【论文阅读】ICRA2021: VDB-EDT An Efficient Euclidean Distance Transform Algorithm Based on VDB Data Struct
参考与前言
Summary: 浩哥推荐的一篇 无人机下的建图 and planning实验
Type: ICRA
Year: 2021
论文链接:https://arxiv.org/abs/2105.04419
youtube presentation video:https://youtu.be/Bojh6ylYUOo
代码链接:https://github.com/zhudelong/VDB-EDT
1. Motivation
Eucliden distance transform EDT 对于机器人运动规划是很重要的,但是生成EDT 是比较费时的一件事,同时需要时刻更新并维护这样一个地图,本篇文章主要 通过优化数据结构和distance transform的过程来提升EDT算法的速度
在本文中,我们采用了树结构进行 hashing-based EDTs,主要是在做规划时发现 最优轨迹其实值需要考虑一定范围的障碍物, full distance information其实对于规划来说是冗余的,所以实际free部分都是一个值。These regions can then be efficiently encoded by a few number of tree nodes. Such a property is called spatial coherency, which can help further reduce memory consumption.
Benefiting from the fast index and caching systems, VDB achieves a much faster random access speed than Octree and also exhibits a competitive performance with the voxel hashing.
Contribution
- the first time introduce the VDB data structure for distance field representation, which significantly reduces the memory consumption of EDT.
- we propose a novel algorithm to facilitate distance transform procedure and significantly improve the running speed of conventional EDT algorithms.
2. Method
首先是问题定义,一个典型的distance transform问题 可以表达为如下公式:
\]
其中,Mf是指free space,Mo是被占据空间,x为在grid map M中的坐标,目标函数f表示xi到xj之间的距离,目标是搜索对于每个xi都找其最近的xj作为距离
随后问题有了d(x) 后 我们就走到了 要找到一条安全的路径,则问题可表述为如下:
\]
其中,dmax是最大的transform distance,xs起点,xf终点,alpha为balance coefficient,g<theta主要是限制两个连续点之间产生较大的角度,平滑轨迹用的。目标函数中 前者为路径长度的cost,后者为避障的cost
2.1 数据结构
主要是介绍了VDB结构,由Museth[25] 提出的。It sufficiently exploits the sparsity of volumetric data, and employs a variant of B+ tree [32] to represent the data hierarchically.
下图是1D结构下的VDB,其和B+的几个特性是一致的,root node为索引,由hashmap建立,下面为internal node 和 leaf node保存了数据。也有本质上的不同:
it encodes values in internal nodes, called tile value. The tile value and child pointer exclusively use the same memory unit, and a flag is additionally leveraged to identify the different cases. A tile value only takes up tens of bits memory but can represent a large area in the distance field, which is the key feature leveraged to improve memory efficiency.
B+是一种平衡tree,在数据库中常用,主要原因是对于树结构的查询,程序加载子节点都需要进行一次磁盘IO,磁盘IO 比 读内存IO要慢 所以多叉的B+ tree可以减少I/O的次数
参考:b站视频 “索引”的原理 4min 建议感兴趣的可以再查询进阶数据结构书籍了解 实际上代码是直接openvdb库直接构建的
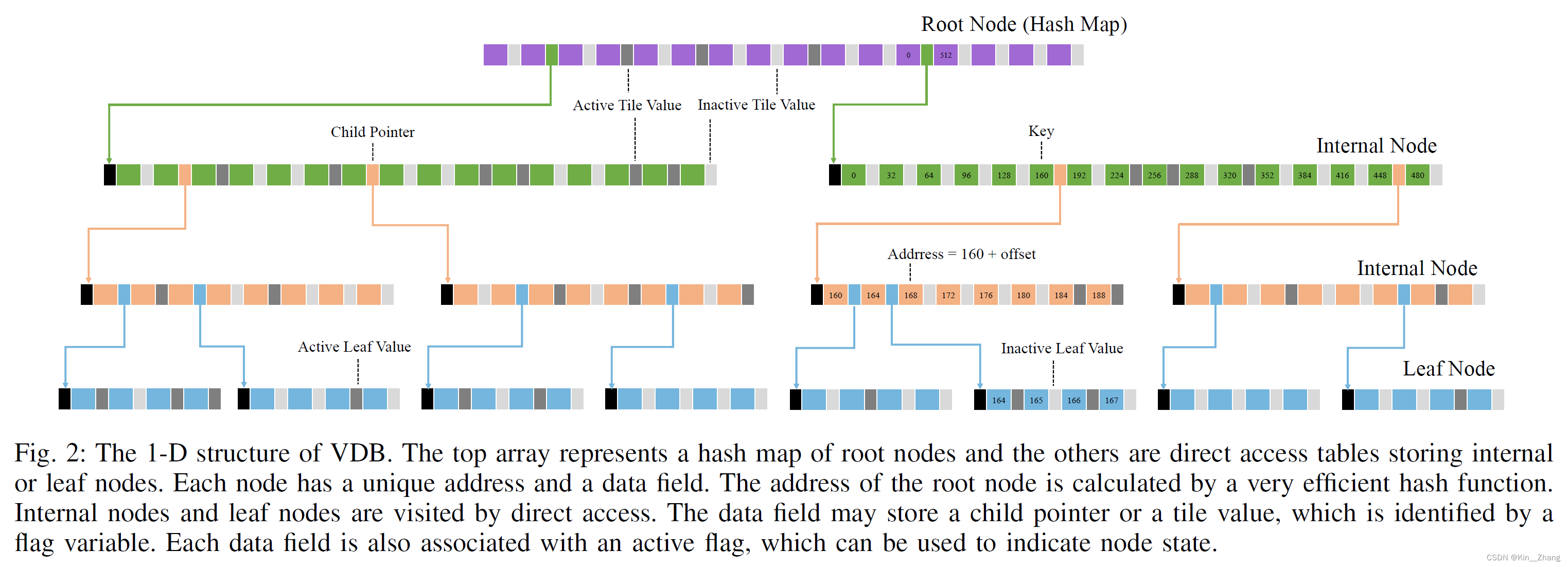
- VDB: the branching factors are very large and variable, making the tree shallow and wide
- Octree-based: deep and narrow, thus not fast enough for distance transform.
2.2 VDB-EDT
感觉这个看文中会比较好 主要是针对伪代码的解释
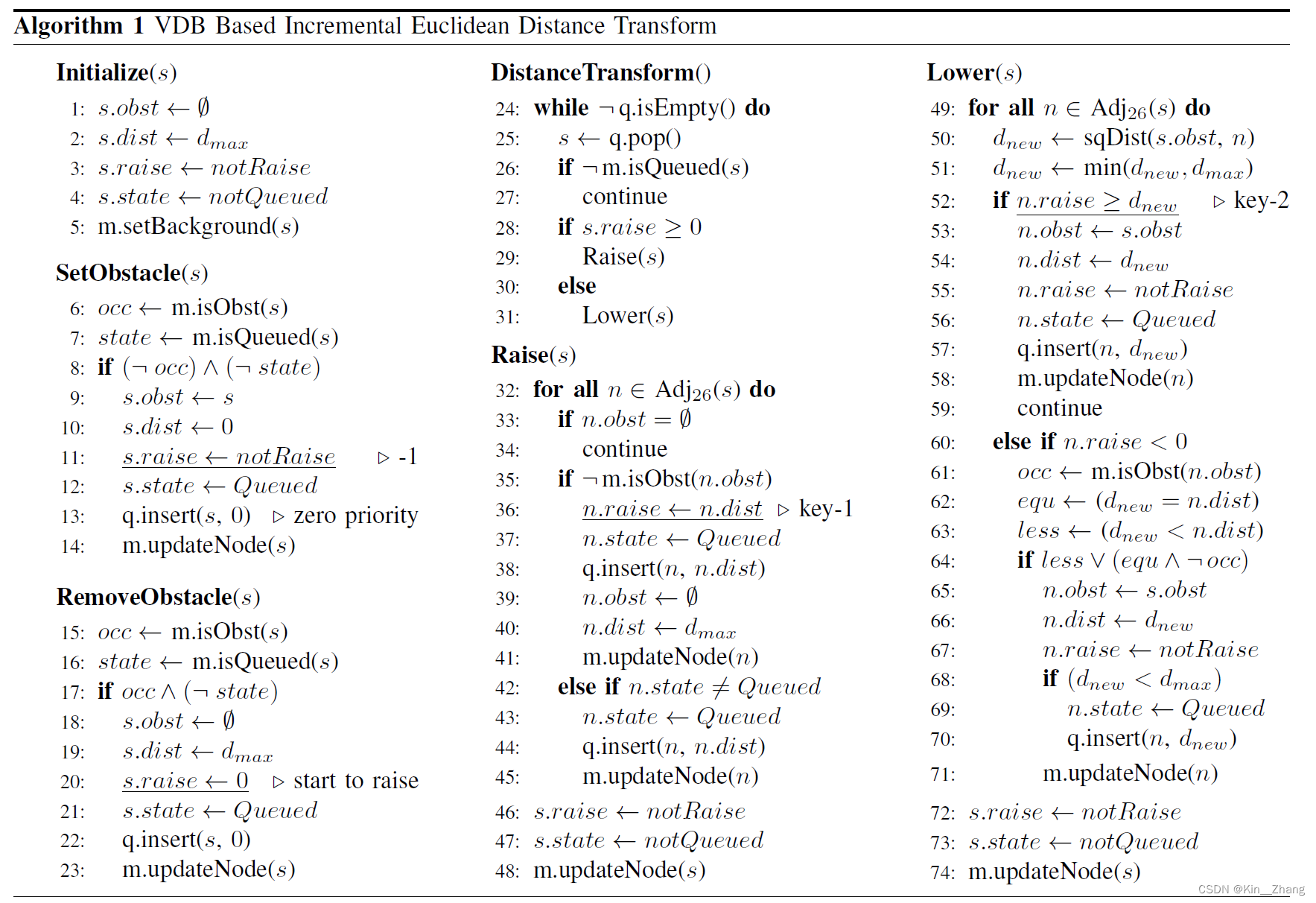
The distance field represented by VDB is essentially a sparse volumetric grid, and each field point is represented by a grid cell s indexed by a 3-D coordinate.

更新部分code:
void VDBMap::update_occmap(FloatGrid::Ptr grid_map, const tf::Vector3 &origin, XYZCloud::Ptr xyz)
{
auto grid_acc = grid_map->getAccessor();
auto tfm = grid_map->transform();
openvdb::Vec3d origin3d(origin.x(), origin.y(), origin.z());
openvdb::Vec3d origin_ijk = grid_map->worldToIndex(origin3d);
for (auto point = xyz->begin(); point != xyz->end(); ++point) {
openvdb::Vec3d p_xyz(point->x, point->y, point->z);
openvdb::Vec3d p_ijk = grid_map->worldToIndex(p_xyz);
openvdb::Vec3d dir(p_ijk - origin_ijk);
double range = dir.length();
dir.normalize();
// Note: real sensor range should stractly larger than sensor_range
bool truncated = false;
openvdb::math::Ray<double> ray(origin_ijk, dir);
// openvdb::math::DDA<openvdb::math::Ray<double>, 0> dda(ray, 0., std::min(SENSOR_RANGE, range));
// if (START_RANGE >= std::min(SENSOR_RANGE, range)){
// continue;
// }
openvdb::math::DDA<openvdb::math::Ray<double>, 0> dda(ray, 0, std::min(SENSOR_RANGE, range));
// decrease occupancy
do {
openvdb::Coord ijk(dda.voxel());
float ll_old;
bool isKnown = grid_acc.probeValue(ijk, ll_old);
float ll_new = std::max(L_MIN, ll_old+L_FREE);
if(!isKnown){
grid_distance_->dist_acc_->setValueOn(ijk);
} // unknown -> free -> EDT initialize
else if(ll_old >= 0 && ll_new < 0){
grid_distance_->removeObstacle(ijk);
} // occupied -> free -> EDT RemoveObstacle
grid_acc.setValueOn(ijk, ll_new);
dda.step();
} while (dda.time() < dda.maxTime());
// increase occupancy
if ((!truncated) && (range <= SENSOR_RANGE)){
for (int i=0; i < HIT_THICKNESS; ++i) {
openvdb::Coord ijk(dda.voxel());
float ll_old;
bool isKnown = grid_acc.probeValue(ijk, ll_old);
float ll_new = std::min(L_MAX, ll_old+L_OCCU);
if(!isKnown){
grid_distance_->dist_acc_->setValueOn(ijk);
} // unknown -> occupied -> EDT SetObstacle
else if(ll_old < 0 && ll_new >= 0){
grid_distance_->setObstacle(ijk);
} // free -> occupied -> EDT SetObstacle
grid_acc.setValueOn(ijk, ll_new);
dda.step();
}
} // process obstacle
} // end inserting
/* commit changes to the open queue*/
}
3. 实验及结果
各个阈值对时间的影响,其中对比了几个baseline方法如下:
- A commonly-used general EDT [18] (denoted without -Ex suffix)
- the proposed algorithm (denoted with -Ex suffix).
- Two implementations based on the array and VDB data structures to compare their memory efficiency (denoted with Arr- and VDB- prefix, respectively)
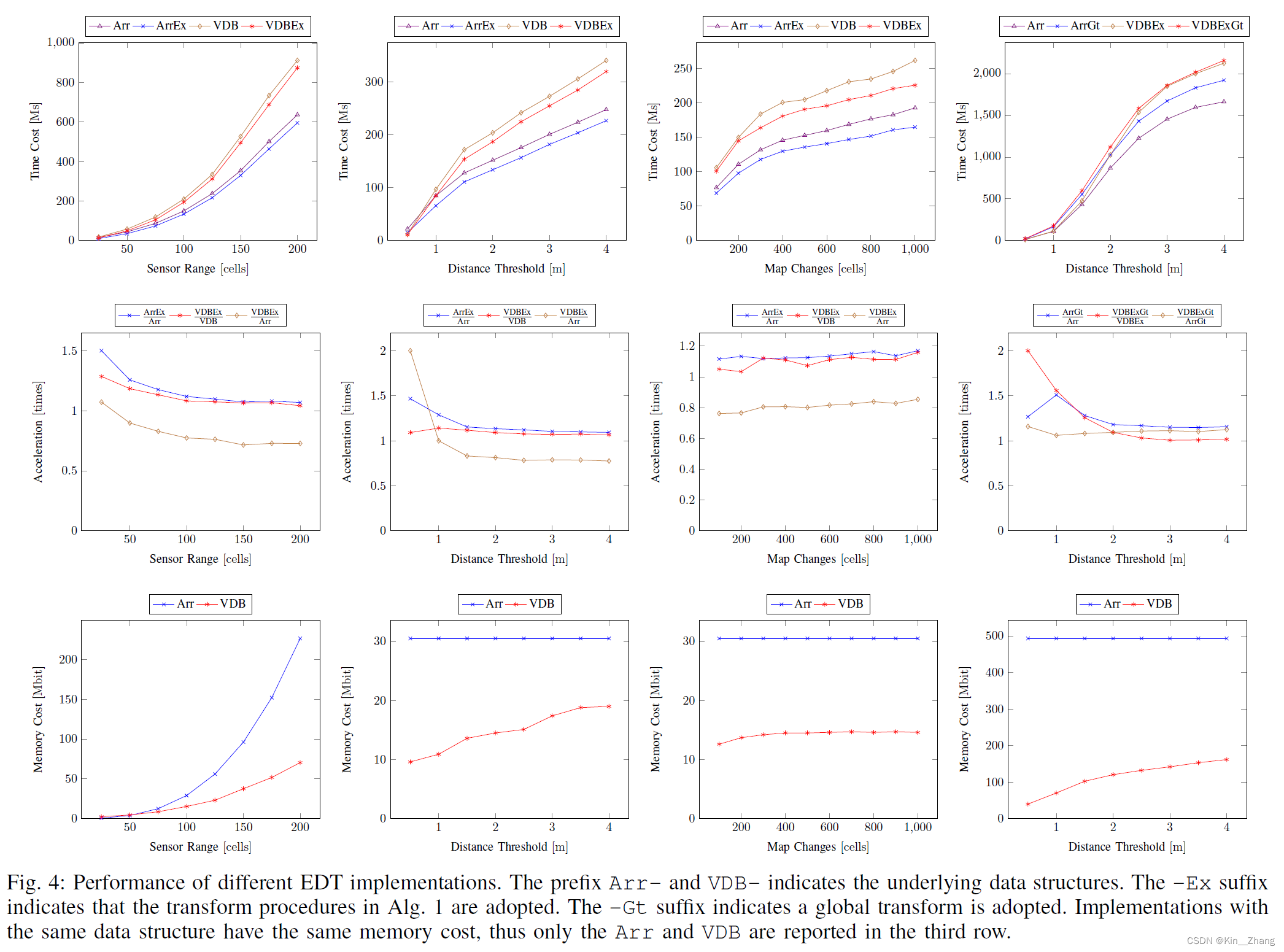
可以看到 在时间上-Ex 的耗时都比无Ex的快,虽然VDB的速度上比arr的还是慢了一点 10%-25%,但是从memeory cost上确实节约了30-60%的 Herein, the increment of time cost is inevitable, as VDB is based on tree structures and has a slower random access speed than the array-based implementation
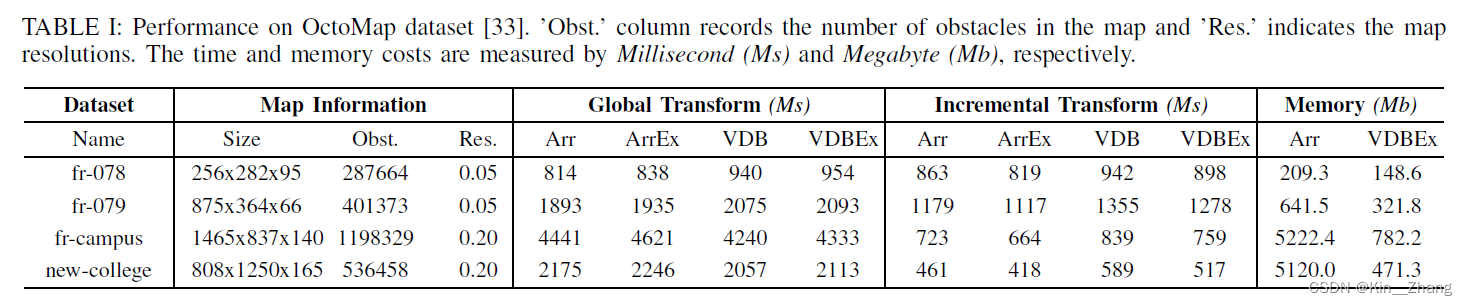
同样表格是在数据集上的表现,在global 和 incremental transform会慢一点,但是在memory上省了不少
还有一个就是无人机在仿真环境中建图并有planning效果:

4. Conclusion
提出了一种VDB-EDT算法去解决 distance transform problem. The algorithm is implemented based on a memory-efficient data structure and a novel distance transform procedure, which significantly improves the memory and runtime efficiency of EDTs.
这项工作突破了通常的EDT的限制,也可以为后面基于VDB-based mapping, distance transform and safe motion planning的研究进行使用
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh
【论文阅读】ICRA2021: VDB-EDT An Efficient Euclidean Distance Transform Algorithm Based on VDB Data Struct的更多相关文章
- 【论文阅读】ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet: An Extremely Efficient Convolutional Neural Network for MobileDevices
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 【论文阅读】An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches
懒得转成文字再写一遍了,直接把做过的PPT放出来吧. 论文连接:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1804.09003v1. ...
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space 2018-01-04 ...
- 论文阅读-Temporal Phenotyping from Longitudinal Electronic Health Records: A Graph Based Framework
- 论文阅读:《Bag of Tricks for Efficient Text Classification》
论文阅读:<Bag of Tricks for Efficient Text Classification> 2018-04-25 11:22:29 卓寿杰_SoulJoy 阅读数 954 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
随机推荐
- 三:瑞芯微OK3399-C开发板
场景一 给广告机加上一双智慧的眼睛,时刻关注这经过自己面前的每一个人,把他(她)们的性别.年龄.胖瘦.着装风格.经过频次.观看广告的时间.每个广告观看的人数等等一一记录下来,为广告机运营商.广告创业设 ...
- 如何在局域网内两台电脑上进行webapi的在线调试
原文地址:https://www.zhaimaojun.top/Note/5475298(我自己的博客) 局域网内WebApi的远程调试方法: 第一步:管理员方式运行Vs并打开需要运行的项目,如果已经 ...
- ls的输出格式
在Linux中,如果在一个目录下面执行ls -al命令,输出格式如下: ls -al总共输出7列,下面对每一列进行说明. 第一列表示这个文件的权限与类型,它总共有10位,每个位的作用如下图所示: 其中 ...
- 🔥🔥httpsok-谷歌免费SSL证书如何申请
httpsok-谷歌免费SSL证书如何申请 使用场景: 部署CDN证书.OSS云存储证书 证书类型: 单域名 多域名 通配符域名 混合域名 证书厂商: ZeroSSL Let's Encrypt Go ...
- go 从入门到了解
一,GO的安装与配置 官网:https://golang.org/dl/ 镜像:https://golang.google.cn/dl/ 1,GOPATH GOPATH在windows上的默认值:%U ...
- tcc-transaction源码详解
更多优秀博文,请关注博主的个人博客:听到微笑的博客 本文主要介绍TCC的原理,以及从代码的角度上分析如何实现的:不涉及具体使用示例.本文通过分析tcc-transaction源码带大家了解TCC分布式 ...
- wpf 动画显示隐藏_[UWP]用Win2D和CompositionAPI实现文字的发光效果,并制作动画
weixin_39880899于 2020-12-11 09:26:23 发布 阅读量521 收藏 点赞数 文章标签: wpf 动画显示隐藏 1. 成果 献祭了周末的晚上,成功召唤出了上面的番茄钟 ...
- .net C# System.Text.Json 如何将 string类型的“true”转换为布尔值 解决方案
直接上解决方法的代码 先定义一个转换顺,代码如下: public sealed class AnhBoolConverter : JsonConverter<bool?> { public ...
- MySQL学习笔记-数据查询语言
SQL-数据查询语言(DQL) DQL语法结构 #DQL语句编写顺序 select 字段列表 from 表名列表 where 条件列表 group by 分组字段列表 having 分组后条件列表 o ...
- Linux网络驱动
1 简介 1.1 硬件说明 嵌入式网络硬件分为:MAC和PHY.MAC一般时SOC内置,PHY是外部器件. (1)SOC内部没有MAC 如果SOC内部没有网络MAC外设,可使用外置的MAC,一般外置的 ...