POI读写大数据量EXCEL
另一篇文章http://www.cnblogs.com/tootwo2/p/8120053.html里面有xml的一些解释。
大数据量的excel一般都是.xlsx格式的,网上使用POI读写的例子比较多,但是很少提到读写非常大数据量的excel的例子,POI官网上提到XSSF有三种读写excel,POI地址:http://poi.apache.org/spreadsheet/index.html。官网的图片:
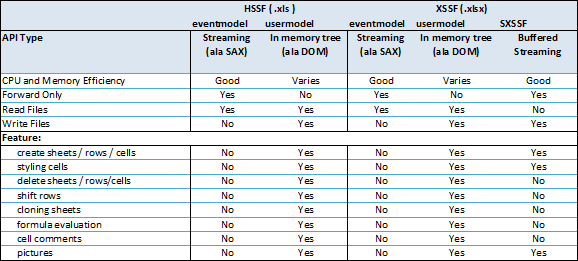
可以看到有三种模式:
1、eventmodel方式,基于事件驱动,SAX的方式解析excel(.xlsx是基于OOXML的),CPU和内存消耗非常低,但是只能读不能写
2、usermodel,就是我们一般使用的方式,这种方式可以读可以写,但是CPU和内存消耗非常大
3、SXSSF,POI3.8以后开始支持,这种方式只能写excel
下面介绍下使用方式(官网地址:http://poi.apache.org/spreadsheet/how-to.html):
第一种方式:
pom文件需要添加依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>xerces</groupId>
<artifactId>xerces</artifactId>
<version>2.4.0</version>
</dependency>
java官网示例代码:
package excel; import java.io.InputStream;
import java.util.Iterator; import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory; public class ExampleEventUserModel { public void processOneSheet(String filename) throws Exception {
OPCPackage pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader( pkg );
SharedStringsTable sst = r.getSharedStringsTable(); XMLReader parser = fetchSheetParser(sst); // To look up the Sheet Name / Sheet Order / rID,
// you need to process the core Workbook stream.
// Normally it's of the form rId# or rSheet#
InputStream sheet2 = r.getSheet("rId2");
InputSource sheetSource = new InputSource(sheet2);
parser.parse(sheetSource);
sheet2.close();
} public void processAllSheets(String filename) throws Exception {
OPCPackage pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader( pkg );
SharedStringsTable sst = r.getSharedStringsTable(); XMLReader parser = fetchSheetParser(sst); Iterator<InputStream> sheets = r.getSheetsData();
while(sheets.hasNext()) {
System.out.println("Processing new sheet:\n");
InputStream sheet = sheets.next();
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource);
sheet.close();
System.out.println("");
}
} public XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException {
XMLReader parser =
XMLReaderFactory.createXMLReader(
"com.sun.org.apache.xerces.internal.parsers.SAXParser"
);
ContentHandler handler = new SheetHandler(sst);
parser.setContentHandler(handler);
return parser;
} /**
* See org.xml.sax.helpers.DefaultHandler javadocs
*/
private static class SheetHandler extends DefaultHandler {
private SharedStringsTable sst;
private String lastContents;
private boolean nextIsString; private SheetHandler(SharedStringsTable sst) {
this.sst = sst;
} public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
// c => cell
if(name.equals("c")) {
// Print the cell reference
System.out.print(attributes.getValue("r") + " - ");
// Figure out if the value is an index in the SST
String cellType = attributes.getValue("t");
if(cellType != null && cellType.equals("s")) {
nextIsString = true;
} else {
nextIsString = false;
}
}
// Clear contents cache
lastContents = "";
} public void endElement(String uri, String localName, String name)
throws SAXException {
// Process the last contents as required.
// Do now, as characters() may be called more than once
if(nextIsString) {
int idx = Integer.parseInt(lastContents);
lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();
nextIsString = false;
} // v => contents of a cell
// Output after we've seen the string contents
if(name.equals("v")) {
System.out.println(lastContents);
}
} public void characters(char[] ch, int start, int length)
throws SAXException {
lastContents += new String(ch, start, length);
}
} public static void main(String[] args) throws Exception {
ExampleEventUserModel example = new ExampleEventUserModel();
System.out.println("11");
example.processOneSheet(args[0]);
example.processAllSheets(args[0]);
}
}
运行的时候使用本地的文件地址替代main函数里面的参数就可以运行(亲测可以)。
第三种方式:
其核心是减少存储在内存当中的数据,达到一定行数就存储到硬盘的临时文件中。
pom文件需要增加依赖:
<dependency>
<groupId>xerces</groupId>
<artifactId>xercesImpl</artifactId>
<version>2.11.0</version>
</dependency>
java代码如下:
package excel; //import junit.framework.Assert;
import java.io.FileOutputStream; import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.util.CellReference;
import org.apache.poi.xssf.streaming.SXSSFWorkbook; public class SXSSFDemo {
public static void main(String[] args) throws Throwable { SXSSFWorkbook wb = new SXSSFWorkbook(100); // 在内存当中保持 100 行 , 超过的数据放到硬盘中
Sheet sh = wb.createSheet();
for(int rownum = 0; rownum < 10000; rownum++){
Row row = sh.createRow(rownum);
for(int cellnum = 0; cellnum < 10; cellnum++){
Cell cell = row.createCell(cellnum);
String address = new CellReference(cell).formatAsString();
cell.setCellValue(address);
} } FileOutputStream out = new FileOutputStream("/Users/tootwo2/Documents/sxssf.xlsx");
wb.write(out);
out.close(); // dispose of temporary files backing this workbook on disk
wb.dispose();
} }
POI读写大数据量EXCEL的更多相关文章
- POI读写大数据量excel,解决超过几万行而导致内存溢出的问题
1. Excel2003与Excel2007 两个版本的最大行数和列数不同,2003版最大行数是65536行,最大列数是256列,2007版及以后的版本最大行数是1048576行,最大列数是16384 ...
- POI 读写大数据量 EXCEL
参考:https://www.cnblogs.com/tootwo2/p/6683143.html
- [转]POI大数据量Excel解决方案
全文转载自:jinshuaiwang的博客 目前处理Excel的开源javaAPI主要有两种,一是Jxl(Java Excel API),Jxl只支持Excel2003以下的版本.另外一种是Apach ...
- POI3.8解决导出大数据量excel文件时内存溢出的问题
POI3.8的SXSSF包是XSSF的一个扩展版本,支持流处理,在生成大数据量的电子表格且堆空间有限时使用.SXSSF通过限制内存中可访问的记录行数来实现其低内存利用,当达到限定值时,新一行数据的加入 ...
- 由“大数据量Excel入库高效方式”瞥见“并联系统”之优势
使用场景: 当你有一个Excel文件,需要把其中的数据高速录入到数据库中,文件中包含10万条以上数据. 设计方案: 我们将整个过程分成三个阶段,A(装载Excel文件). ...
- C#读取大数据量Excel
var worksheet = workbook.Worksheets["工作表1"]; var maxN = worksheet.Range["A1"].En ...
- python3 修改大数据量excel内容
最好使用python3 64位 对excel的修改操作: from openpyxl import load_workbook import time #打开一个excel表格.xlsx wb = l ...
- POI实现大数据EXCLE导入导出,解决内存溢出问题
使用POI能够导出大数据保证内存不溢出的一个重要原因是SXSSFWorkbook生成的EXCEL为2007版本,修改EXCEL2007文件后缀为ZIP打开可以看到,每一个Sheet都是一个xml文件, ...
- poi 操作Excel 以及大数据量导出
maven 依赖 (版本必须一致,否则使用SXSSFworkbook 时程序会报错) <dependency> <groupId>org.apache.poi</grou ...
随机推荐
- 网页中PNG透明背景图片的完美应用
PNG 图片在网站设计中是不可或缺的部分,最大的特点应该在于 PNG 可以无损压缩,而且还可以设置透明,对于增强网站的图片色彩效果有重要的作用. 但为什么 PNG 图片却没有 GIF 和 JPG 图片 ...
- js身份证验证算法
var validateIdCard=function (id, backInfo) { var info={ y: "1900", m: "01", d: & ...
- Redis的5个常见应用场景
前言 Redis 是一个强大的内存型存储,具有丰富的数据结构,使其可以应用于很多方面,包括作为数据库.缓存.消息队列等等. 如果你的印象中Redis只是一个 key-value 存储,那就错过了Red ...
- freeswitch 把SIP注册信息数据库从SQLITE 改为MYSQL的方法
实际线上应用中,在线注册人数超过4000 ,SQLITE就吃不消了,容易造成锁表,考虑转入MYSQL,查了下官网 超过转入了MYSQL. https://wiki.freeswitch.org/wik ...
- FTPHelper-封装FTP的相关操作
using System; using System.IO; using System.Net; using System.Text; namespace Whir.Software.DataSync ...
- spring session配置
spring session是一个解决集群环境中,session持久化管理的依赖库.配置非常简单. 在spring boot环境中添加依赖 <dependency> <groupId ...
- IOS基于XMPP协议开发--XMPPFramewok框架(一):基础知识
最近蘑菇街团队的TT的开源,使我对im产生了兴趣,然后在网上找到了XMPPFramework进行学习研究, 并写了以下系列教程供大家参考,有写的不对的地方,请大家多多包涵指正. 目录索引 IOS基于X ...
- 开发avr单片机网络资源
1.avr用的c语言标准库 http://www.nongnu.org/avr-libc/ 2.avr的下载上传器 http://www.nongnu.org/avrdude/ 3.编程环境platf ...
- C#趣味程序---爱因斯坦的台阶问题
问题:设有一阶梯,每步跨2阶.最后余1阶.每步跨3阶.最后余2阶:每步跨5阶.最后余4阶:每步跨6阶.最后余5阶:每步跨7阶.刚好到阶顶.问共同拥有多少阶梯? using System; namesp ...
- mysql操作及自动化运维
备份恢复工具:percona-xtrabackup-2.0.0-417.rhel6.x86_64.rpm mysql主从配置命令: 主: 1.编辑主MYSQL 服务器的MySQL配置文件my.cnf, ...