hadoop之 Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
(1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
(2)、在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
HDFS的高可用性将通过在同一个集群中运行两个NN(active NN & standby NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集群中,通常有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态。
为了提供快速的故障恢复,Standby NN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的Database将配置好Active NN和Standby NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
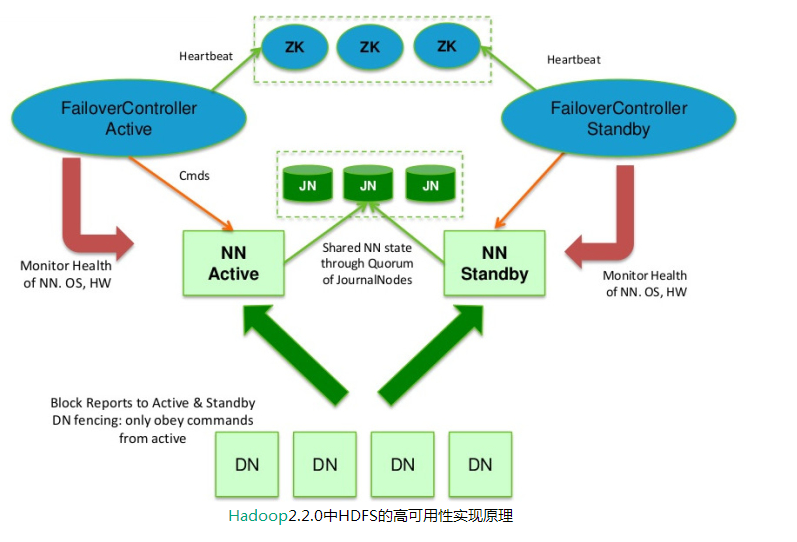
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态。
为了部署HA集群,你需要准备以下事项:
(1)、NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
source : https://www.iteblog.com/archives/833.html#comments
hadoop之 Hadoop2.2.0中HDFS的高可用性实现原理的更多相关文章
- [置顶] Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障 ...
- Hadoop-2.4.0中HDFS文件块大小默认为128M
134217728 / 1024 = 131072 / 1024 = 128
- Hadoop-2.2.0中文文档—— 从Hadoop 1.x 迁移至 Hadoop 2.x
简单介绍 本文档对从 Apache Hadoop 1.x 迁移他们的Apache Hadoop MapReduce 应用到 Apache Hadoop 2.x 的用户提供了一些信息. 在 Apache ...
- Hadoop-2.2.0中文文档——MapReduce 下一代 -——集群配置
目的 这份文档描写叙述了怎样安装.配置和管理从几个节点到有数千个节点的Hadoop集群. 玩的话,你可能想先在单机上安装.(看单节点配置). 准备 从Apache镜像上下载一个Hadoop的稳定版本号 ...
- hadoop2.6.0中自定义分割符
最近在学习hadoop,用的hadoop2.6.0 然后在学习编写mapreduce程序时,发现默认对文件的输入是采用每行进行分割,下面来分析下改变这个分割方式的办法: 来看看默认是怎样实现的:
- Hadoop2.6.0的FileInputFormat的任务切分原理分析(即如何控制FileInputFormat的map任务数量)
前言 首先确保已经搭建好Hadoop集群环境,可以参考<Linux下Hadoop集群环境的搭建>一文的内容.我在测试mapreduce任务时,发现相比于使用Job.setNumReduce ...
- Hadoop-2.2.0中文文档——Apache Hadoop 下一代 MapReduce (YARN)
MapReduce在hadoop-0.23中已经经历了一次全然彻底地大修.就是如今我们叫的MapReduce 2.0 (MRv2) or YARN. MRv2的基本思想是把JobTracker分成两个 ...
- Hadoop-2.2.0中文文档—— Common - CLI MiniCluster
目的 使用 CLI MiniCluster, 用户能够简单地仅仅用一个命令就启动或关闭一个单一节点的Hadoop集群,不须要设置不论什么环境变量或管理配置文件. CLI MiniCluster 同一时 ...
- Hadoop-2.2.0中文文档—— Common - Native Libraries Guide
概览 这个新手教程描写叙述了native(本地?原生?)hadoop库,包括了一小部分关于native hadoop共享库的讨论. This guide describes the native ha ...
随机推荐
- flask学习(四):debug模式
一. 设置debug模式 1. flask 1.0之前 在app.run()中传入一个关键字参数debug,app.run(debug=True),就设置当前项目为debug模式 2. flask 1 ...
- IOS-简单动画
iOS那些简单的动画(不定期更新) 字数669 阅读1118 评论16 喜欢59 关于 Core Animation Core Animation是一组非常强大的动画处理API,使用它能做出很多优雅的 ...
- 十四、dbms_obfuscation_toolkit(用于加密和解密应用数据)
1.概述 作用:用于加密和解密应用数据,另外还可以生成密码检验和.通过加密输入数据,可以防止黑客或其他用户窃取私有数据;而通过结合使用加密和密码检验和,可以防止黑客破坏初加密的数据.当使用该包加密数据 ...
- Python基础学习----元组
# 元组和列表的区别: # 相同点: # 1.表示多个元素的序列 # 2.数据之间用 , 分开 # 3.索引都是[0]开始 # # 不同点: # 1.列表创建是[],元组是()表示 # 2.元组元素一 ...
- C++面向对象高级编程(三)基础篇
技术在于交流.沟通,转载请注明出处并保持作品的完整性. 概要 一.拷贝构造 二.拷贝赋值 三.重写操作符 四.生命周期 本节主要介绍 Big Three 即析构函数,拷贝构造函数,赋值拷贝函数,前面主 ...
- 20165202 学习基础和c语言基础调查
你有什么技能比大多人(超过90%以上)更好? 我对自行车运动的兴趣始于初中时期,不敢说比大多数人更好,但在业余爱好者中相对来说还不错. 针对这个技能的获取你有什么成功的经验? 接触自行车运动几年里,我 ...
- 疑问:@Autowired的作用?[待解答]
有下面一个Spring的工程,工程结构如下: 代码如下: applicationContext.xml: <?xml version="1.0" encoding=" ...
- c# Request.Files["xx"]取不到值解决办法
- losetup命令
Linux losetup命令用于设置循环设备. 循环设备可把文件虚拟成区块设备,籍以模拟整个文件系统,让用户得以将其视为硬盘驱动器,光驱或软驱等设备,并挂入当作目录来使用. 语法 losetup [ ...
- NorFlash、NandFlash、eMMC比较区别
快闪存储器(英语:Flash Memory),是一种电子式可清除程序化只读存储器的形式,允许在操作中被多次擦或写的存储器.这种科技主要用于一般性数据存储,以及在电脑与其他数字产品间交换传输数据,如储存 ...