Hbase的JavaAPI和数据存储
导入Maven依赖
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.5</version>
</dependency>
<!-- 使用mr程序操作hbase 数据的导入 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.5</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
<!-- phoenix 凤凰 用来整合Hbase的工具 -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<!-- bind to the packaging phase -->
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
获取hbase的连接,list出所有的表
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
/**
* Hbase的java客户端连接hbase的时候,只需要连接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的对象:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* table:conn.getTable(TableName.valueOf("tb_b")); 对表进行操作 DML
* Admin:conn.getAdmin();操作Hbase系统DDL,对名称空间等进行操作
*/
public class ConnectionDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//获取到操作hbase的对象
Admin admin = conn.getAdmin();
//调用api获取到所有的表
TableName[] tableNames = admin.listTableNames();
//获取到哪个命名空间下的所有的表
TableName[] doits = admin.listTableNamesByNamespace("doit");
for (TableName tableName : doits) {
byte[] name = tableName.getName();
System.out.println(new String(name));
}
conn.close();
}
}
获取到所有的命名空间
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
/**
* Hbase的java客户端连接hbase的时候,只需要连接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的对象:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* Admin:conn.getAdmin();操作Hbase系统DDL,对名称空间等进行操作
*/
public class NameSpaceDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//获取到操作hbase的对象
Admin admin = conn.getAdmin();
//获取到命名空间的描述器
NamespaceDescriptor[] namespaceDescriptors = admin.listNamespaceDescriptors();
for (NamespaceDescriptor namespaceDescriptor : namespaceDescriptors) {
//针对描述器获取到命名空间的名称
String name = namespaceDescriptor.getName();
System.out.println(name);
}
conn.close();
}
}
创建一个命名空间
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.protobuf.generated.HBaseProtos;
import java.util.Properties;
/**
* Hbase的java客户端连接hbase的时候,只需要连接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的对象:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* Admin:conn.getAdmin();操作Hbase系统DDL,对名称空间等进行操作
*/
public class CreateNameSpaceDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//获取到操作hbase的对象
Admin admin = conn.getAdmin();
//获取到命名空间描述器的构建器
NamespaceDescriptor.Builder spaceFromJava = NamespaceDescriptor.create("spaceFromJava");
//当然还可以给命名空间设置属性
spaceFromJava.addConfiguration("author","robot_jiang");
spaceFromJava.addConfiguration("desc","this is my first java namespace...");
//拿着构建器构建命名空间的描述器
NamespaceDescriptor build = spaceFromJava.build();
//创建命名空间
admin.createNamespace(build);
conn.close();
}
}
创建带有多列族的表
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.protobuf.generated.TableProtos;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Map;
import java.util.Set;
/**
* Hbase的java客户端连接hbase的时候,只需要连接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的对象:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* Admin:conn.getAdmin();操作Hbase系统DDL,对名称空间等进行操作
*/
public class CreateTableDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
//获取到操作hbase操作表的对象
TableDescriptorBuilder java = TableDescriptorBuilder.newBuilder(TableName.valueOf("java"));
//表添加列族需要集合的方式
ArrayList<ColumnFamilyDescriptor> list = new ArrayList<>();
//构建一个列族的构造器
ColumnFamilyDescriptorBuilder col1 = ColumnFamilyDescriptorBuilder.newBuilder("f1".getBytes(StandardCharsets.UTF_8));
ColumnFamilyDescriptorBuilder col2 = ColumnFamilyDescriptorBuilder.newBuilder("f2".getBytes(StandardCharsets.UTF_8));
ColumnFamilyDescriptorBuilder col3 = ColumnFamilyDescriptorBuilder.newBuilder("f3".getBytes(StandardCharsets.UTF_8));
//构建列族
ColumnFamilyDescriptor build1 = col1.build();
ColumnFamilyDescriptor build2 = col2.build();
ColumnFamilyDescriptor build3 = col3.build();
//将列族添加到集合中去
list.add(build1);
list.add(build2);
list.add(build3);
//给表设置列族
java.setColumnFamilies(list);
//构建表的描述器
TableDescriptor build = java.build();
//创建表
admin.createTable(build);
conn.close();
}
}
向表中添加数据
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Arrays;
/**
* 注意:put数据需要指定往哪个命名空间的哪个表的哪个rowKey的哪个列族的哪个列中put数据,put的值是什么
*/
public class PutDataDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
//指定往哪一张表中put数据
Table java = conn.getTable(TableName.valueOf("java"));
//创建put对象,设置rowKey
Put put = new Put("rowkey_001".getBytes(StandardCharsets.UTF_8));
put.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),"xiaotao".getBytes(StandardCharsets.UTF_8));
put.addColumn("f1".getBytes(StandardCharsets.UTF_8),"age".getBytes(StandardCharsets.UTF_8),"42".getBytes(StandardCharsets.UTF_8));
Put put1 = new Put("rowkey_002".getBytes(StandardCharsets.UTF_8));
put1.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),"xiaotao".getBytes(StandardCharsets.UTF_8));
put1.addColumn("f1".getBytes(StandardCharsets.UTF_8),"age".getBytes(StandardCharsets.UTF_8),"42".getBytes(StandardCharsets.UTF_8));
Put put2 = new Put("rowkey_003".getBytes(StandardCharsets.UTF_8));
put2.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),"xiaotao".getBytes(StandardCharsets.UTF_8));
put2.addColumn("f1".getBytes(StandardCharsets.UTF_8),"age".getBytes(StandardCharsets.UTF_8),"42".getBytes(StandardCharsets.UTF_8));
java.put(Arrays.asList(put,put1,put2));
conn.close();
}
}
get表中的数据
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.nio.charset.StandardCharsets;
/**
* 注意:put数据需要指定往哪个命名空间的哪个表的哪个rowKey的哪个列族的哪个列中put数据,put的值是什么
*/
public class GetDataDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//指定往哪一张表中put数据
Table java = conn.getTable(TableName.valueOf("java"));
Get get = new Get("rowkey_001".getBytes(StandardCharsets.UTF_8));
// get.addFamily("f1".getBytes(StandardCharsets.UTF_8));
get.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8));
Result result = java.get(get);
boolean advance = result.advance();
if(advance){
Cell current = result.current();
String family = new String(CellUtil.cloneFamily(current));
String qualifier = new String(CellUtil.cloneQualifier(current));
String row = new String(CellUtil.cloneRow(current));
String value = new String(CellUtil.cloneValue(current));
System.out.println(row+","+family+","+qualifier+","+value);
}
conn.close();
}
}
scan表中的数据
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.Iterator;
/**
* 注意:put数据需要指定往哪个命名空间的哪个表的哪个rowKey的哪个列族的哪个列中put数据,put的值是什么
*/
public class ScanDataDemo {
public static void main(String[] args) throws Exception {
//获取到hbase的配置文件对象
Configuration conf = HBaseConfiguration.create();
//针对配置文件设置zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//创建hbase的连接对象
Connection conn = ConnectionFactory.createConnection(conf);
//指定往哪一张表中put数据
Table java = conn.getTable(TableName.valueOf("java"));
Scan scan = new Scan();
scan.withStartRow("rowkey_001".getBytes(StandardCharsets.UTF_8));
scan.withStopRow("rowkey_004".getBytes(StandardCharsets.UTF_8));
ResultScanner scanner = java.getScanner(scan);
Iterator<Result> iterator = scanner.iterator();
while (iterator.hasNext()){
Result next = iterator.next();
while (next.advance()){
Cell current = next.current();
String family = new String(CellUtil.cloneFamily(current));
String row = new String(CellUtil.cloneRow(current));
String qualifier = new String(CellUtil.cloneQualifier(current));
String value = new String(CellUtil.cloneValue(current));
System.out.println(row+","+family+","+qualifier+","+value);
}
}
conn.close();
}
}
删除一行数据
package com.doit.day02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
public class _12_删除一行数据 {
public static void main(String[] args) throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","linux01");
Connection conn = ConnectionFactory.createConnection(conf);
Table java = conn.getTable(TableName.valueOf("java"));
Delete delete = new Delete("rowkey_001".getBytes(StandardCharsets.UTF_8));
java.delete(delete);
}
}
数据存储
行式存储
传统的行式数据库将一个个完整的数据行存储在数据页中
列式存储
列式数据库是将同一个数据列的各个值存放在一起
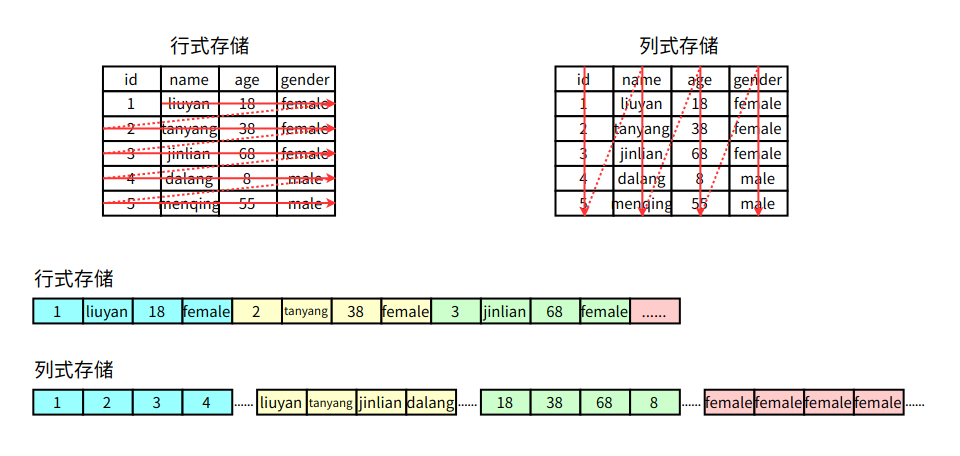
传统行式数据库的特性如下:
- 数据是按行存储的。
- 没有索引的查询使用大量I/O。比如一般的数据库表都会建立索引,通过索引加快查询效率。
- 建立索引和物化视图需要花费大量的时间和资源。
- 面对查询需求,数据库必须被大量膨胀才能满足需求。
列式数据库的特性如下:
- 数据按列存储,即每一列单独存放。
- 数据即索引。
- 只访问查询涉及的列,可以大量降低系统I/O。
- 每一列由一个线程来处理,即查询的并发处理性能高。
- 数据类型一致,数据特征相似,可以高效压缩。比如有增量压缩、前缀压缩算法都是基于列存储的类型定制的,所以可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗。
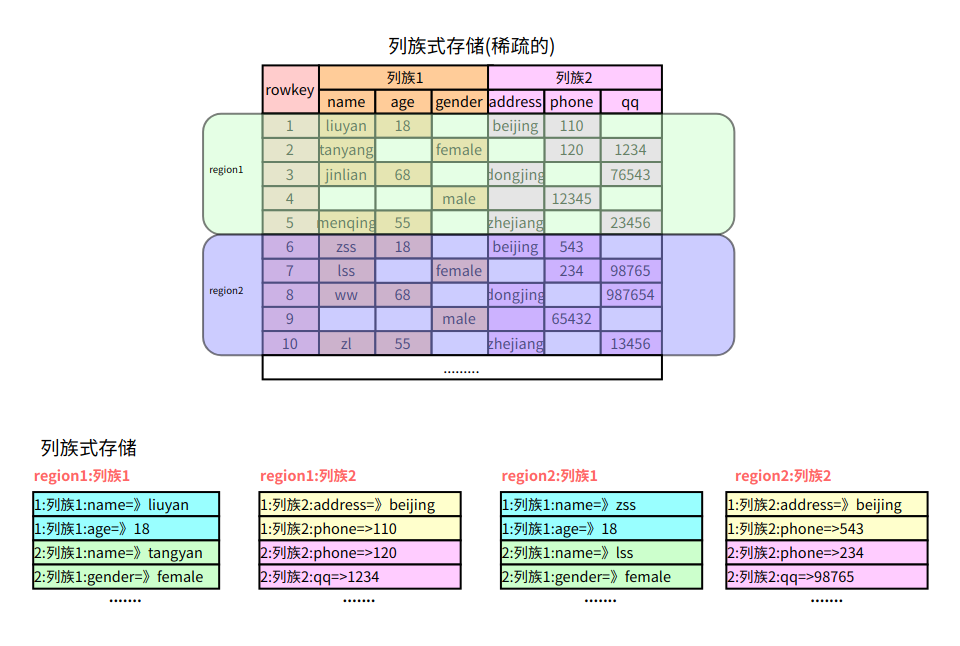
列族式存储
列族式存储是一种非关系型数据库存储方式,按列而非行组织数据。它的数据模型是面向列的,即把数据按照列族的方式组织,将属于同一列族的数据存储在一起。每个列族都有一个唯一的标识符,一般通过列族名称来表示。它具有高效的写入和查询性能,能够支持极大规模的数据
- 如果一个表有多个列族, 每个列族下只有一列, 那么就等同于列式存储。
- 如果一个表只有一个列族, 该列族下有多个列, 那么就等同于行式存储.
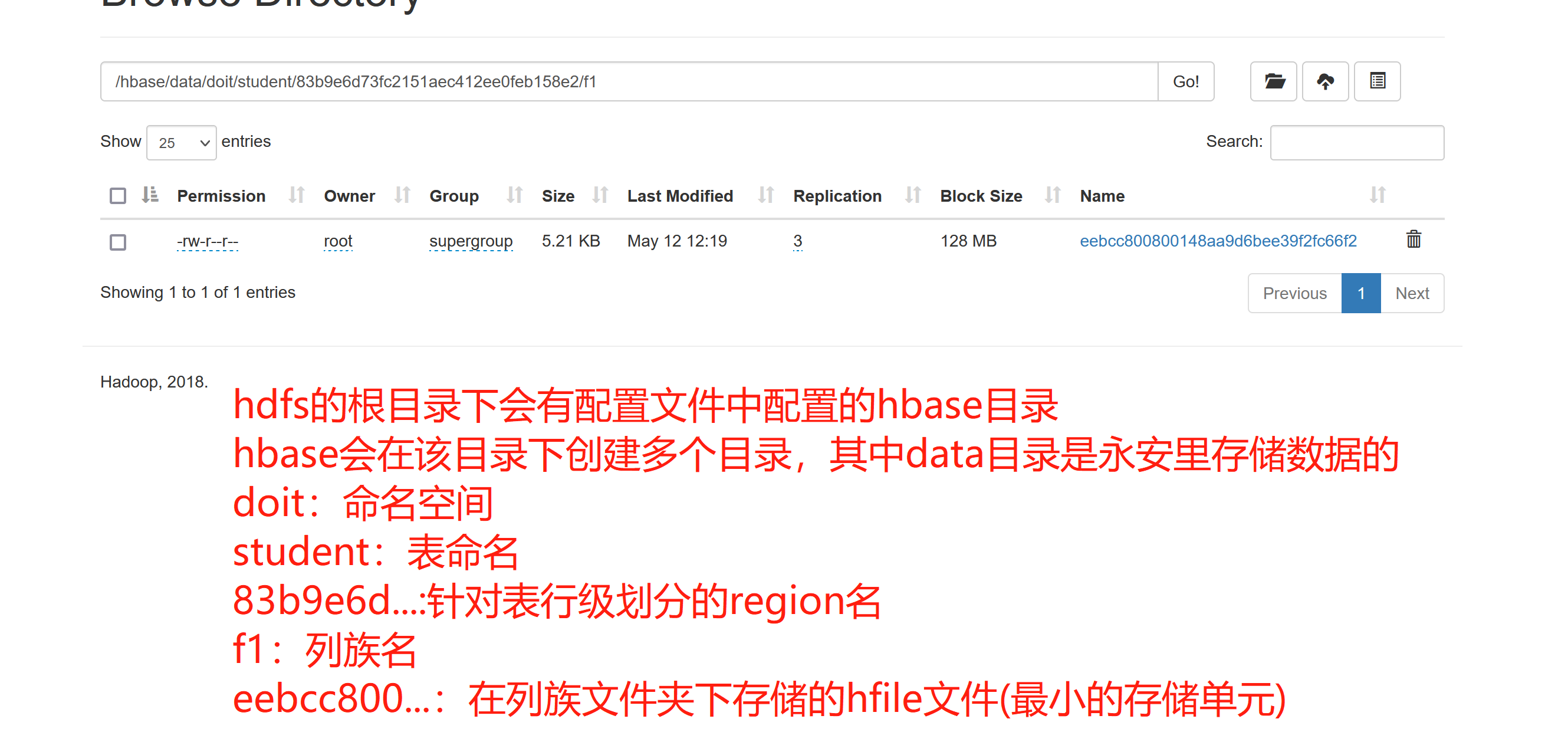
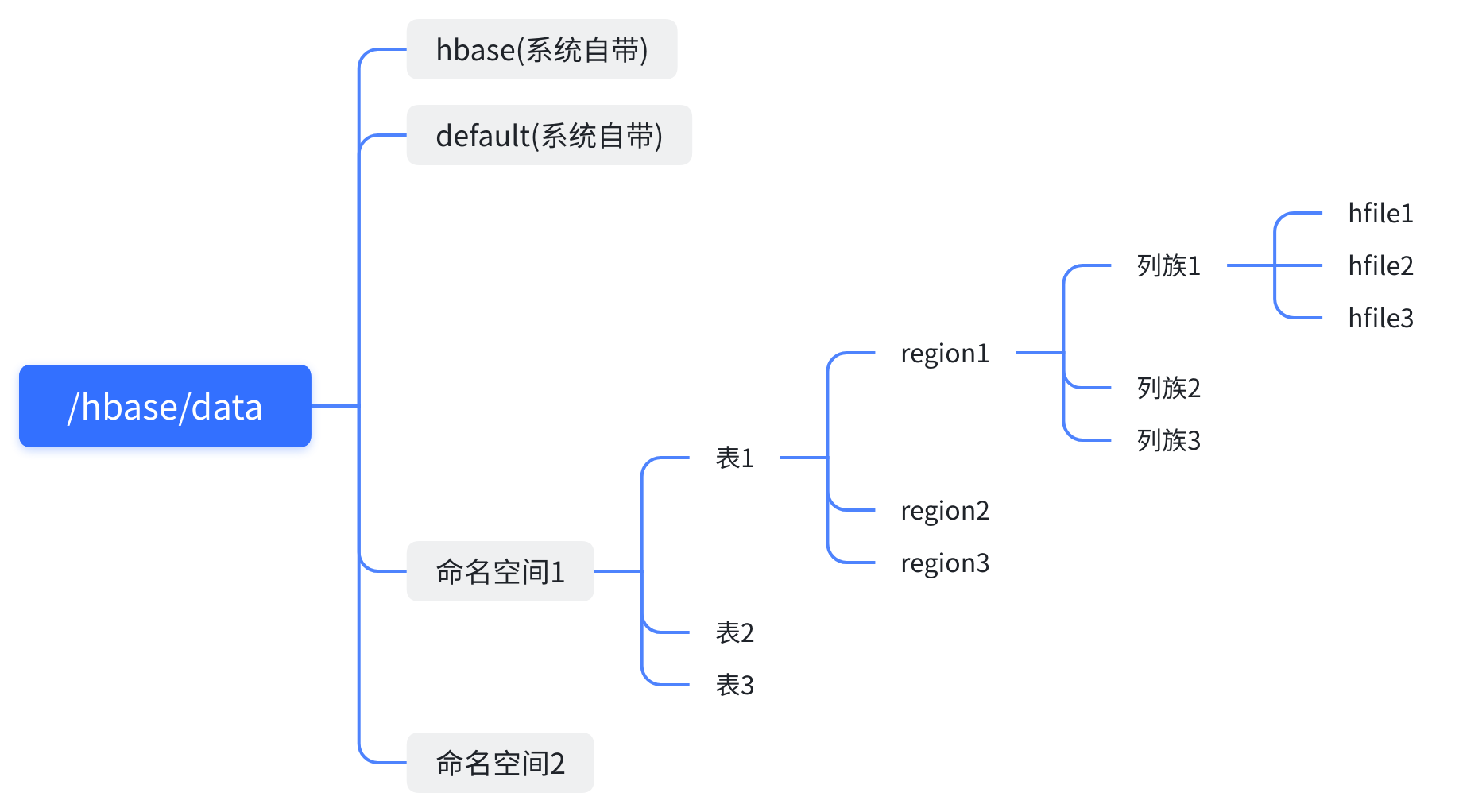
hbase的存储路径:
在conf目录下的hbase-site.xml文件中配置了数据存储的路径在hdfs上
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux01:8020/hbase</value>
</property>
hdfs上的存储路径:
Hbase的JavaAPI和数据存储的更多相关文章
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- HBase介绍(2)---数据存储结构
在本文中的HBase术语:基于列:column-oriented行:row列组:column families列:column单元:cell 理解HBase(一个开源的Google的BigTable实 ...
- 万亿级日志与行为数据存储查询技术剖析——Hbase系预聚合方案、Dremel系parquet列存储、预聚合系、Lucene系
转自:http://www.infoq.com/cn/articles/trillion-log-and-data-storage-query-techniques?utm_source=infoq& ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- 大数据存储利器 - Hbase 基础图解
由于疫情原因在家办公,导致很长一段时间没有更新内容,这次终于带来一篇干货,是一篇关于 Hbase架构原理 的分享. Hbase 作为实时存储框架在大数据业务下承担着举足轻重的地位,可以说目前绝大多数大 ...
- HBase 数据存储结构
在HBase中, 从逻辑上来讲数据大概就长这样: 单从图中的逻辑模型来看, HBase 和 MySQL 的区别就是: 将不同的列归属与同一个列族下 支持多版本数据 这看着感觉也没有那么太大的区别呀, ...
- HBase(六)HBase整合Hive,数据的备份与MR操作HBase
一.数据的备份与恢复 1. 备份 停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群. 即,把数 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
一.前言 Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关 ...
随机推荐
- Rancher 系列文章-Rancher 对接 Active Directory 实战
概述 只要是个公司,基本上都有邮箱和 AD(Active Directory). 在 AD 里,已经有了: 用户 账号密码 邮箱 用户组 组织架构 所以对于一些仅限于本公司一定范围内人员使用的管理或后 ...
- 端口转发、Http Tunnel、内网穿透
原文链接:https://www.yuque.com/tec-nine/architecture/mgxc71 SSH 命令帮助 命令行选项有: -a 禁止转发认证代理的连接. -A 允许转发认证代理 ...
- 超详细!新手如何创建一个Vue项目
目录 一.在官网下载Vue.js 二.使用<script>标签直接引入本地的vue.js 三.使用CDN引入Vue.js 四.验证是否安装成功 五.安装Vue Devtools浏览器调试插 ...
- XXL-JOB定时任务框架(Oracle定制版)
特点 xxl-job是一个轻量级.易扩展的分布式任务调度平台,能够快速开发和简单学习.开放源代码并被多家公司线上产品使用,开箱即用.尽管其确实非常好用,但我在工作中使用的是Oracle数据库,因为xx ...
- 循序渐进的掌握uni-app,两个小时完成一个简单项目——新闻App、新闻小程序
效果图 一.创建项目 uni-app 是一个使用 Vue.js 开发所有前端应用的框架,开发者编写一套代码,可发布到iOS.Android.Web(响应式).以及各种小程序(微信/支付宝/百度/头条/ ...
- Go语言核心知识回顾(接口、Context、协程)
温故而知新 接口 接口是一种共享边界,计算机系统的各个独立组件可以在这个共享边界上交换信息,在面向对象的编程语言,接口指的是相互独立的两个对象之间的交流方式,接口有如下好处: 隐藏细节: 对对象进行必 ...
- LAL v0.35.4发布,OBS支持RTMP H265推流,我跟了
Go语言流媒体开源项目 LAL 今天发布了v0.35.4版本. LAL 项目地址:https://github.com/q191201771/lal 老规矩,简单介绍一下: ▦ 一. OBS支持RTM ...
- 移除List的统一逻辑写法 LeetCode 203
原理:通过创建一个新的结点,放在头结点的前面,作为真正头结点的前驱结点,这样头结点就成为了意义上的非头结点,这样就可以统一操作结点的删除操作. 需要注意的是:这个新的结点是虚拟头结点,真的的头结点依然 ...
- 18-html压缩
const { resolve } = require('path'); const HtmlWebpackPlugin = require('html-webpack-plugin'); modul ...
- Sitecore XP 10.3(latest) Docker一键部署
本文演示通过PowerShell+Docker Desktop for Windows 一键部署Sitecore10.3(即Sitecore最新版)Docker开发/测试/演示 环境. 官方参考 Si ...