【赵渝强老师】Kafka的持久化

一、Kafka持久化概述
Kakfa 依赖文件系统来存储和缓存消息。对于硬盘的传统观念是硬盘总是很慢,基于文件系统的架构能否提供优异的性能?实际上硬盘的快慢完全取决于使用方式。同时 Kafka 基于 JVM 内存有以下缺点:
- 对象的内存开销非常高,通常是要存储的数据的两倍甚至更高
- 随着堆内数据的增加,GC的速度越来越慢
实际上磁盘线性写入的性能远远大于任意位置写的性能,线性读写由操作系统进行了大量优化(read-ahead、write-behind 等技术),甚至比随机的内存读写更快。所以与常见的数据缓存在内存中然后刷到硬盘的设计不同,Kafka 直接将数据写到了文件系统的日志中:
- 写操作:将数据顺序追加到文件中
- 读操作:从文件中读取
这样实现的好处:
- 读操作不会阻塞写操作和其他操作,数据大小不对性能产生影响
- 硬盘空间相对于内存空间容量限制更小
- 线性访问磁盘,速度快,可以保存更长的时间,更稳定。
二、Kafka的持久化原理解析
一个 Topic 被分成多 Partition,每个 Partition 在存储层面是一个 append-only 日志文件,属于一个 Partition 的消息都会被直接追加到日志文件的尾部,每条消息在文件中的位置称为 offset(偏移量)。
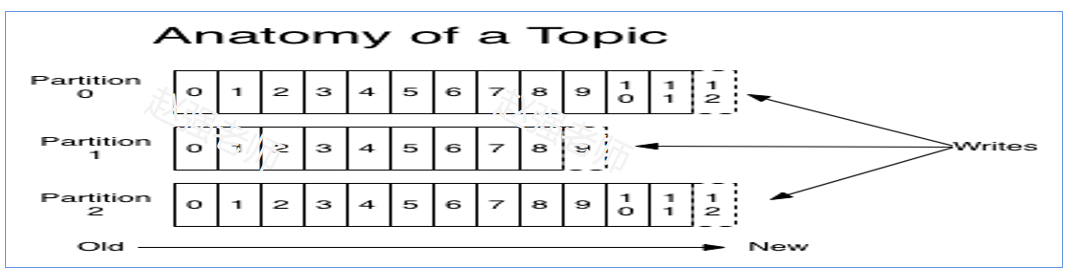
如下图所示,我们之前创建了mytopic1,具有三个分区。我们可以到对应的日志目录下进行查看。

Kafka日志分为index与log(如上图所示),两个成对出现:index文件存储元数据,log存储消息。索引文件元数据指向对应log文件中message的迁移地址;例如2,128指log文件的第2条数据,偏移地址为128;而物理地址(在index文件中指定)+ 偏移地址可以定位到消息。
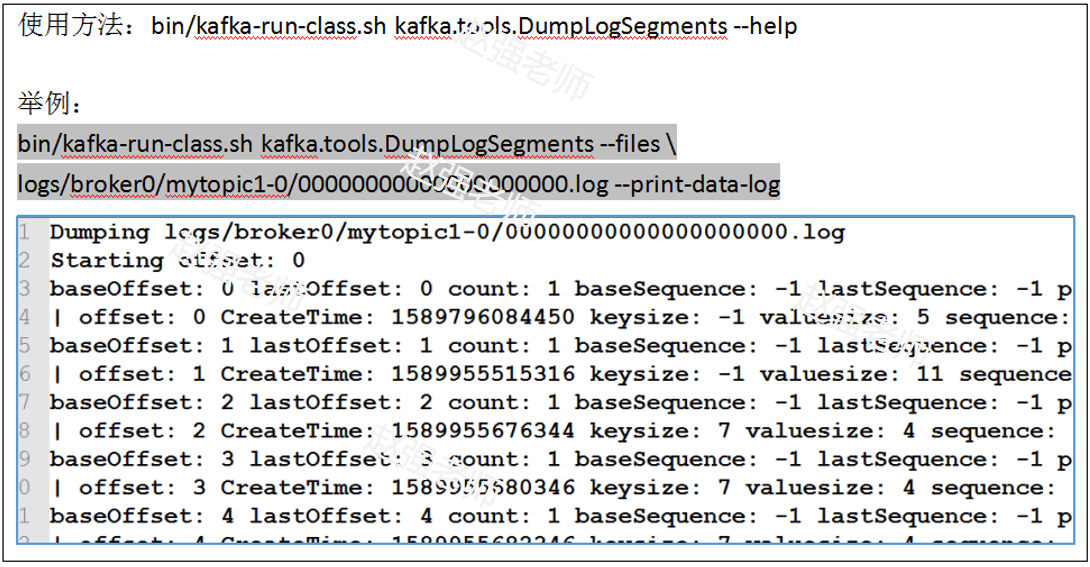
我们可以使用Kafka自带的工具来查看log日志文件中的数据信息:
【赵渝强老师】Kafka的持久化的更多相关文章
- 201871010136—赵艳强《面向对象程序设计(java)》第十三周学习总结
201871010136—赵艳强<面向对象程序设计(java)>第十三周学习总结 博文正文开头格式:(2分) 项目 内容 <面向对象程序设计(java)> https:// ...
- 201871010136 -赵艳强《面向对象程序设计(java)》第十六周学习总结
201871010136-赵艳强<面向对象程序设计(java)>第十六周学习总结 项目 内容 这个作业属于哪个课程 <任课教师博客主页链接>https://www.cnbl ...
- Kafka 温故(三):Kafka的内部机制深入(持久化,分布式,通讯协议)
一.Kafka的持久化 1.数据持久化: 发现线性的访问磁盘(即:按顺序的访问磁盘),很多时候比随机的内存访问快得多,而且有利于持久化: 传统的使用内存做为磁盘的缓存 Kafk ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- TOP100summit2017:网易云通信与视频CTO赵加雨:外力推动下系统架构的4个变化趋势
壹佰案例:很荣幸邀请到您成为第六届壹佰案例峰会架构专场的联席主席,您曾深度参与Cisco Jabber,Webex Meeting, Cisco Spark等多项分布式实时通信类产品的架构与研发, ...
- 初始kafka
kafka 简介 Kafka是Linkedin于2010年12月份开源的消息系统 一种分布式的.基于发布/订阅的消息系统 ,另外提供数据分布式缓存功能 特点 消息持久化:通过O(1)的磁盘数据结构提供 ...
- kafka的简单理解
经典组合: Flume+Kafka+Storm+HDFS/HBase Flume:分布式采集 Kafka:分布式缓存 Kafka简介: 一种分布式的.基于发布/订阅的消息系统(Scala编写的) Ka ...
- kafka知识点整理总结
kafka知识点整理总结 只不过是敷衍 2017-11-22 21:39:59 kafka知识点整理总结,以备不时之需. 为什么要使用消息系统: 解耦 并行 异步通信:想向队列中放入多少消息就放多少, ...
- kafka概述
kafka概述 Apache Kafka是一个开源 消息 系统,由Scala写成.是由Apache软件基金会开发的一个开源消息系统项目. Kafka最初是由LinkedIn开发,并于2011年初开源. ...
- Kafka学习(一)kafka指南(about云翻译)
kafka 权威指南中文版 问题导读 1. 为什么数据管道是数据驱动企业的一个关键组成部分? 2. 发布/订阅消息的概念及其重要性是什么? 第一章 初识 kafka 企业是由数据驱动的.我们获取信息, ...
随机推荐
- mysql面试汇总
最近一直在关注mysql方面的面试题目,并且从最近的面试情况来看,mysql在java后端的面试中,肯定是必问的题目,所以这里有必要对这块的内容进行总结,大家可以根据下面的导图进行重点复习, 引擎 1 ...
- 缓存框架 Caffeine 的可视化探索与实践
作者:vivo 互联网服务器团队- Wang Zhi Caffeine 作为一个高性能的缓存框架而被大量使用.本文基于Caffeine已有的基础进行定制化开发实现可视化功能. 一.背景 Caffei ...
- TCP协议测试
TCP协议测试 首先需要测试TCP协议的连接 tcping命令是针对tcp监控的,也可以看到ping值,即使源地址禁ping也可以通过tcping来监控服务器网络状态,除了简单的ping之外,tcpi ...
- 【Git】03 撤销 & 版本回退
回退分为三种情况,每种情况对应了我们文件的存储区域 工作区 | 暂存区 | 版本区(当前分支) 1.文件可能存放在工作区,没有被Git追踪[红色标记状态] 2.文件可能已经添加到暂存区,没有被Git提 ...
- 如果美国断供中国所有的Intel和AMD芯片,国内各行各业会不会崩溃
说一个我个人观点,我认为如果国内完全没有X86芯片的供应,那么各行各业的发展会明显进入发展迟缓阶段,首先受影响的就是软件开发领域,因为没有新的芯片也就意味着袋电脑性能停滞或者倒退,那么开发出新的更耗资 ...
- 强化学习中atari游戏环境下帧的预处理操作
在网上找到一个Rainbow算法的代码(https://gitee.com/devilmaycry812839668/Rainbow),在里面找到了atari游戏环境下帧的预处理操作. 具体代码地址: ...
- mpi4py 官方使用手册
一直好奇mpi4py的使用手册在哪,找了好久最后在anaconda上发现了线索: https://anaconda.org/conda-forge/mpi4py Home: https://mpi4p ...
- 2023.4.12.汇报.pptx
6月份汇报想法 8月份写论文 ==========================================================
- Linux环境下配置vscode的C/C++ 的make编译环境(编写makefile方式)代码Demo版
以前写过同样话题下的图文版的,这里给出一个代码Demo版本,上一个图文版本参见: Linux环境下配置vscode的C/C++ 的make编译环境(编写makefile方式) ============ ...
- [NOI2007] 项链工厂 题解
前言 题目链接:洛谷:Hydro & bzoj. 题意简述 yzh 喜欢写 DS 题!你要维护一个环: 顺时针移动 \(k\) 位: 翻转 \(2 \sim n\): 交换 \(i\) 与 \ ...