要介绍kudu底层存储引擎的数据组织方式,先看整体结构如下:

一张表会分成若干个tablet , 每个tablet 包括MetaData 元信息及若干个RowSet , RowSet 包含一个MemRowSet 及若干个DiskRowSet , DiskRowSet 中 包 含 一 个 BloomFile 、 Ad_hoc Index 、 BaseData 、 DeltaMem 及 若 干 个 RedoFile 和UndoFile(UndoFile一般情况下只有一个)。
MemRowSet用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。
DiskRowSet用于老数据的mutation,后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
BloomFile根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中存在。Ad_hoc Index是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。
BaseData 是 MemRowSet flush 下 来 的 数 据 , 按 列 存 储 , 按 主 键 有 序 。UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。RedoFile是基于BaseData之后时间的mutation记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。DeltaMem用于DiskRowSet中数据的mutation,先写到内存中,写满后flush到磁盘形成RedoFile。
2 MemRowSet
MemRowSet的数据组织形式是一颗B+Tree,结构如下:
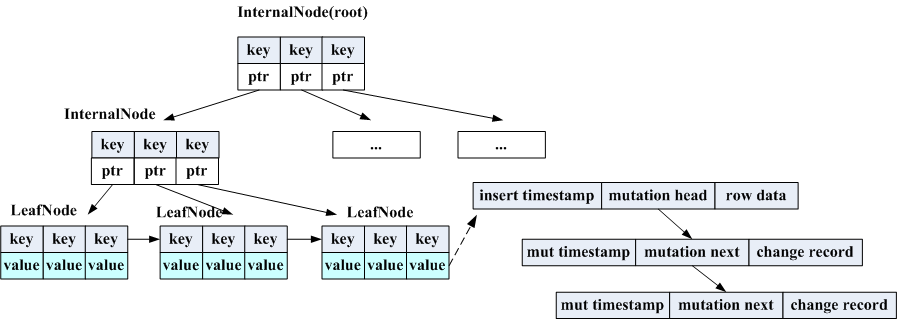
这颗B+树实现的比较简单,因为它没有update跟delete操作,kudu在MemRowSet中中数据的mutation采用类似append log 方式,在base数据上有个mutation指针,所有的后续mutation操作都挂在这个指针上了。
虽然只有插入,但是也会出现节点满时需要做split,同时可能有读操作也在同步进行,kudu使用AtomicVersion(原子变量+位移)实现了一个锁。树的度跟cpu的CACHELINE_SIZE有关,是为了让一个节点仅读取一次cpu cache。
树的检索是先找到key所在的LeafNode,然后在LeafNode内部进行二分查找,LeafNode间有指针进行串联,为了方便scan,扫整个MemRowSet一般通过一个空串的key找到第一个LeafNode,然后依次读数据。
3 DiskRowSet
这部分是kudu存储部分最复杂的东西,分为两个部分来讲,DiskRowSet间的组织,DiskRowSet内数据组织,先看DiskRowSet 间怎么组织的。
3.1 DiskRowSet间组织
一个tablet随这数据的不断写入会包含很多个DiskRowSet,每个DiskRowSet上有min_key、max_key标明key的范围,如果要查找一个key在哪个DiskRowSet上依次遍历每个DiskRowSet效率是很低的,这种情况线段树这种数据结构是很适合做range索引的,将所有的DiskRowSet形成一颗线段树,结构如下:

其实就是一个二叉平衡树,每次从所有range(最小的min_key跟最大的max_key)的中间key做split,将range跨域左右子树的
DiskRowSet(即split point落在DiskRowSet的min_key与max_key之间)放到overlap rowsets中去。这颗树实现的也很简单, 因为它只做查询用,生成后就不会变动,若遇到MemRowSet flush或DiskRowSet Merge Compaction就直接重新生成一颗新树。
这个树主要用于在读或写的时候定位某个或若干个key 在哪些DiskRowSet 的range 范围内, 只能通过DiskRowSet 的min_key/max_key做一层模糊过滤,是否正在存在需要做进一步检查。
3.2 DiskRowSet内数据组织
一个DiskRowSet大体数据组织上面概述中已介绍过,其中DeltaMem跟MemRowSet在内存中的组织方式是一样的,都是B+Tree,而在磁盘上的存储都是放在CFile中的,下面我们看看CFile的文件格式:

CFile包含Header、Data、Index、Footer几块,其中Data部分起始部分是为空值的条目建立的bitmap,仅针对可为null的
column,对于主键是没有这个的,bitmap就是以那些值为null的RowId建立起来的位图,这样Data中就不用存这些空值。data部分不同的column类型文件会有不同的编码方式:
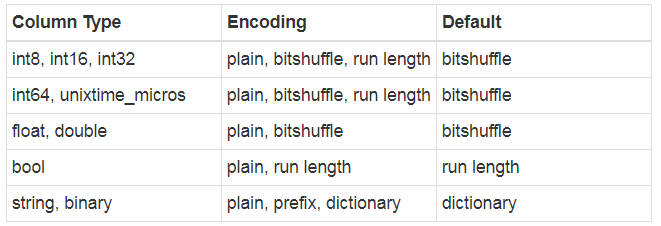
对于ad_hoc文件使用的是prefix,delta file使用的是plain,bloomfile使用的是plain。每种BlockBuilder在处理一定量数据后就会append到Data中。
Index有两种,posidx_index是根据RowId找到在Data中的偏移,validx index是根据key的值找到在Data中的偏移,validx只针对只有一个column为key的情况,这个时候DiskRowSet没有Ad_hoc索引,使用validex来代替。这两个index内部实现是一个B- Tree,index不一定是连续的,在达到一定长度后就会刷盘,而内部可以区分是中间节点还是叶子节点及其孩子节点的位置。
Footer是记录了CFile的元信息,包括posidx_index、validx_index两棵树根节点所在位置,数据条目、编码、压缩方式等。下面看看DiskRowSet数据在磁盘上的分布:

在磁盘上每个DiskRowSet有若干个***.metadata及***.data文件,metadata文件记录的是DiskRowSet的元信息,主要包括哪些block及block在data中的位置,上图为block与DiskRowSet中各部分的映射关系,在写磁盘是通过container来写,每个container 可以写很大一块连续的磁盘空间, 用于给某个CFile写数据, 当一个CFile写完后会将container归还给BlockManager, 这时container就可以用于下个CFile写数据了,当BlockManager中没有container可用时会新建一个container给新来的CFile使用。
对于新建block先看看有无container可用,若没有目前默认是在所有配置中的data_dir中随机选取一个dir中建一个新的metadata 及data文件。先写data,block落盘后再写metadata。
对于kudu底层数据存储就介绍到这里,希望对大家有所帮助。
想要了解网易大数据,请戳这里网易大数据|专业的私有化大数据平台
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/
kudu 存储引擎简析的更多相关文章
- mysql存储引擎简析
一.常见存储引擎特性 Innodb 具有提交.回滚和崩溃恢复能力的事务安全.支持外键.使用mvcc以及行锁来提供事务支持,因此支持高并发.适用于写频繁,并发率高的应用. Myisam 不支持事务和灾难 ...
- mysql memory存储引擎简单测试
Auth: jin Date: 20140423 mysql> CREATE TABLE `t4` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` ...
- SpringMVC源码情操陶冶-DispatcherServlet简析(二)
承接前文SpringMVC源码情操陶冶-DispatcherServlet类简析(一),主要讲述初始化的操作,本文将简单介绍springmvc如何处理请求 DispatcherServlet#doDi ...
- information_schema系列二(列,列权限,事件,存储引擎)
这个系列的文章主要是为了能够让自己了解MySQL5.7的一些系统表,统一做一下备注和使用,也希望分享出来让大家能够有一点点的受益. 1:COLUMNS 老规矩.查一下这个表,看一下记录,由于这个是看表 ...
- PHP的错误报错级别设置原理简析
原理简析 摘录php.ini文件的默认配置(php5.4): ; Common Values: ; E_ALL (Show all errors, warnings and notices inclu ...
- 第 3 章 MySQL 存储引擎简介
第 3 章 MySQL 存储引擎简介 前言 3.1 MySQL 存储引擎概述 MyISAM 存储引擎是 MySQL 默认的存储引擎,也是目前 MySQL 使用最为广泛的存储引擎之一.他的前身就是我们在 ...
- 转mysql存储引擎memory,ndb,innodb之选择
1 mysql的innodb和cluster的NDB引擎都支持事务,在有共同的特性外,也有不同之处:以mysql cluster NDB 7.3和MySQL 5.6之InnoDB为例:ndb7.3基于 ...
- Java Annotation 及几个常用开源项目注解原理简析
PDF 版: Java Annotation.pdf, PPT 版:Java Annotation.pptx, Keynote 版:Java Annotation.key 一.Annotation 示 ...
- Kudu存储实战笔记
有人会问,为啥要用这个叫啥Kudu的,Kudu是啥? 就像官网所说,Kudu是一个针对Apache hadoop 平台而开发的列式存储管理器,在本菜鸟看来,它是一种介于hdfs与hbase的一种存储. ...
随机推荐
- Java-Swing常用布局管理器
http://www.cnblogs.com/hthuang/p/3460234.html 5.Java-Swing常用布局管理器 应用布局管理器都属于相对布局,各组件位置可随界面大小 ...
- 乘风破浪:LeetCode真题_025_Reverse Nodes in k-Group
乘风破浪:LeetCode真题_025_Reverse Nodes in k-Group 一.前言 将一个链表按照一定的长度切成几部分,然后每部分进行翻转以后再拼接成一个链表是比较困难的,但是这也能锻 ...
- November 14th, 2017 Week 46th Tuesday
Eternity is said not to be an extension of time but an absence of time. 永恒不是时间的无限延伸,而是没有时间. What is ...
- Eclipse 插件安装报错问题(已解决)
错误信息提示: An error occurred while installing the items session context was:(profile=epp.package.jee, p ...
- saltstack二次开发(三)
以下代码实现的功能: 通过saltstack的httpapi在minion上安装软件. vim saltapi.py #!/usr/bin/env python # -*- coding: utf-8 ...
- Arcgis创建SDE_Geometry、SDO_Geometry的区别
先初略的了解下SDE_Geometry和SDO_Geometry的区别: 1. SDO_GEOMETRY Oracle Spatial在MDSYS模式下定义了一系列几何类型.函数来支持空间数据的存储和 ...
- AnyHashable类型擦除的原因:set和dictory需要指定一个确定的类型
AnyHashable 属于无关联类型的擦除. 将具体类型的类型信息擦除掉了,只剩下协议类型的信息暴露出来. 类型擦除实践:将相同协议的不同实现屏蔽起来,暴露出类型的共同特征(协议接口). A typ ...
- OpenCV——漫水填充
- Python2.7-collections
collections 模块主要提供了五种特殊类型容器,此外还提供了许多抽象基类用于检查类的接口 1.Counter 对象,主要用于统计出现次数,是dict的一个子类,用法与形式和 dict 很类似 ...
- 用python2.7.9 写个小程序搜索某个目录下行有某关键字
# -*- coding: utf-8 -*-import sysreload(sys)sys.setdefaultencoding("utf-8")import os def p ...