List和Dictionary泛型类查找效率浅析
List和Dictionary泛型类查找效率存在巨大差异,前段时间亲历了一次。事情的背景是开发一个匹配程序,将书籍(BookID)推荐给网友(UserID),生成今日推荐数据时,有条规则是同一书籍七日内不能推荐给同一网友。
同一书籍七日内不能推荐给同一网友规则的实现是程序不断优化的过程,第一版程序是直接取数据库,根据BookID+UserID查询七日内有无记录,有的话不进行分配。但随着数据量的增大,程序运行时间越来越长,于是开始优化。第一次优化是把所有七日内的数据取出来,放到List<T>中,然后再内存中进行查找,发现这样效率只是稍有提高,但不明显。第二次优化采用了Dictionary<TKey, TValue>,意外的发现效果不是一般的好,程序效率提高了几倍。
下面是伪代码,简化了程序代码,只是为说明List和Dictionary效率的差别,并不具备实际意义。
/// <summary>
/// 集合类效率测试
/// </summary>
public class SetEfficiencyTest
{
static List<TestModel> todayList = InitTodayData();
static List<TestModel> historyList = InitHisoryData(); public static void Run()
{
CodeTimer.Time("ListTest", , ListTest);
CodeTimer.Time("DictionaryTest", , DictionaryTest);
} public static void ListTest()
{
List<TestModel> resultList = todayList.FindAll(re =>
{
if (historyList.Exists(m => m.UserID == re.UserID && m.BookID == re.BookID))
{
return false;
}
return true;
});
} public static void DictionaryTest()
{
Dictionary<int, List<string>> bDic = new Dictionary<int, List<string>>();
foreach (TestModel obj in historyList)
{
if (!bDic.ContainsKey(obj.UserID))
{
bDic.Add(obj.UserID, new List<string>());
}
bDic[obj.UserID].Add(obj.BookID);
} List<TestModel> resultList = todayList.FindAll(re =>
{
if (bDic.ContainsKey(re.UserID) && bDic[re.UserID].Contains(re.BookID))
{
return false;
}
return true;
});
} /// <summary>
/// 初始化数据(今日)
/// </summary>
/// <returns></returns>
public static List<TestModel> InitTodayData()
{
List<TestModel> list = new List<TestModel>();
for (int i = ; i < ; i++)
{
list.Add(new TestModel() { UserID = i, BookID = i.ToString() });
}
return list;
} /// <summary>
/// 初始化数据(历史)
/// </summary>
/// <returns></returns>
public static List<TestModel> InitHisoryData()
{
List<TestModel> list = new List<TestModel>();
Random r = new Random();
int loopTimes = ;
for (int i = ; i < loopTimes; i++)
{
list.Add(new TestModel() { UserID = r.Next(, loopTimes), BookID = i.ToString() });
}
return list;
} /// <summary>
/// 测试实体
/// </summary>
public class TestModel
{
/// <summary>
/// 用户ID
/// </summary>
public int UserID { get; set; } /// <summary>
/// 书ID
/// </summary>
public string BookID { get; set; }
}
}
输出如下:
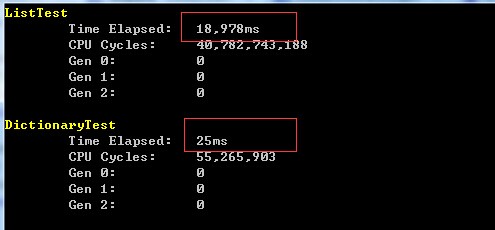
真是想不到,两者效率相差这么多。接下来研究下两者差异巨大的原因。
List<T>.Exists()函数的实现:
public bool Exists(Predicate<T> match)
{
return this.FindIndex(match) != -;
} public int FindIndex(Predicate<T> match)
{
return this.FindIndex(, this._size, match);
}
public int FindIndex(int startIndex, int count, Predicate<T> match)
{
if (startIndex > this._size)
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.startIndex, ExceptionResource.ArgumentOutOfRange_Index);
}
if (count < || startIndex > this._size - count)
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.count, ExceptionResource.ArgumentOutOfRange_Count);
}
if (match == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.match);
}
int num = startIndex + count;
for (int i = startIndex; i < num; i++)
{
if (match(this._items[i]))
{
return i;
}
}
return -;
}
List<T>.Exists 本质是通过循环查找出该条数据,每一次的调用都会重头循环,所以效率很低。显然,这是不可取的。
Dictionary<TKey, TValue>.ContainsKey()函数的实现:
public bool ContainsKey(TKey key)
{
return this.FindEntry(key) >= ;
} // System.Collections.Generic.Dictionary<TKey, TValue>
private int FindEntry(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (this.buckets != null)
{
int num = this.comparer.GetHashCode(key) & ;
for (int i = this.buckets[num % this.buckets.Length]; i >= ; i = this.entries[i].next)
{
if (this.entries[i].hashCode == num && this.comparer.Equals(this.entries[i].key, key))
{
return i;
}
}
}
return -;
}
Dictionary<TKey, TValue>.ContainsKey() 内部是通过Hash查找实现的,所以效率比List高出很多。
最后,给出MSDN上的建议:
1.如果需要非常快地添加、删除和查找项目,而且不关心集合中项目的顺序,那么首先应该考虑使用 System.Collections.Generic.Dictionary<TKey, TValue>(或者您正在使用 .NET Framework 1.x,可以考虑 Hashtable)。三个基本操作(添加、删除和包含)都可快速操作,即使集合包含上百万的项目。
2.如果您的使用模式很少需要删除和大量添加,而重要的是保持集合的顺序,那么您仍然可以选择 List<T>。虽然查找速度可能比较慢(因为在搜索目标项目时需要遍历基础数组),但可以保证集合会保持特定的顺序。
3.您可以选择 Queue<T> 实现先进先出 (FIFO) 顺序或 Stack<T> 实现后进先出 (LIFO) 顺序。虽然 Queue<T> 和 Stack<T> 都支持枚举集合中的所有项目,但前者只支持在末尾插入和从开头删除,而后者只支持从开头插入和删除。
4.如果需要在实现快速插入的同时保持顺序,那么使用新的 LinkedList<T> 集合可帮助您提高性能。与 List<T> 不同,LinkedList<T> 是作为动态分配的对象链实现。与 List<T> 相比,在集合中间插入对象只需要更新两个连接和添加新项目。从性能的角度来看,链接列表的缺点是垃圾收集器会增加其活动,因为它必须遍历整个列表以确保没有对象没有被释放。另外,由于每个节点相关的开销以及每个节点在内存中的位置等原因,大的链接列表可能会出现性能问题。虽然将项目插入到 LinkedList<T> 的实际操作比在 List<T> 中插入要快得多,但是找到要插入新值的特定位置仍需遍历列表并找到正确的位置。
参考资料:CLR 完全介绍: 最佳实践集合, List和hashtable之查找效率
List和Dictionary泛型类查找效率浅析的更多相关文章
- Hashtable Dictionary List 谁效率更高
一 前言 很少接触HashTable晚上回来简单看了看,然后做一些增加和移除的操作,就想和List 与 Dictionary比较下存数据与取数据的差距,然后便有了如下的一此测试, 当然我测的方法可能不 ...
- python 字典有序无序及查找效率,hash表
刚学python的时候认为字典是无序,通过多次插入,如di = {}, 多次di['testkey']='testvalue' 这样测试来证明无序的.后来接触到了字典查找效率这个东西,查了一下,原来字 ...
- 何在mysql查找效率慢的SQL语句?
如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow-queries[=file_name]选项启 ...
- MySQL数据库中的字段类型varchar和char的主要区别是什么?哪种字段查找效率要高?
1,varchar与char的区别?(1)区别一,定长和变长,char表示定长,长度固定:varchar表示变长,长度可变.当插入字符串超出长度时,视情况来处理,如果是严格模式,则会拒绝插入并提示错误 ...
- python中in在list和dict中查找效率比较
转载自:http://blog.csdn.net/wzgbm/article/details/54691615 首先给一个简单的例子,测测list和dict查找的时间: ,-,-,-,-,,,,,,] ...
- 下拉列表框DropDownList绑定Dictionary泛型类
DropDownList绑定Dictionary泛型类 定义一个Dictionary泛型类 /// <summary> /// 产品类型 /// </summary> ...
- zset如何解决内部链表查找效率低下
zset作为有序集合,内部基于跳表或者说索引的方式实现了数据的快速查找.解决了链表查询效率低下的痛点 前言 紧接前文我们学习了Redis中Hash结构.在里面我们梳理了字典这个重要的内部结构并分析了h ...
- 使用unordered_map提升查找效率
在对网络数据包流(Flow)进行处理的时候,一开始为了简单使用了vector做为Flow信息的存储容器,当其中的元素达到几十万时,程序的执行速度让人无法忍受.已经对vector进行过合理的预先rese ...
- QVector与QMap查找效率实战(QMap快N倍,因为QVector是数组,QMap是有序二叉树,查找的时候是N和LogN的速度对比)
因为项目使用QVector,太慢了,听说QMap比QVector查找时快,所以写一个小程序试试: 从30000个数据中找5000个 程序运行截图如下: QVector QMap 一样的数据,找一样的数 ...
随机推荐
- player.swf播放flv方式
<embed src="../images/player.swf" allowFullScreen="true" quality="high&q ...
- mysql用户权限设置
1.创建新用户 通过root用户登录之后创建 >> grant all privileges on *.* to testuser@localhost identified by &quo ...
- map 遍历
//最常规的一种遍历方法,最常规就是最常用的,虽然不复杂,但很重要,这是我们最熟悉的,就不多说了!! public static void work(Map<String, Student> ...
- 升级java8---from centos
安装步骤: wget http://10.107.2.44/jdk-8u111-linux-x64.tar.gz root@ute-image:~# tar zxf jdk-8u111-linux-x ...
- iOS Wi-Fi
查漏补缺集是自己曾经做过相关的功能,但是重做相关功能或者重新看到相关功能的实现,感觉理解上更深刻.这一类的文章集中记录在查漏补缺集. iOS 开发中难免会遇到很多与网络方面的判断,这里做个汇总,大多可 ...
- PowerShell笔记
教程: http://www.pstips.net/powershell-online-tutorials/ http://www.3fwork.com/a113/ 1. 查看成员 $MyInvoca ...
- STC12C5A60S2笔记6(中断)
1. 基本特性 1) 中断源 STC12C5A60S2共有十个中断源,每个中断源可设置4类优先级:当相同优先级下各中断优先级由高到低依次如下: 1.1)INT0(外部中断0) 中断向量地址 0003H ...
- PSP
PSP2.1 Time(%) Planning 10 l Estimate 10 Development 90 l Analysis 10 l Design Spec 5 l Design Revie ...
- 玩转正则之highlight高亮
程序员在编写代码的时候少不了和字符串以及“查询”打交道,两者的交集中有一个叫做正则表达式的的东西,这家伙用好了可以提高编程效率,用不好的话...你可以先去好好学一学. 关于正则的使用,举个简单的例子: ...
- angularjs之browserTrigger
今天推荐一款来自angularjs源码的单元测试辅助库browserTrigger,这是来自于ngScenario的一段代码.主要用户触发浏览器型行为更新ng中scope view model的值. ...