七、Scrapy框架-案例1
1. 豆瓣民谣Top排名爬取
1.1 构建scrapy项目
安装Scrapy库
pip install scrapy
创建Scrapy项目
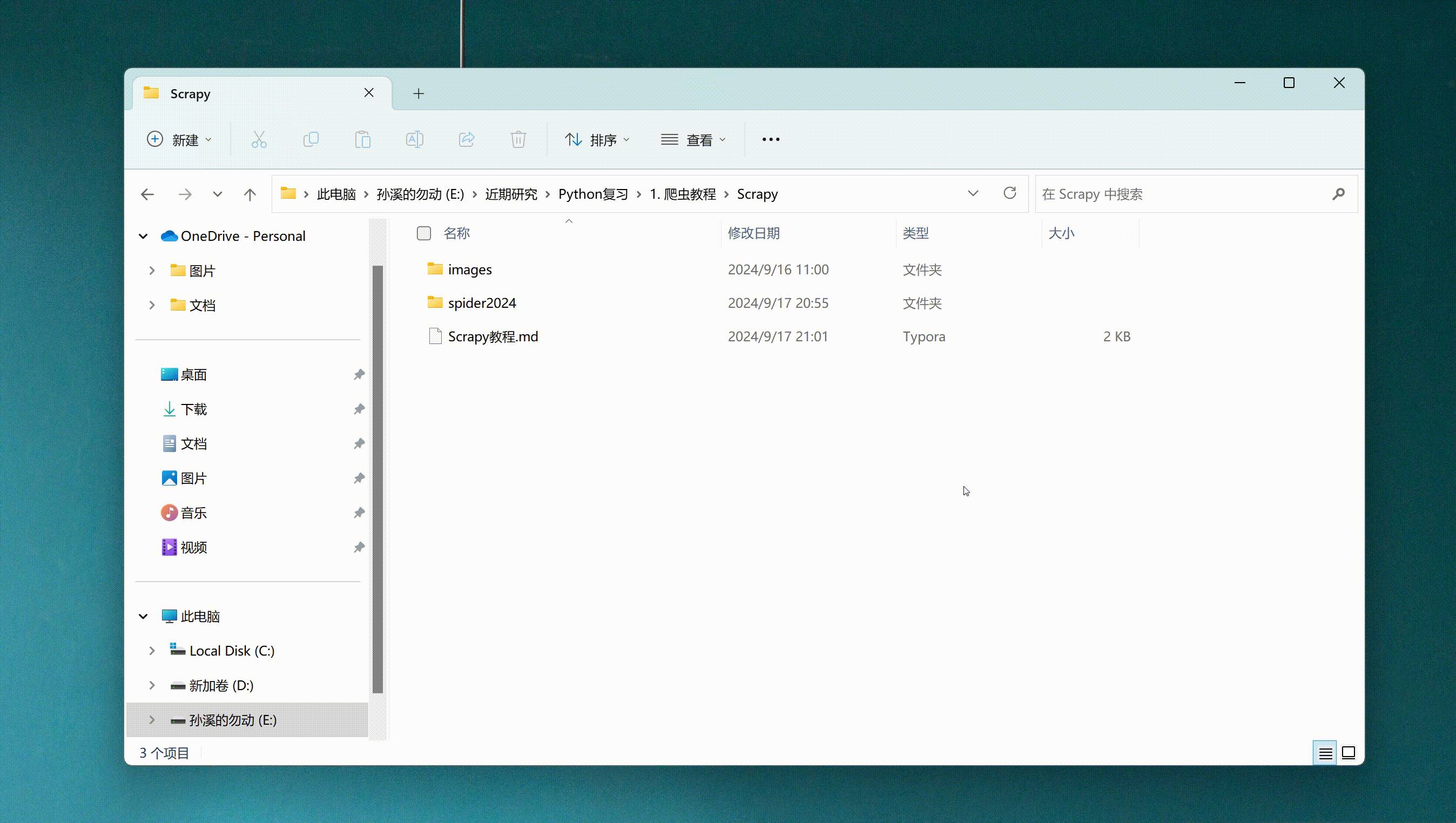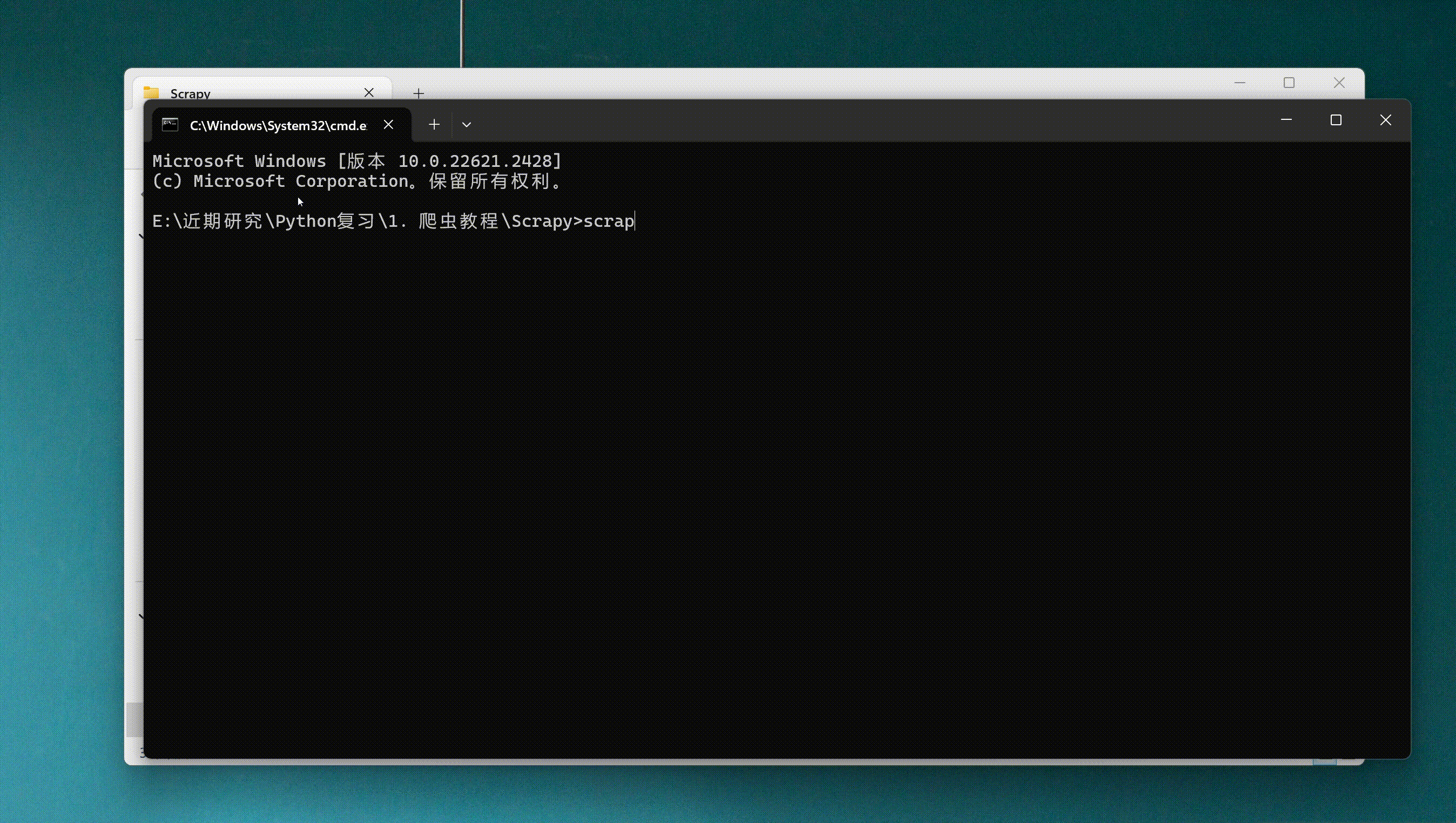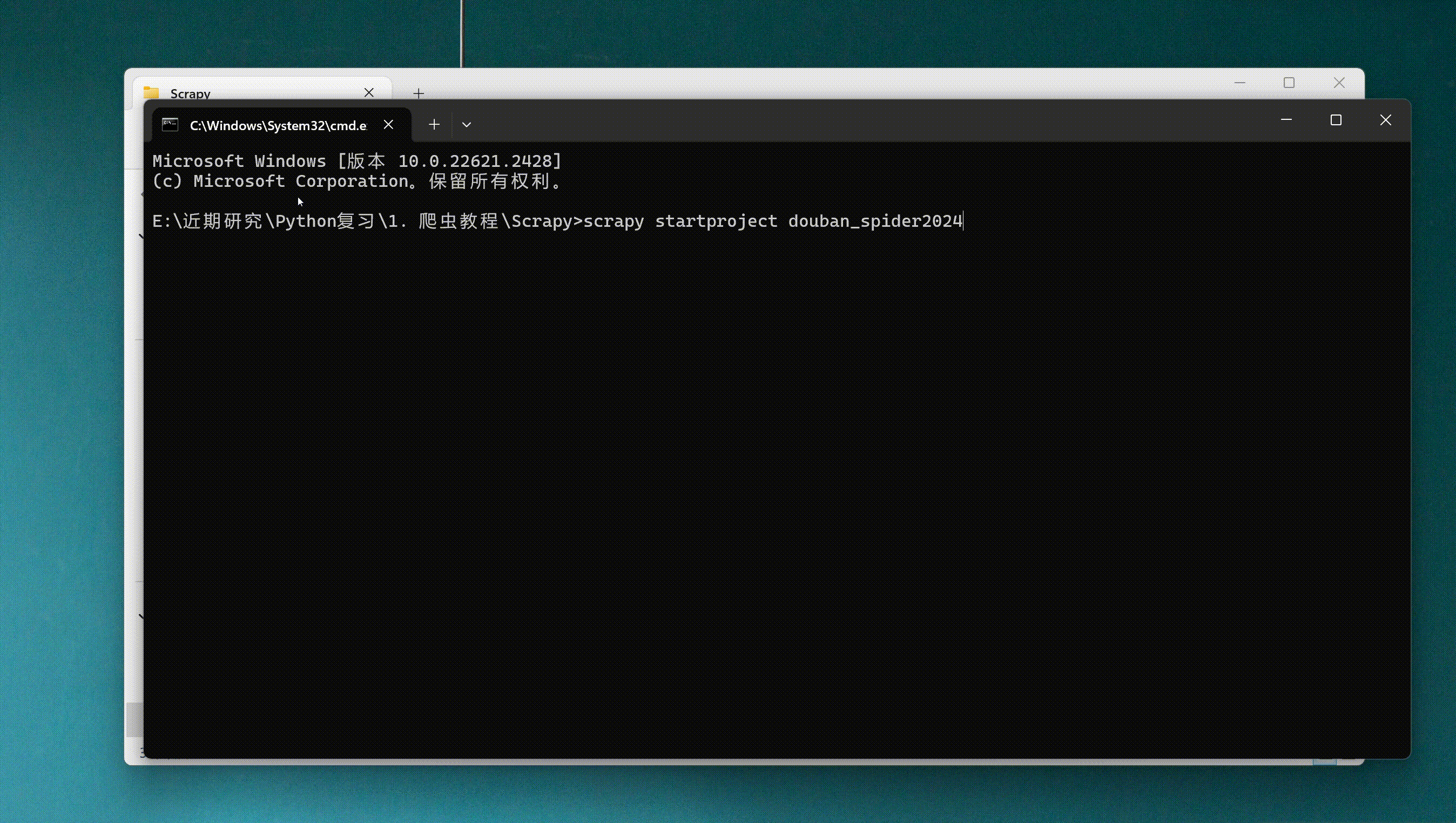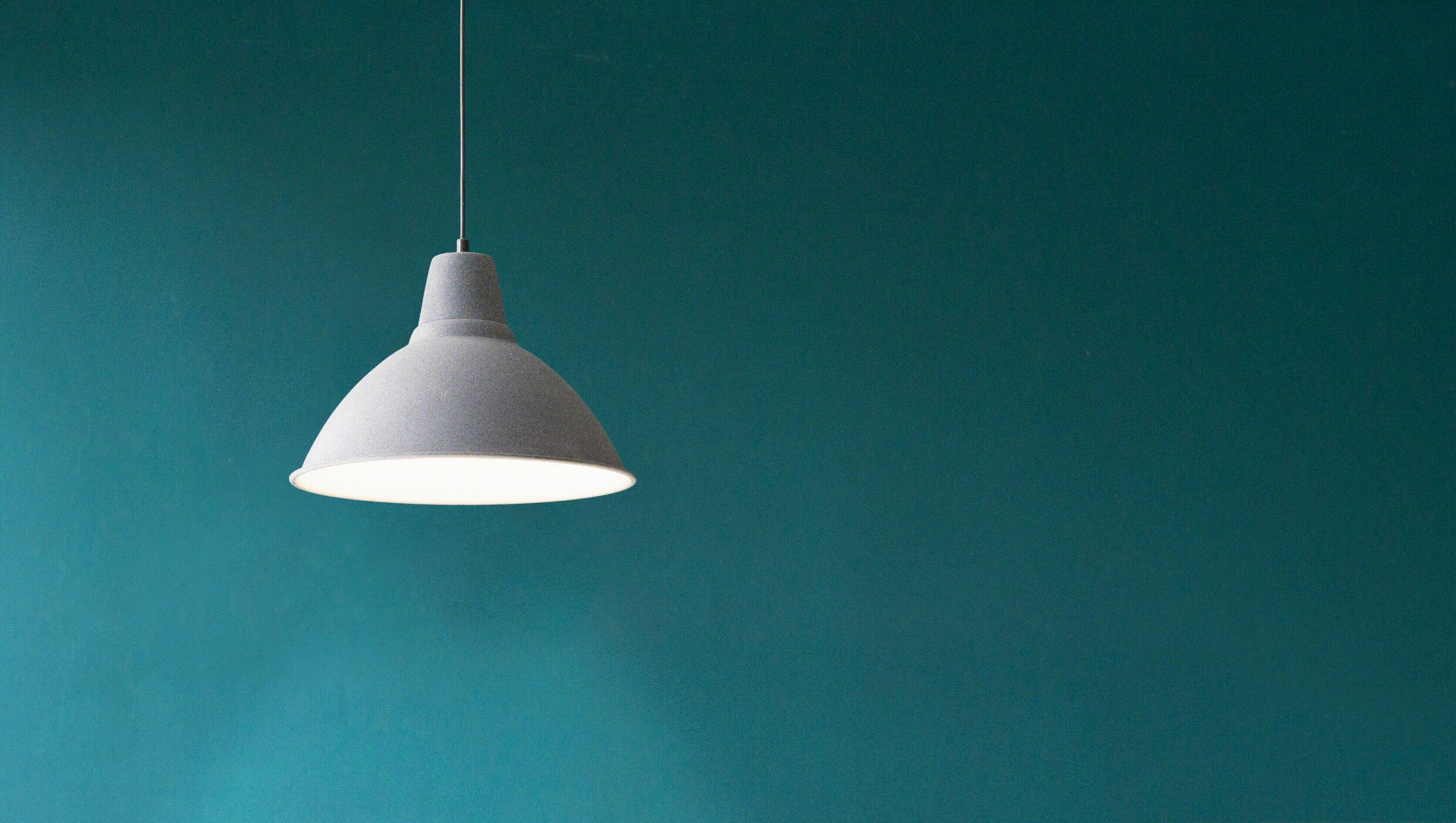
通过cmd进入命令窗口,执行命令scrapy startproject xxxx (xxxx为scrapy项目名),创建scrapy项目。
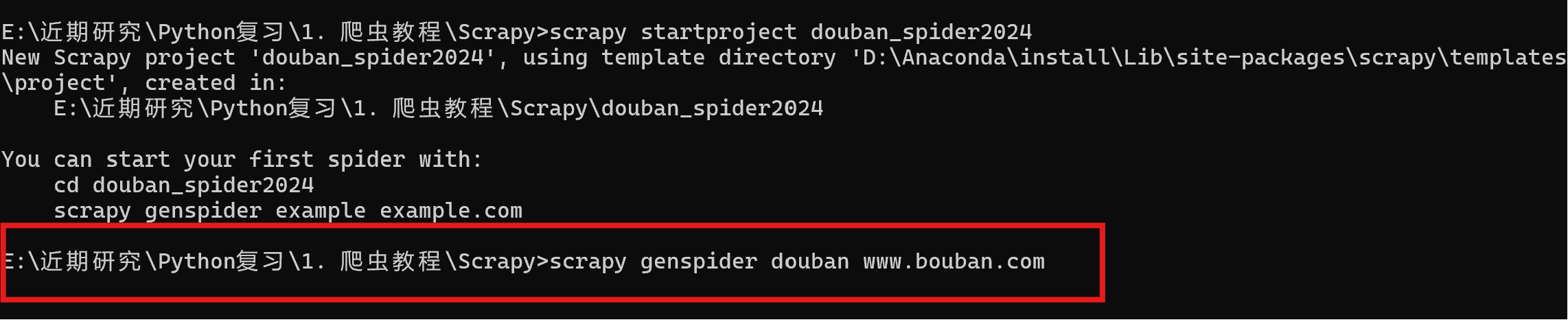
scrapy startproject douban_spider2024
创建爬虫项目
执行scrapy genspider xxx(爬虫名称) xxx(网址)创建爬虫项目。
scrapy genspider douban www.bouban.com
1.2 虚拟环境构建
使用Pycharm打开创建好的douban_spider2024文件夹,进入项目。
构建虚拟环境(venv)
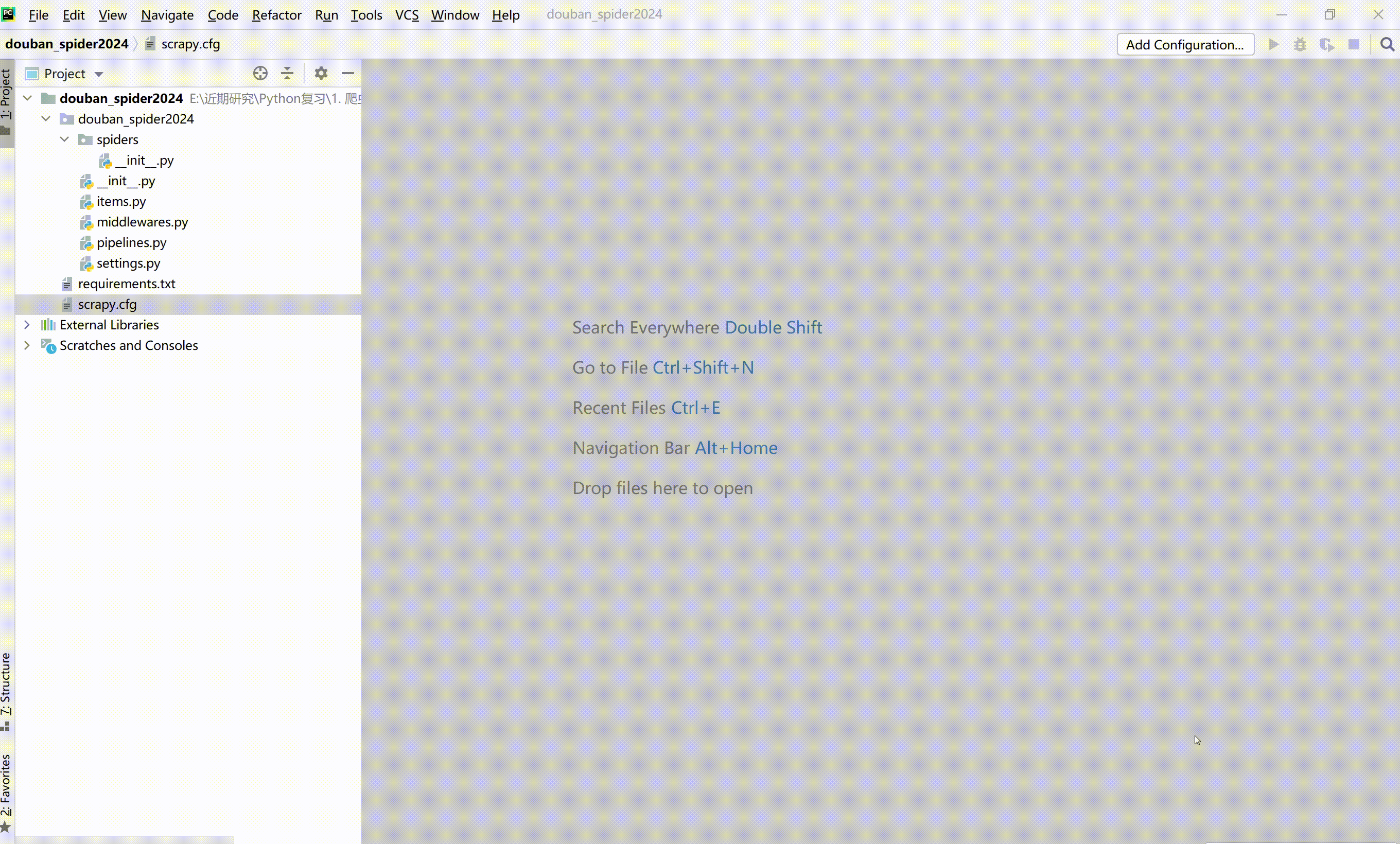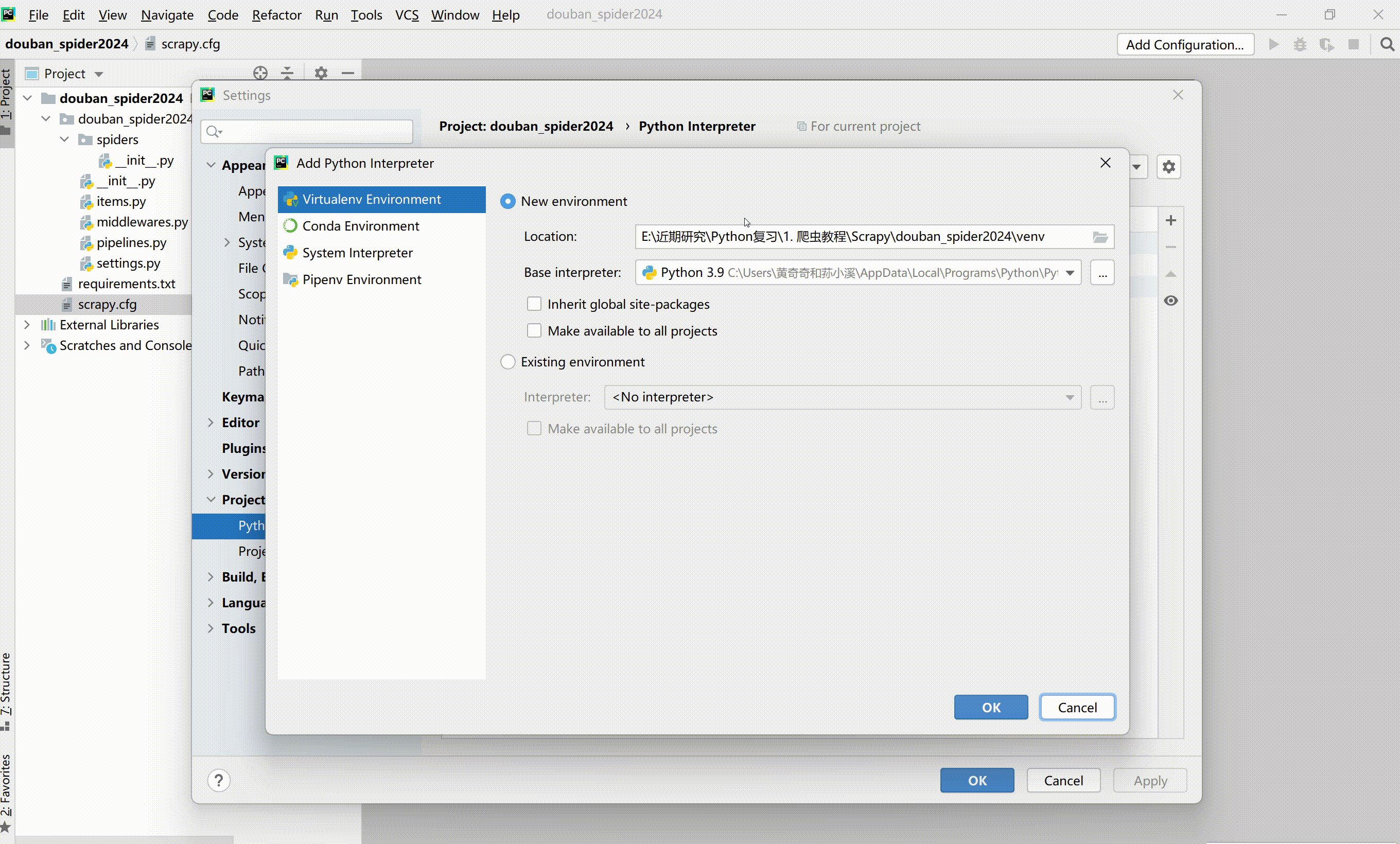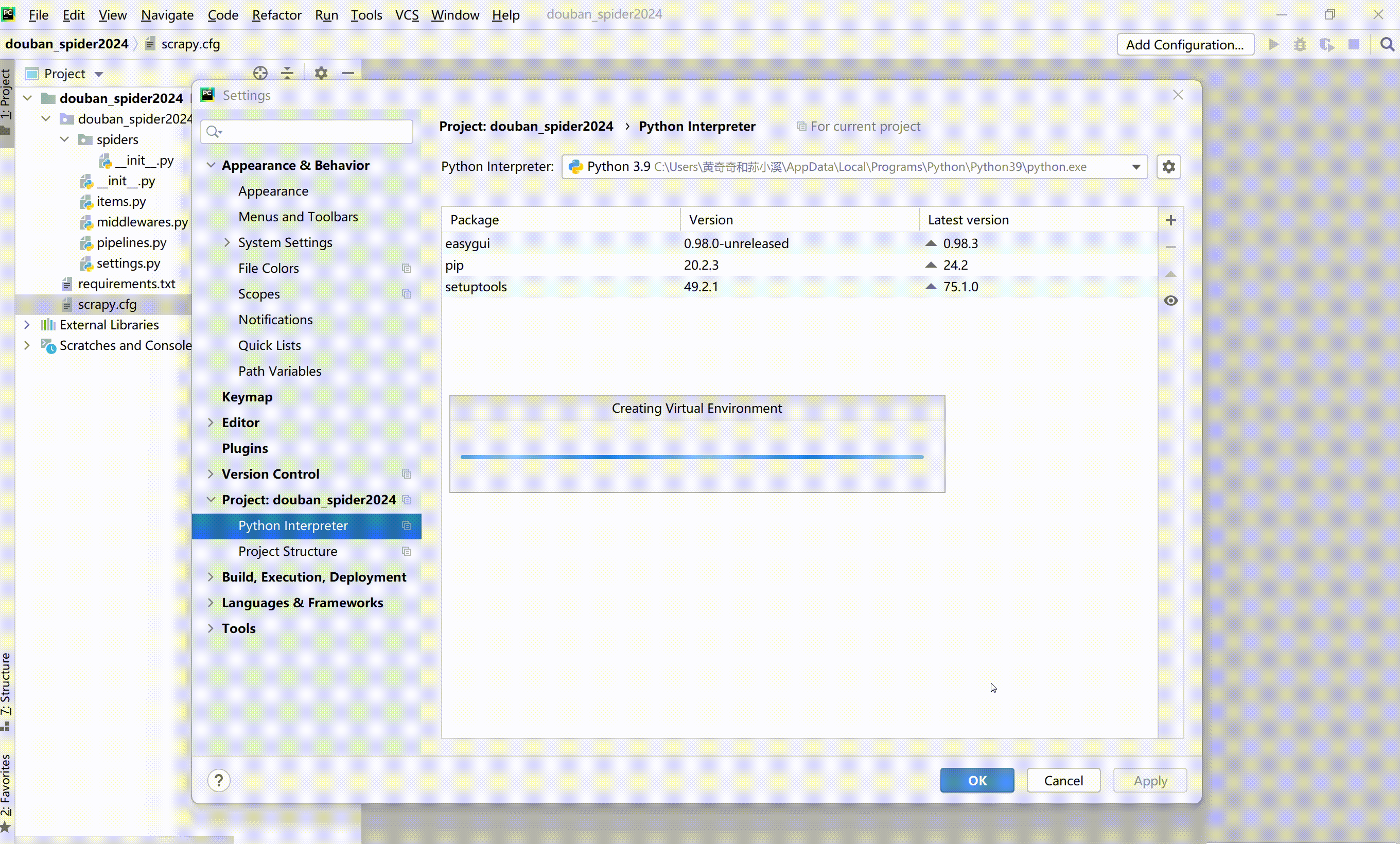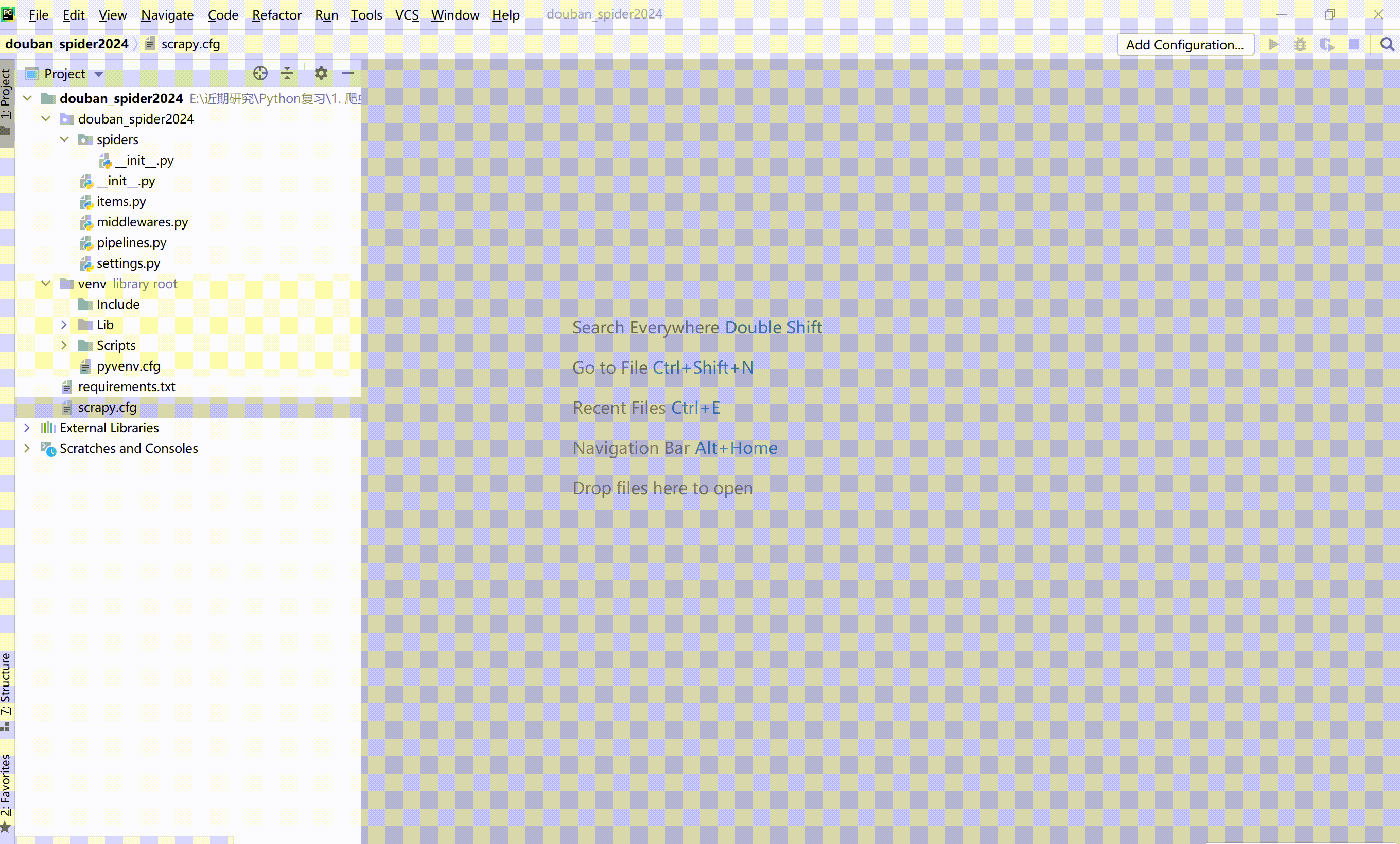
利用requirement.txt文件安装依赖库,也可以自己一个个pip安装。
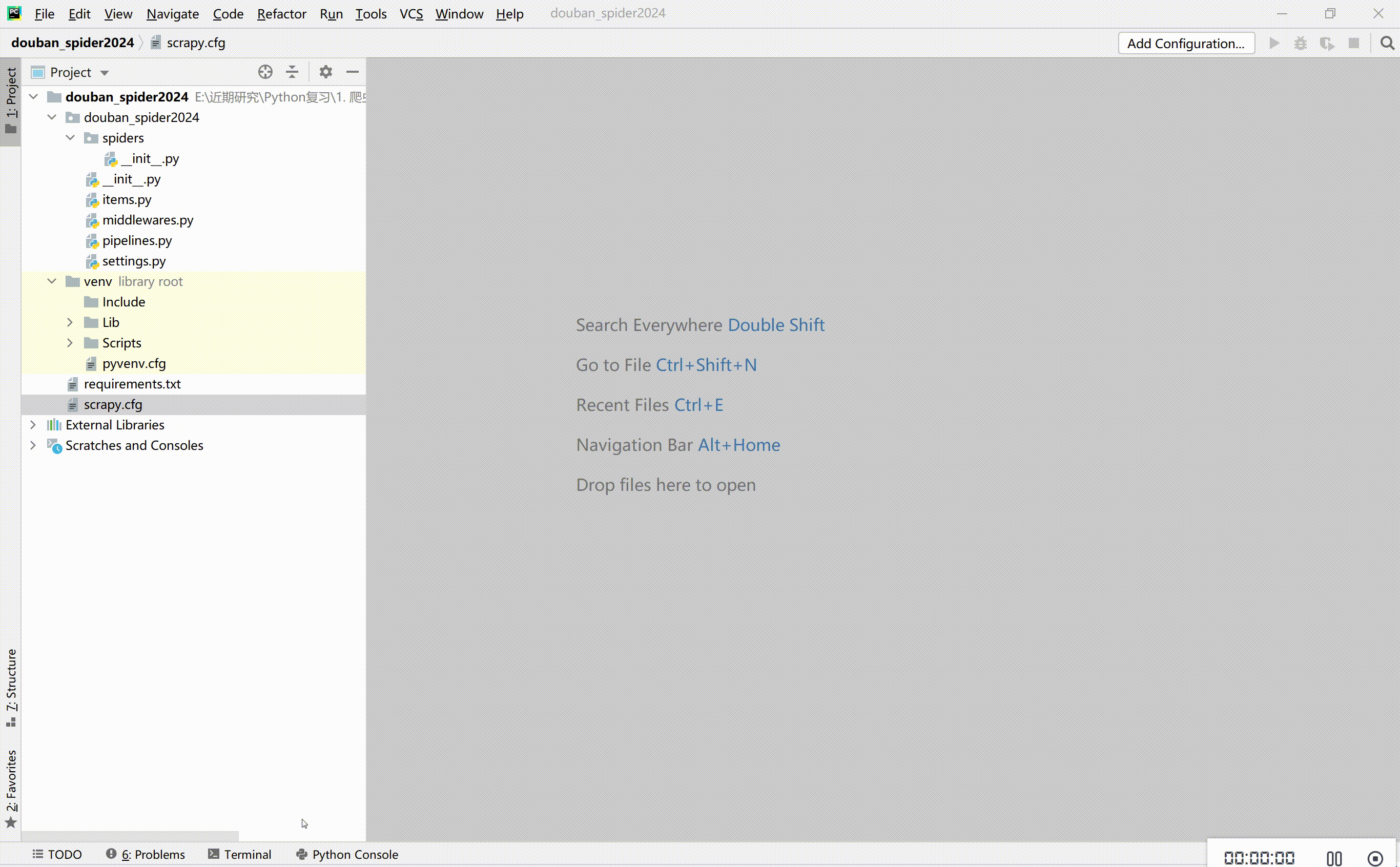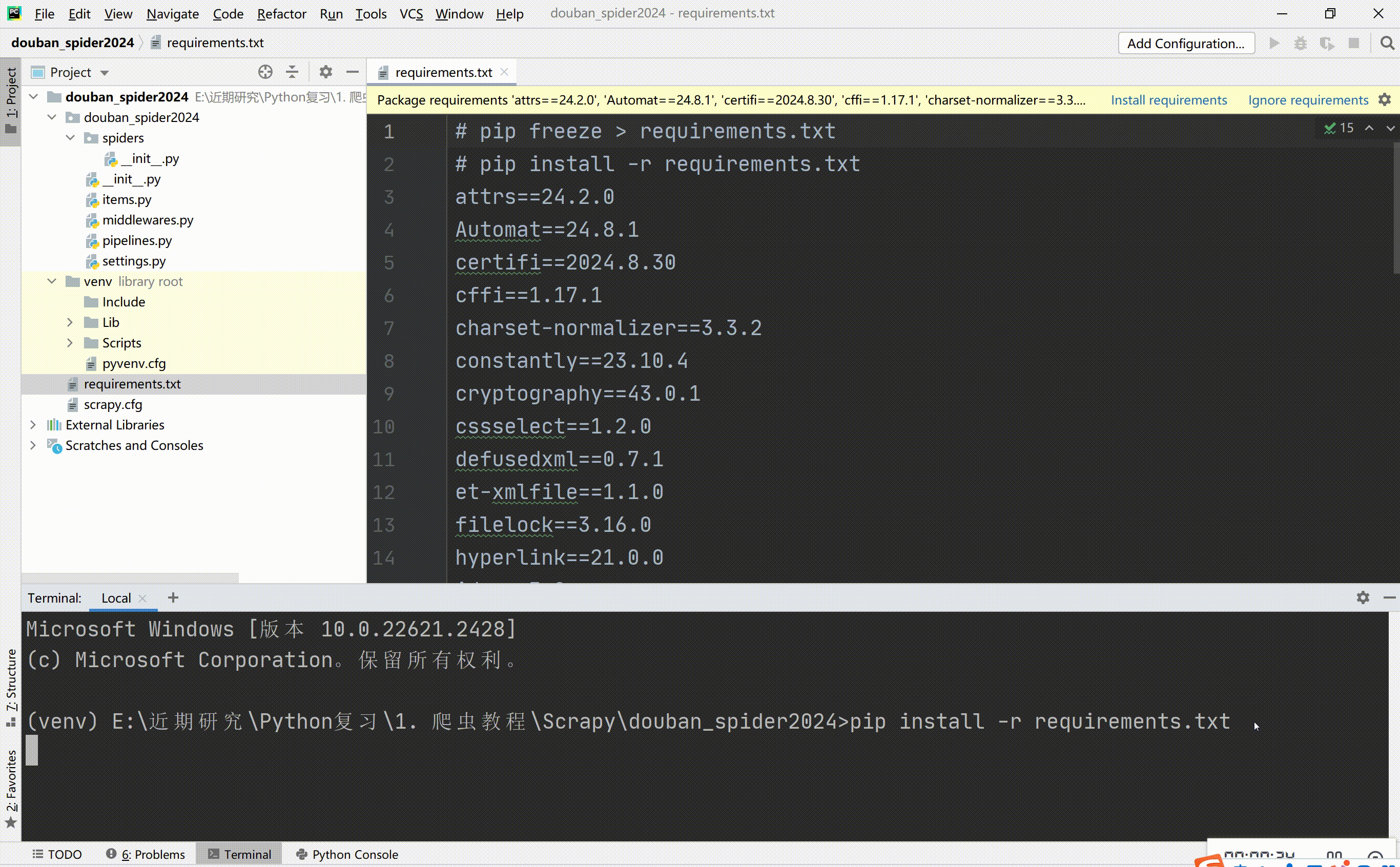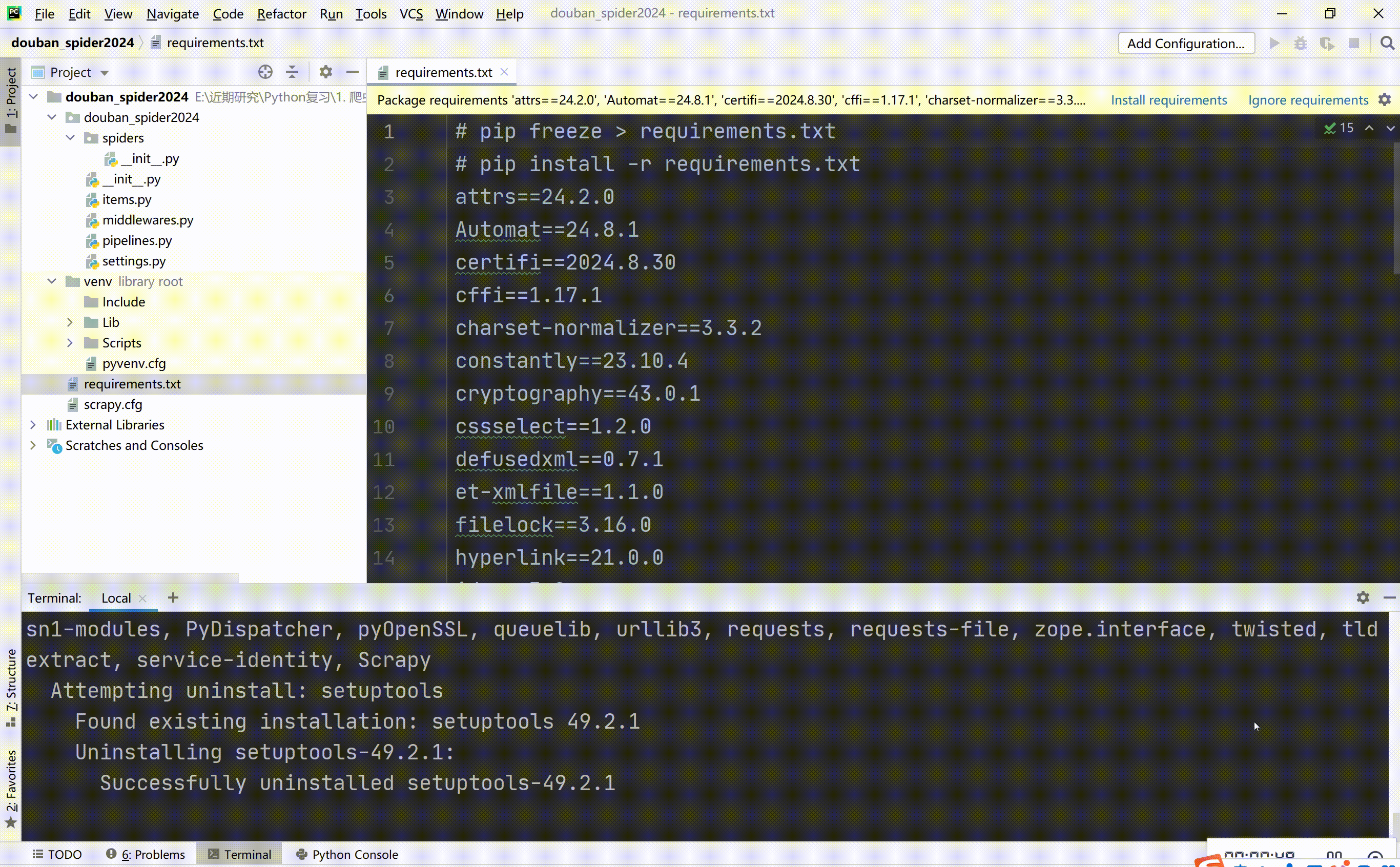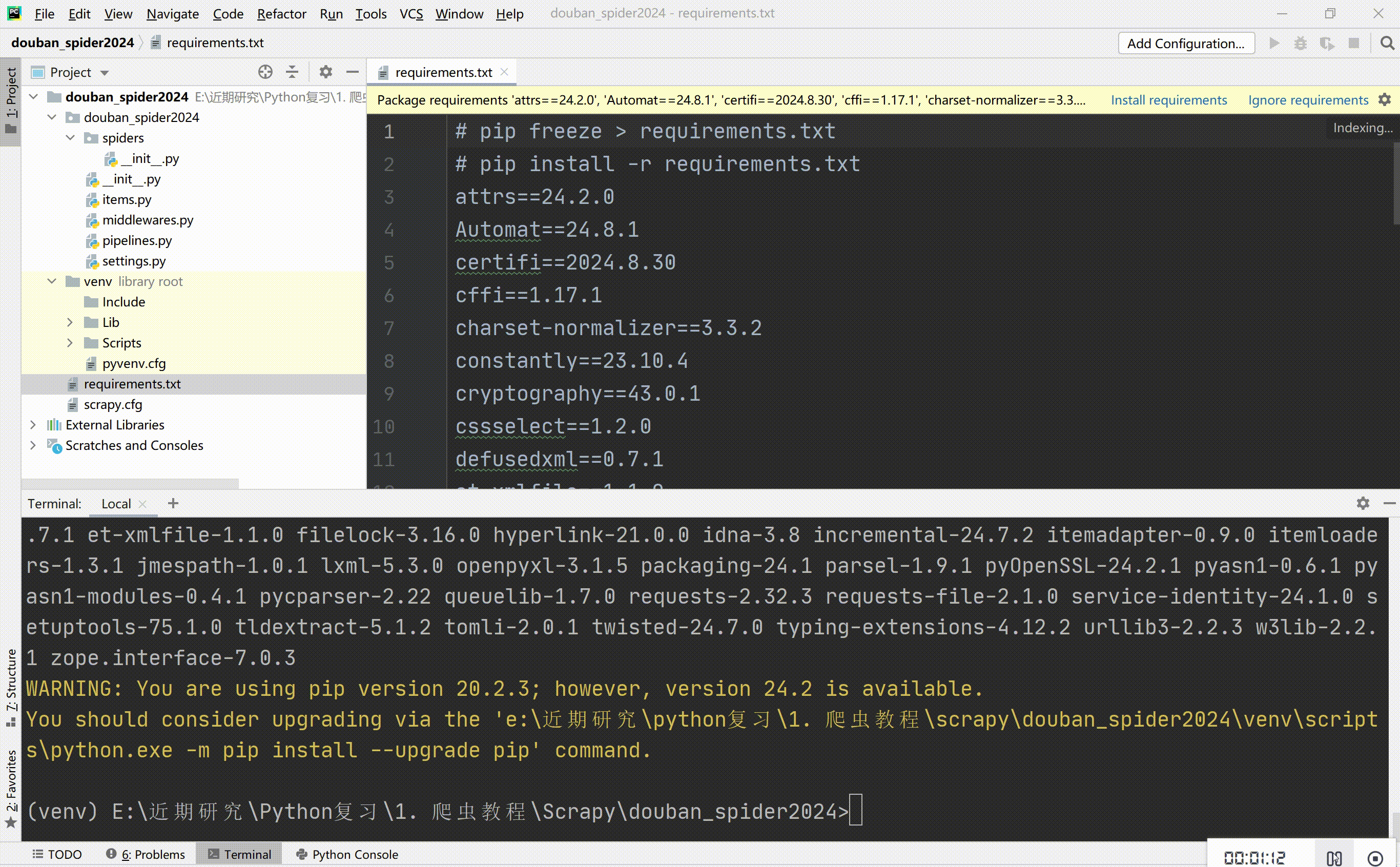
查看依赖库:pip freeze > requirements.txt
安装依赖库:pip install -r requirements.txt
1.3 主程序编写
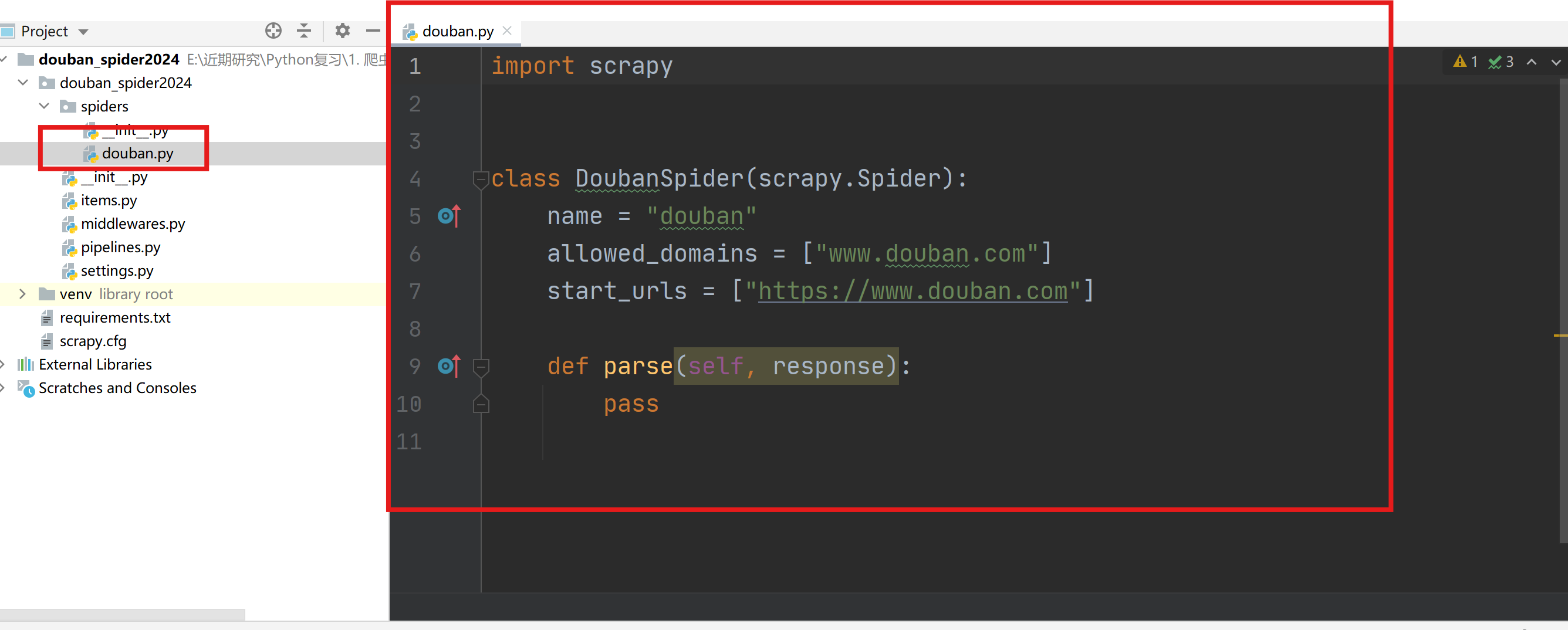
主程序(douban.py)用于编写解析页面的主要内容的代码。
通过start_requests函数获取urls列表,并用Request封装(需要配合在settings.py中启用下载中间件)。
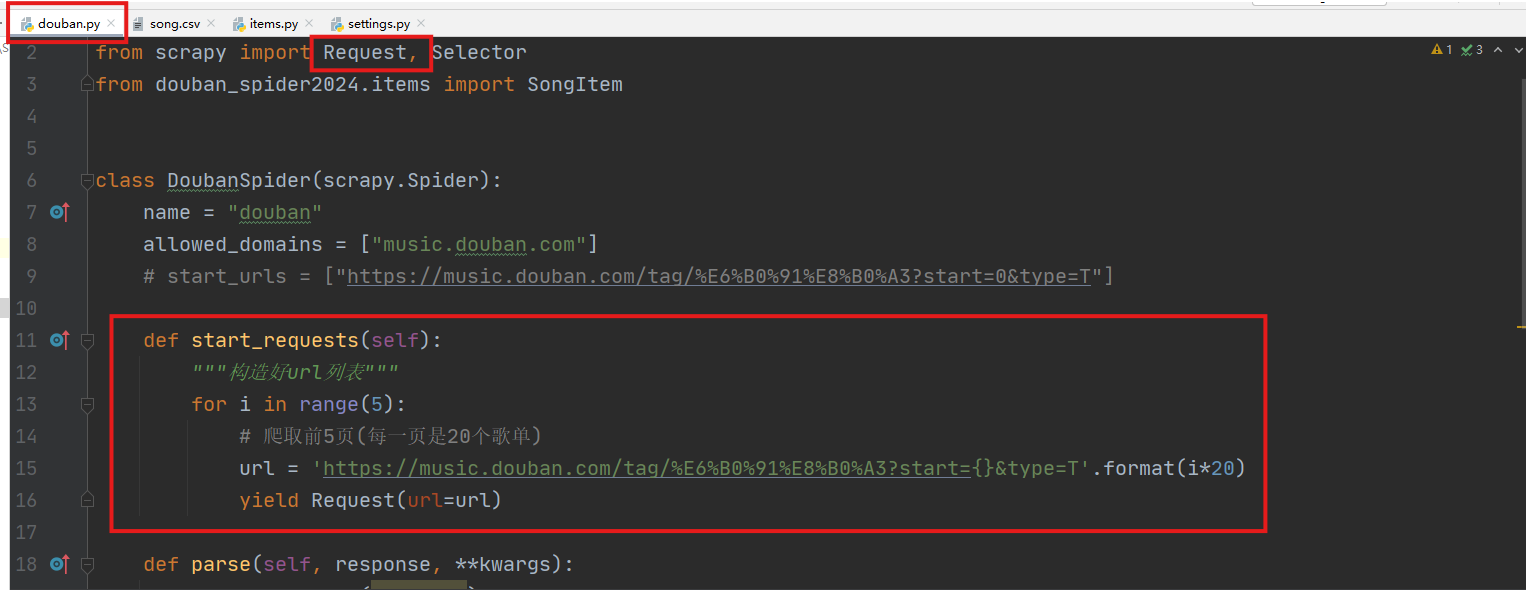
通过parse函数进行网页解析。

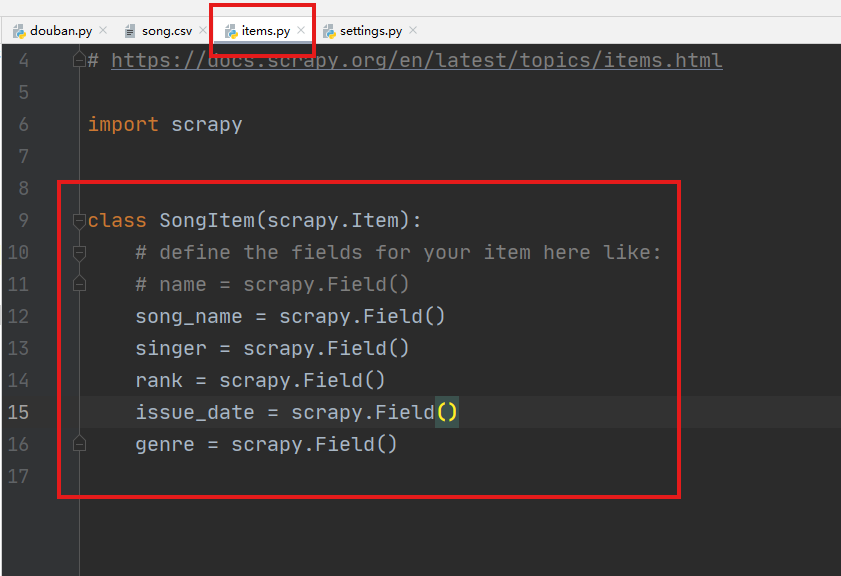
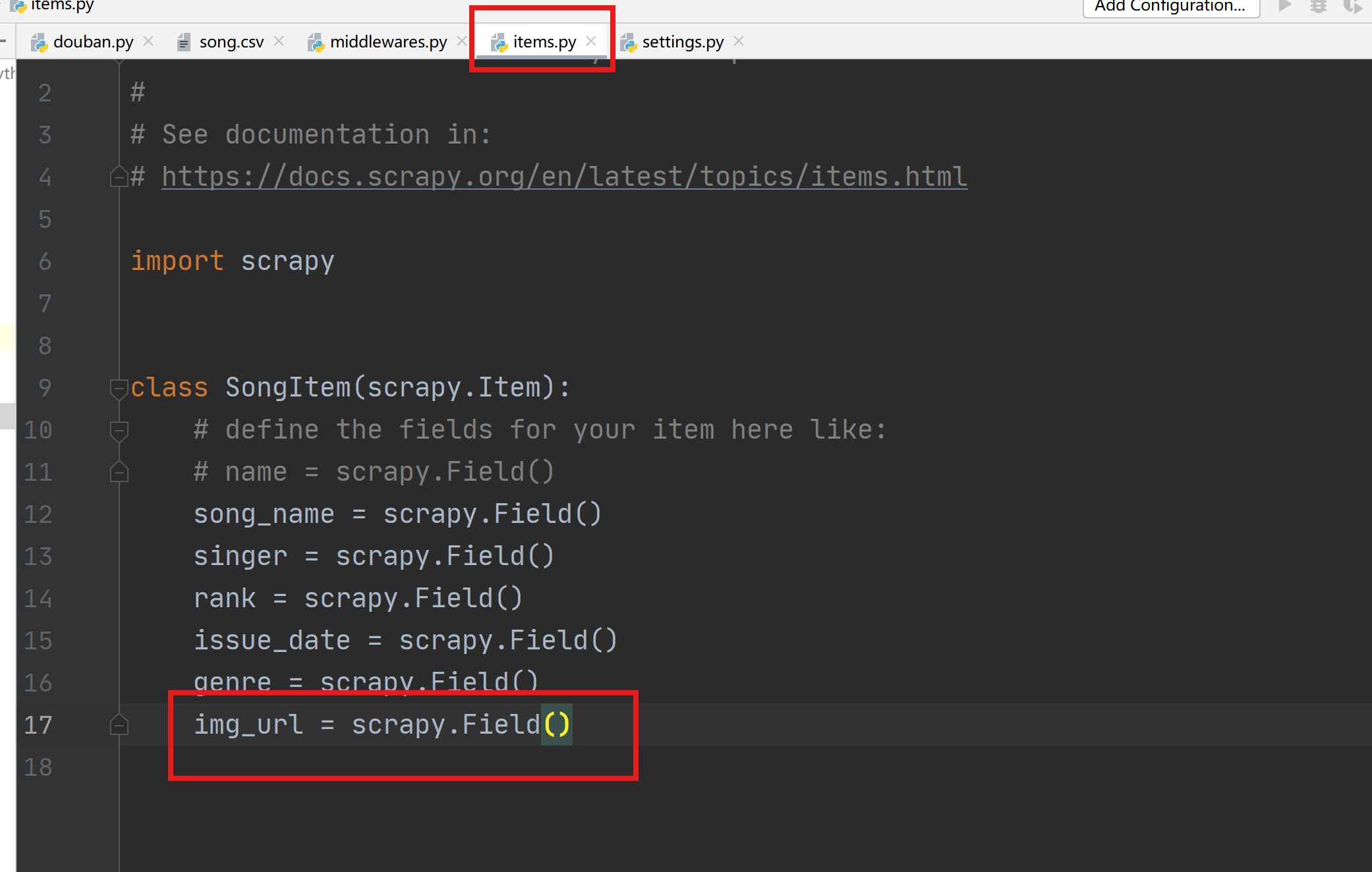
1.4 items.py设置
继承scrapy.Item的自定义类SongItem,导入到主程序douban.py中用于存储爬取的字段。
1.5 settings.py设置
用于控制Scrapy框架中各部件的参数,例如USER_AGENT、COOKIES、代理、中间件启停等。
修改USER_AGENT,模拟浏览器登录。
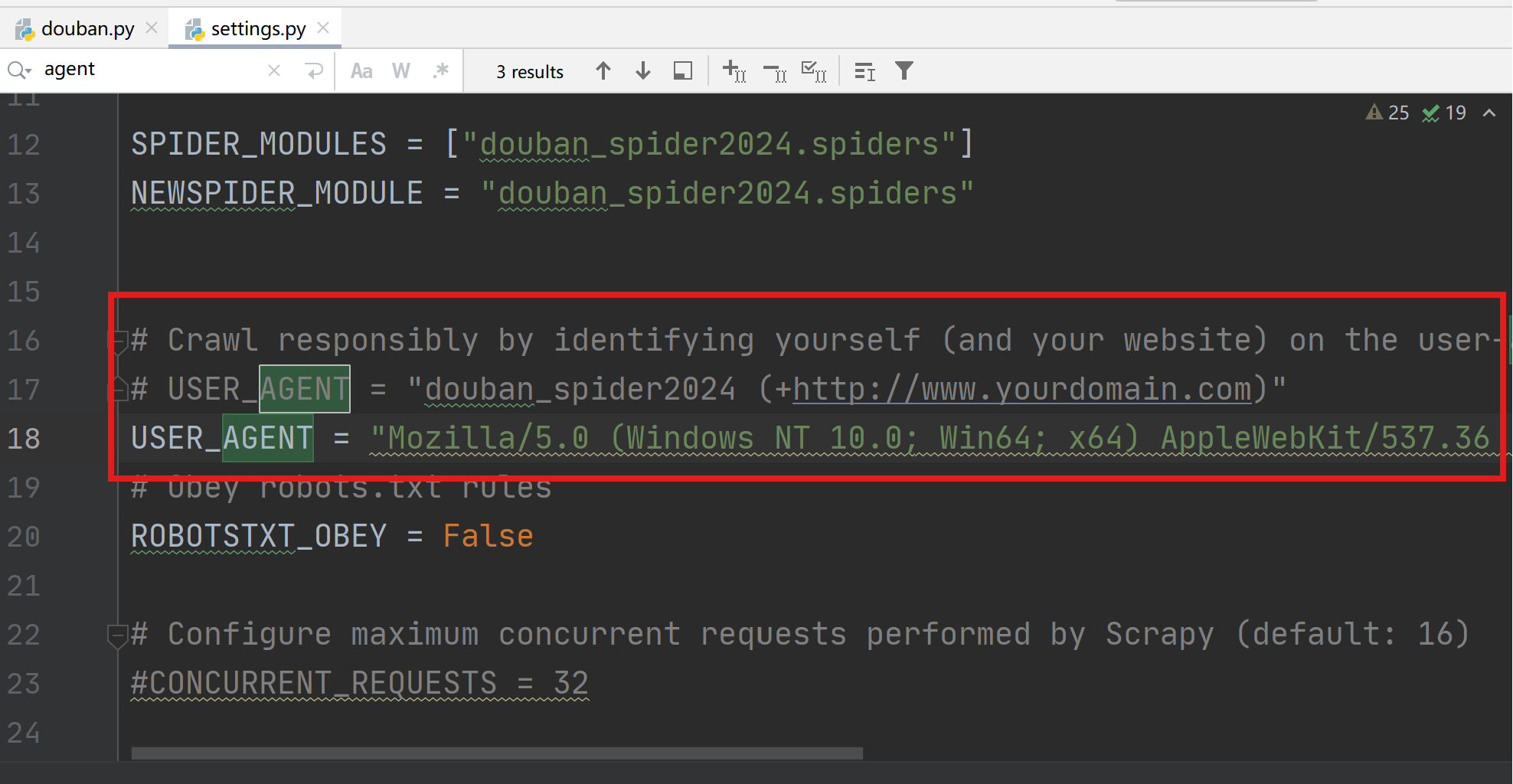
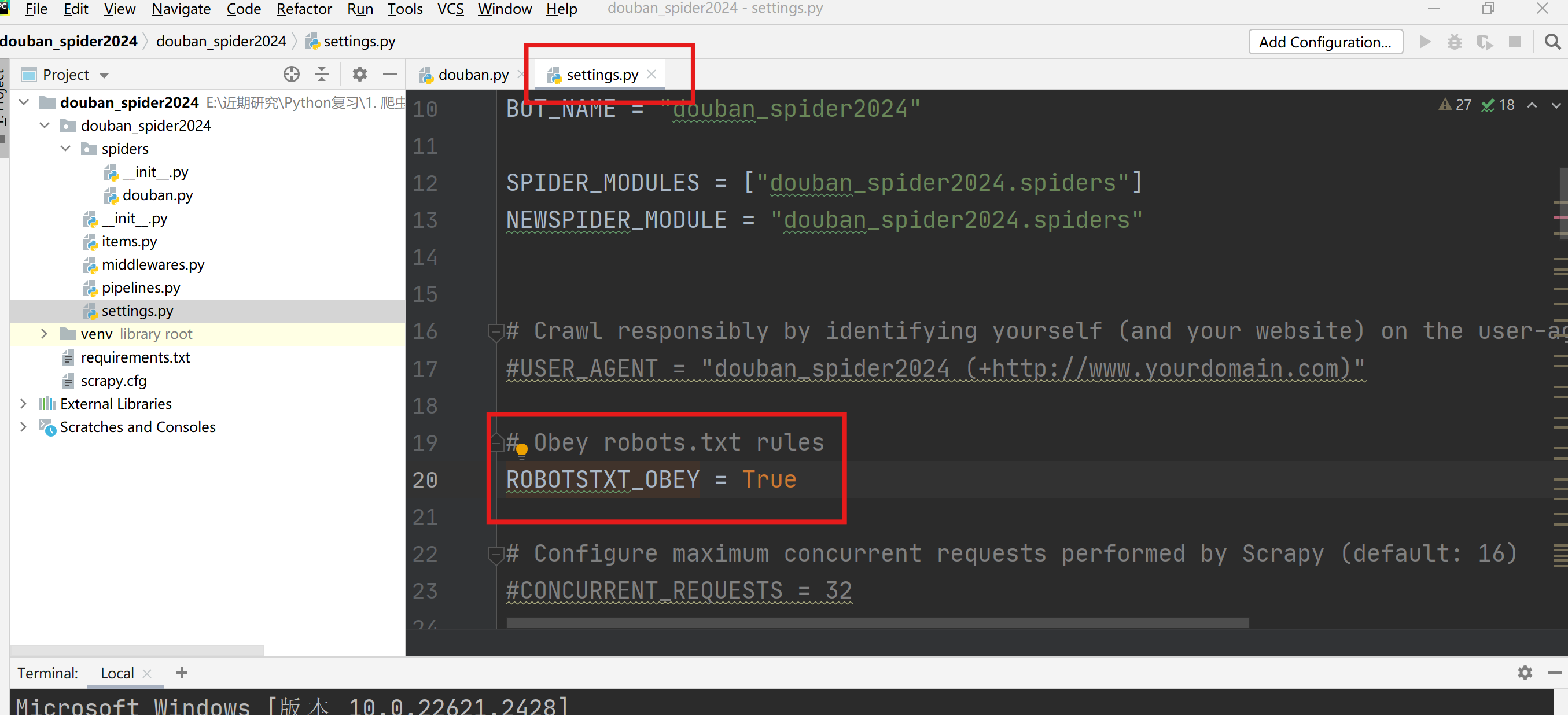
关闭Obey robots.txt rules,将True设置为False。
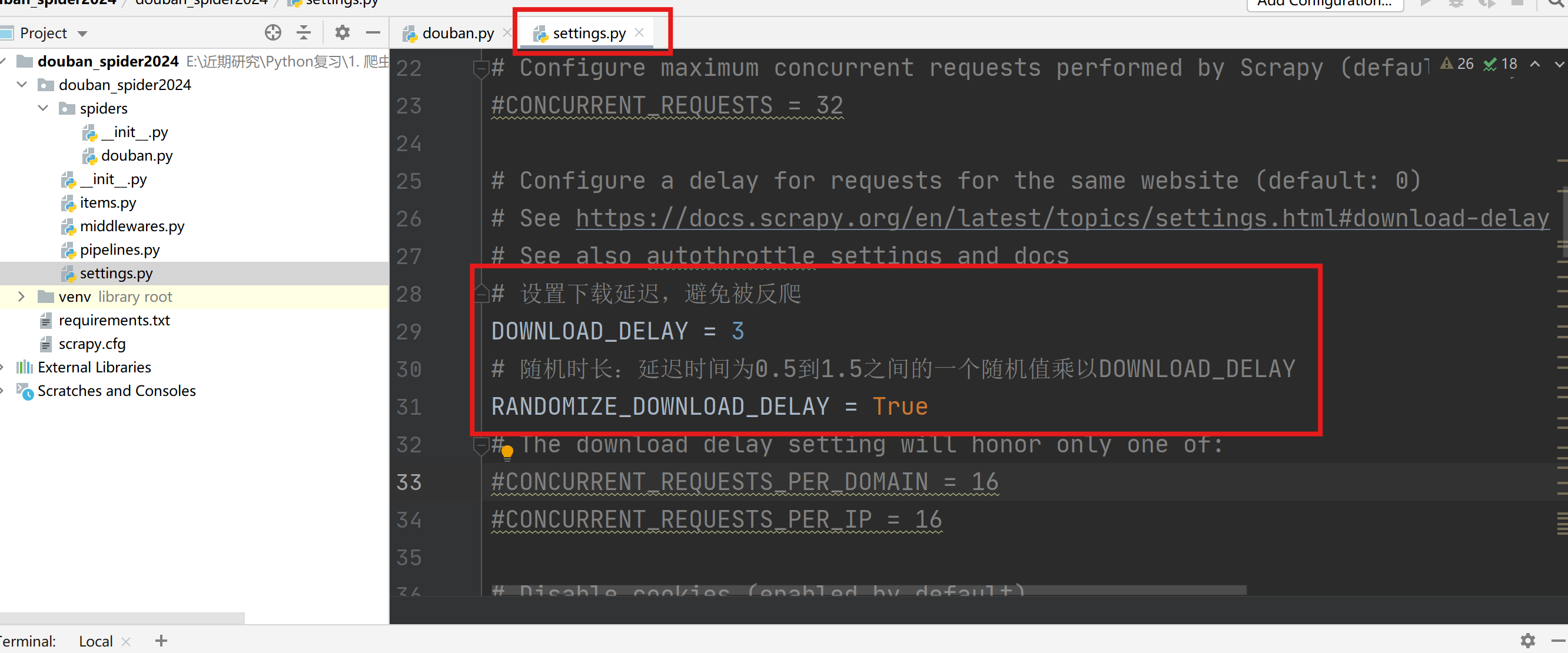
设置下载延迟
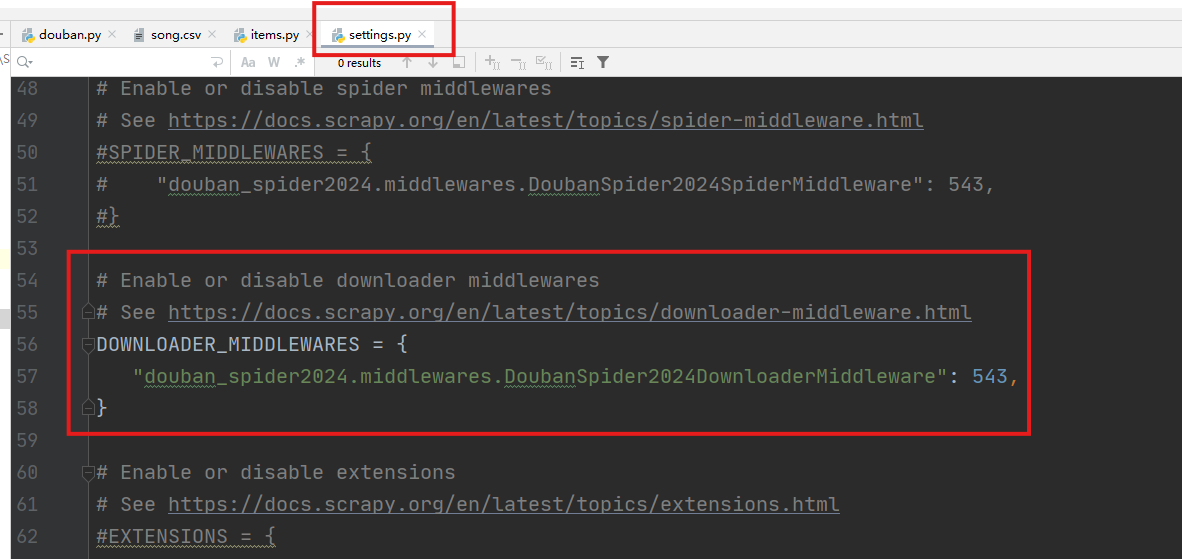
打开下载中间件(downloader_middlewares),实现拦截并修改Request的请求内容。
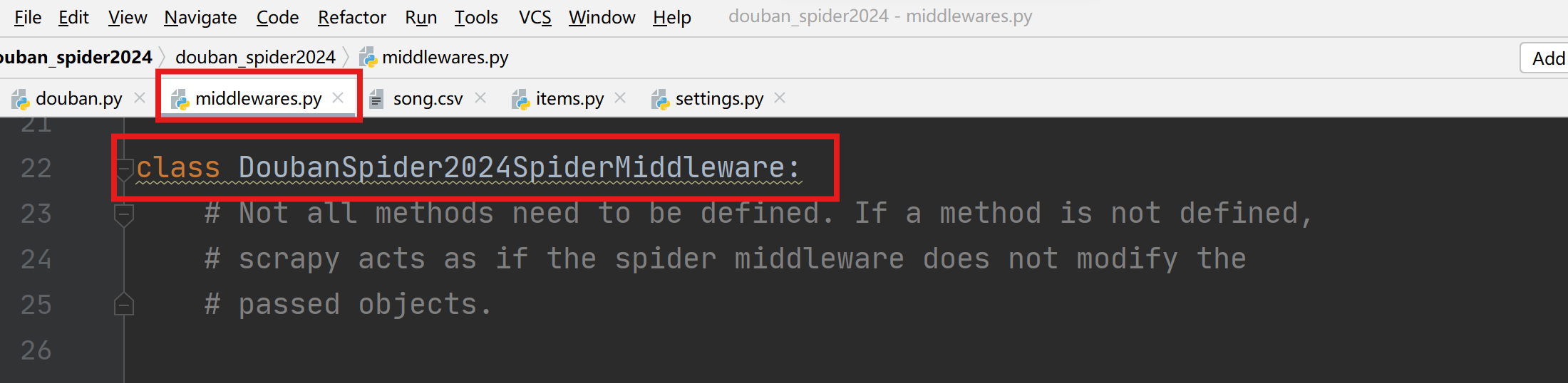
1.6 middlewares.py设置
cookies设置
进入middlewares.py程序中设置,新增一个处理cookies的函数,执行cookies函数返回一个包含cookies的字典COOKIE_ITEM。
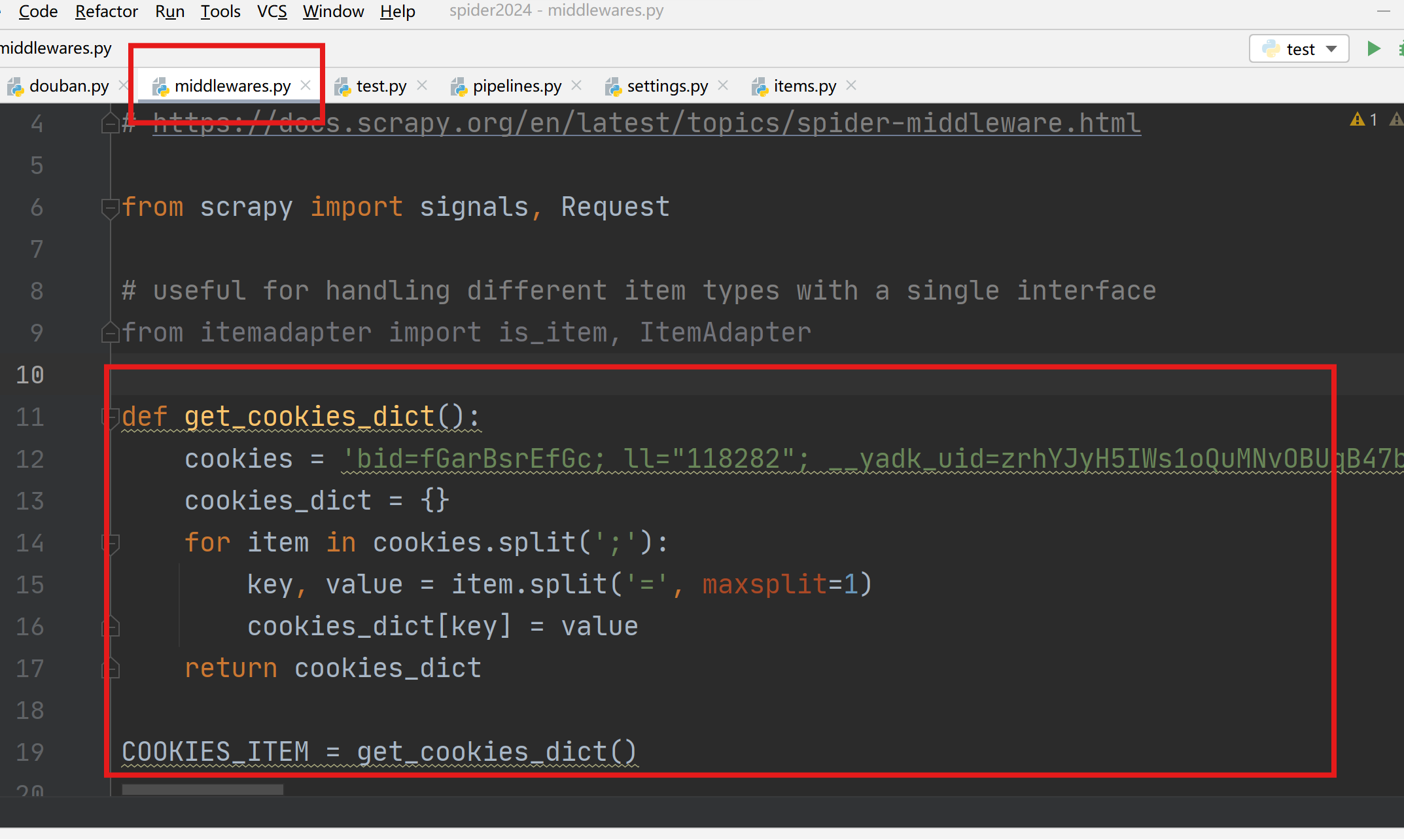
在xxDownloaderMiddleware类中process_request函数配置COOKIES_ITEM。
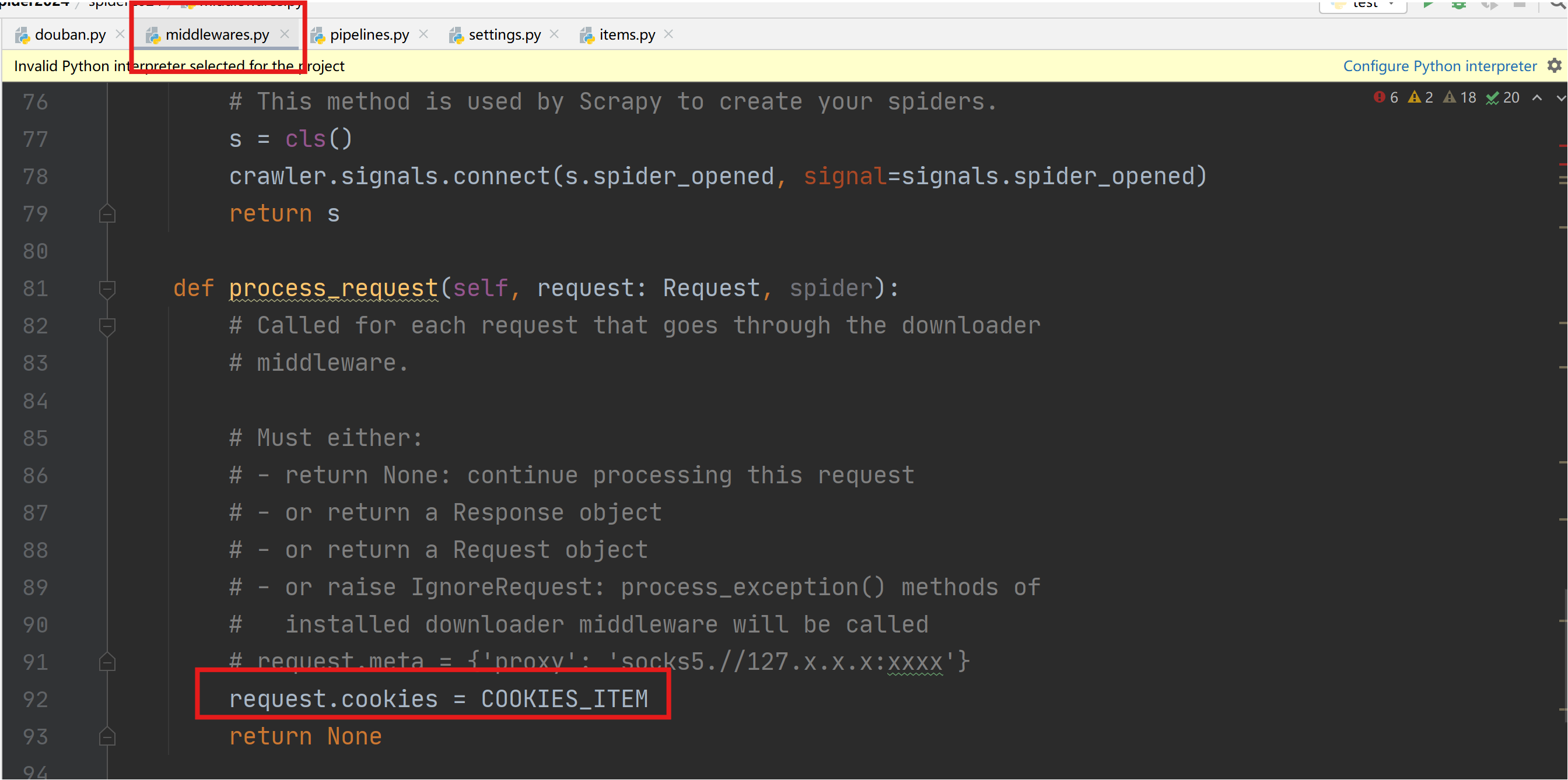
scrapy 利用sock代理??
1.7 多层url解析
利用回调函数解析多层url:在parse函数最后解析获取新的url,并提交新的Request,并传递item到回调函数parse_detail中解析。
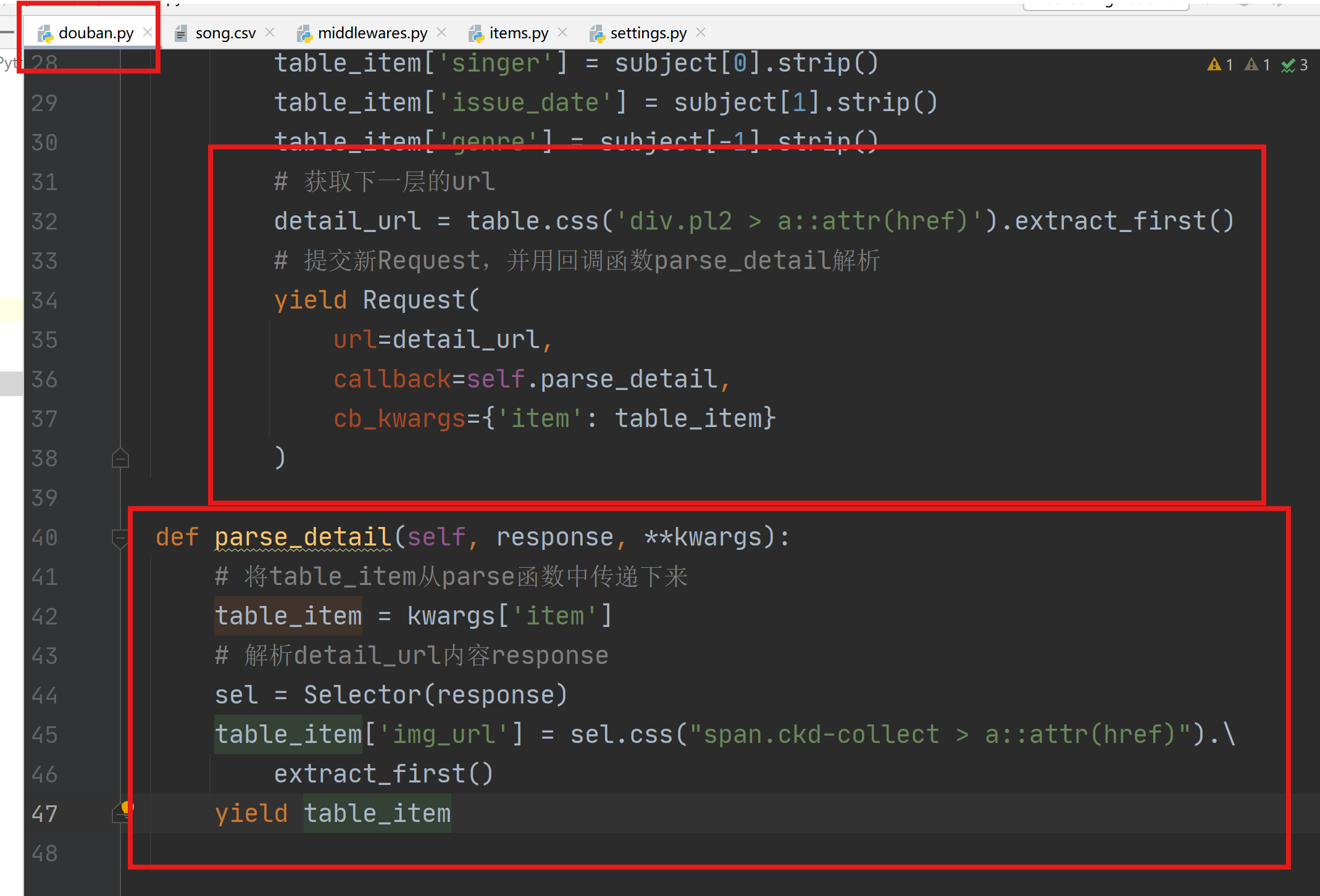
在items.py中添加新的item信息。
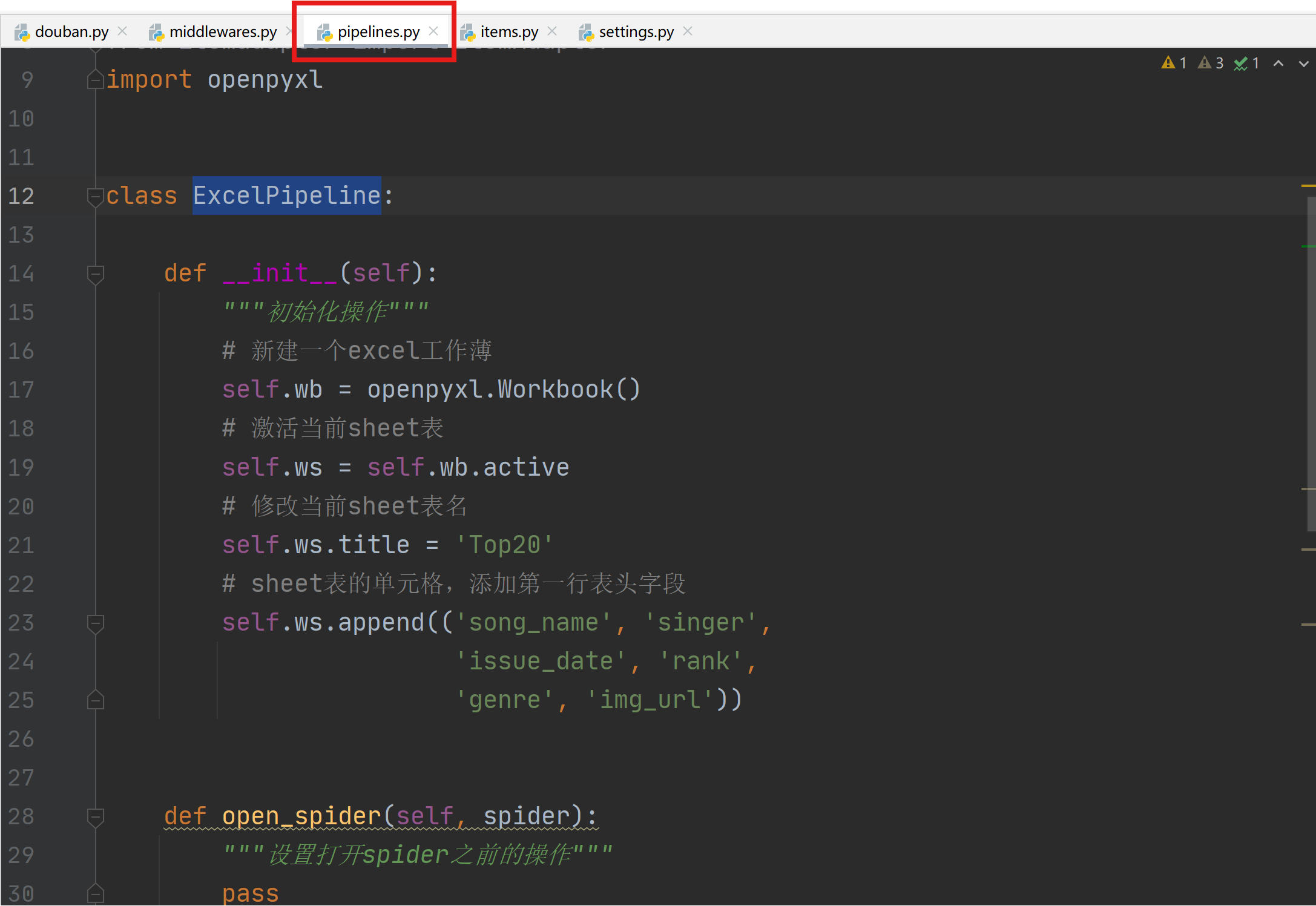
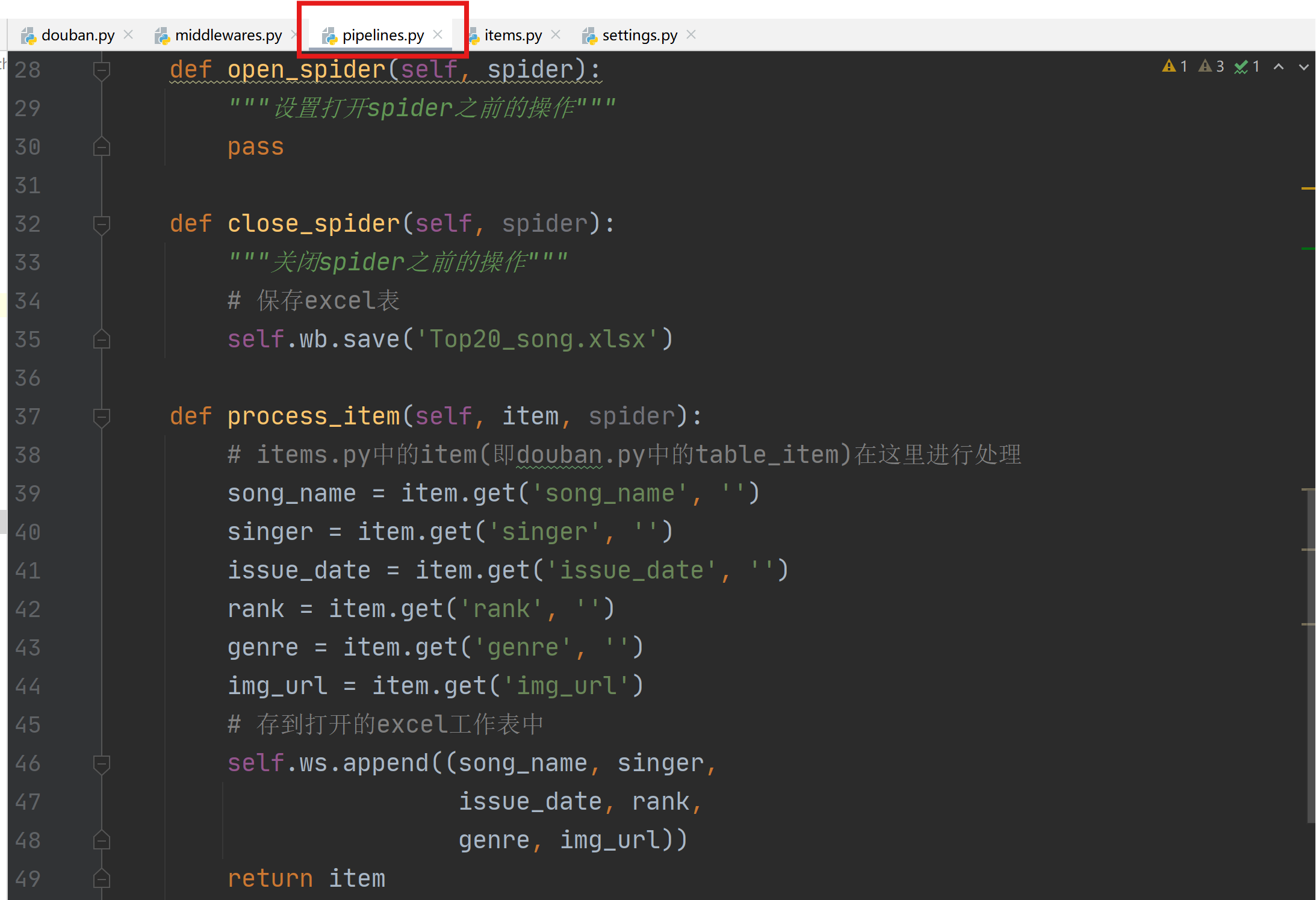
1.8 pipelines.py设置
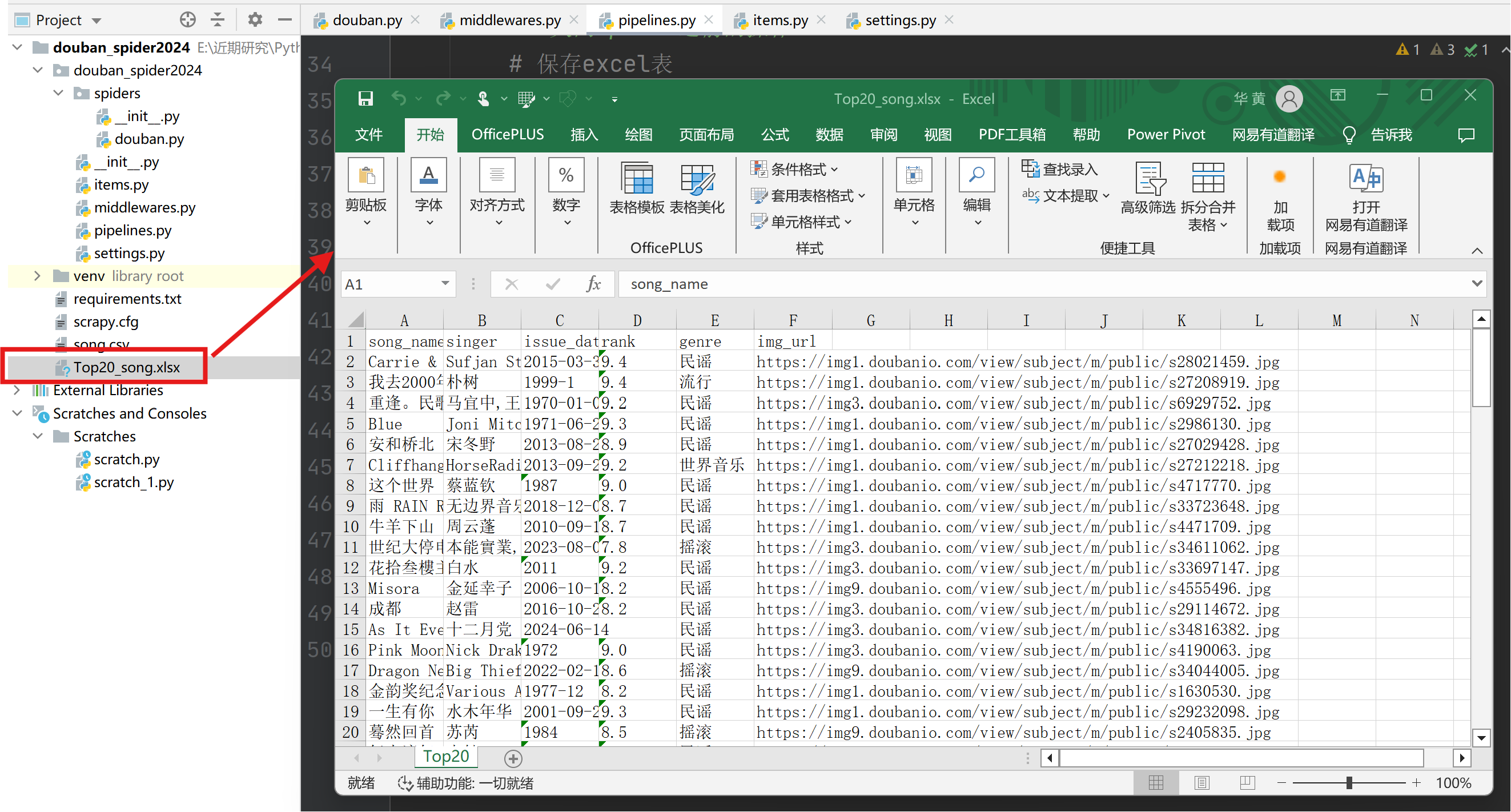
通过pipelines.py构建Excel存储管道,用于将爬取的数据存储到excel中。
七、Scrapy框架-案例1的更多相关文章
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- 爬虫——Scrapy框架案例一:手机APP抓包
以爬取斗鱼直播上的信息为例: URL地址:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0 爬取字段:房间ID. ...
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- python爬虫入门(七)Scrapy框架之Spider类
Spider类 Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作 ...
- 爬虫(十四):Scrapy框架(一) 初识Scrapy、第一个案例
1. Scrapy框架 Scrapy功能非常强大,爬取效率高,相关扩展组件多,可配置和可扩展程度非常高,它几乎可以应对所有反爬网站,是目前Python中使用最广泛的爬虫框架. 1.1 Scrapy介绍 ...
- 09 Scrapy框架在爬虫中的使用
一.简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.它集成高性能异步下载,队列,分布式,解析,持久化等. Scrapy 是基于twisted框架开发而来,twisted是一个 ...
- 网络爬虫第五章之Scrapy框架
第一节:Scrapy框架架构 Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
随机推荐
- SpringBoot+ Sharding Sphere 轻松实现数据库字段加解密
一.介绍 在实际的软件系统开发过程中,由于业务的需求,在代码层面实现数据的脱敏还是远远不够的,往往还需要在数据库层面针对某些关键性的敏感信息,例如:身份证号.银行卡号.手机号.工资等信息进行加密存储, ...
- 关于使用c++制作蓝牙连接,Windows版本
1 #define _CRT_SECURE_NO_WARNINGS 2 #pragma warning(disable : 4995) 3 #include <iostream> 4 #i ...
- telegraf 常用命令总结
本文为博主原创,转载请注明出处: Telegraf 是一个灵活的服务器代理,用于收集和报告指标.它支持插件驱动,这意味着你可以根据需要添加或修改功能. 1.使用telegraf --help 查看te ...
- 【Java】将枚举类转换为Redis字典缓存
字典翻译框架实现看这篇: https://www.cnblogs.com/mindzone/p/16890632.html 枚举的特性 首先是枚举的一些特性: 1.枚举实例直接在枚举类中声明 2.重载 ...
- 【Vue】Re11 Vue 与 Webpack
一.案例环境前置准备: 创建一个空目录用于案例演示 mkdir vue-sample 初始化案例和安装webpack cd vue-sample npm install webpack@3.6.0 - ...
- application.properties配置文件存储参数
配置文件存储参数 当我们需要很多的参数时,项目很大,文件很多,每涉及一个技术,每涉及一个第三方的参数时,当这些参数数据发生变化,修改会相当的麻烦.这时候把参数配置到application.proper ...
- 什么样的AI计算框架才是受用户喜欢的?
说明,本文是个人的一些胡想. 背景: AI计算框架现在从国外的百家争鸣过度到了国内百家争鸣的局面了.在7.8年前的时候,国外的AI计算框架简直是数不胜数,从14.15年前Nvidia公司的显卡需要手动 ...
- 读《PyTorch + NumPy这么做会降低模型准确率,这是bug还是预期功能?》
看了文章: [转载] 浅谈PyTorch的可重复性问题(如何使实验结果可复现) 然后,转到: PyTorch + NumPy这么做会降低模型准确率,这是bug还是预期功能? 发现了在pytorch中的 ...
- 2023年 IJCAI 审稿模板
================================================== ================================================= ...
- AI 大模型时代呼唤新一代基础设施,DataOps 2.0和调度编排愈发重要
在 AI 时代,DataOps 2.0 代表了一种全新的数据管理和操作模式,通过自动化数据管道.实时数据处理和跨团队协作,DataOps 2.0 能够加速数据分析和决策过程.它融合了人工智能和机器学习 ...