七、Scrapy框架-案例1
1. 豆瓣民谣Top排名爬取
1.1 构建scrapy项目
安装Scrapy库
pip install scrapy
创建Scrapy项目
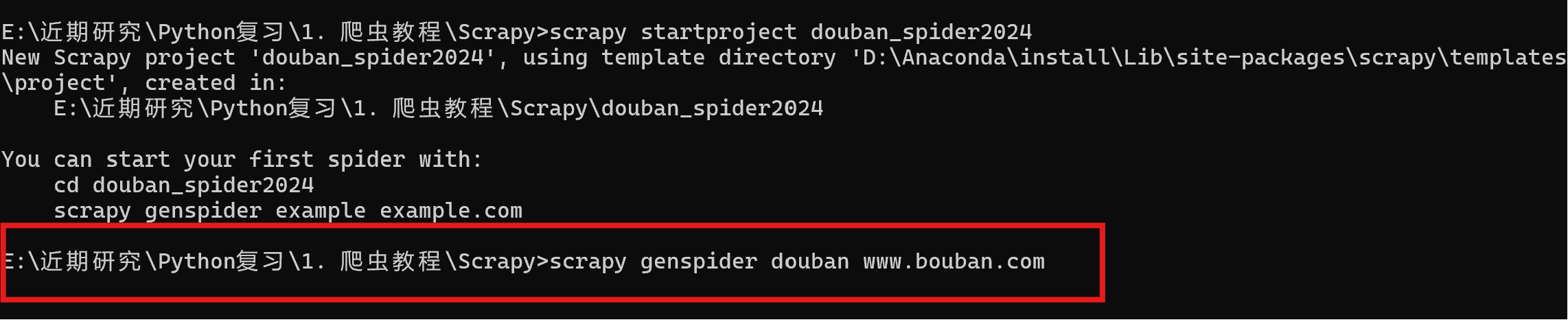
通过cmd进入命令窗口,执行命令scrapy startproject xxxx (xxxx为scrapy项目名),创建scrapy项目。
scrapy startproject douban_spider2024
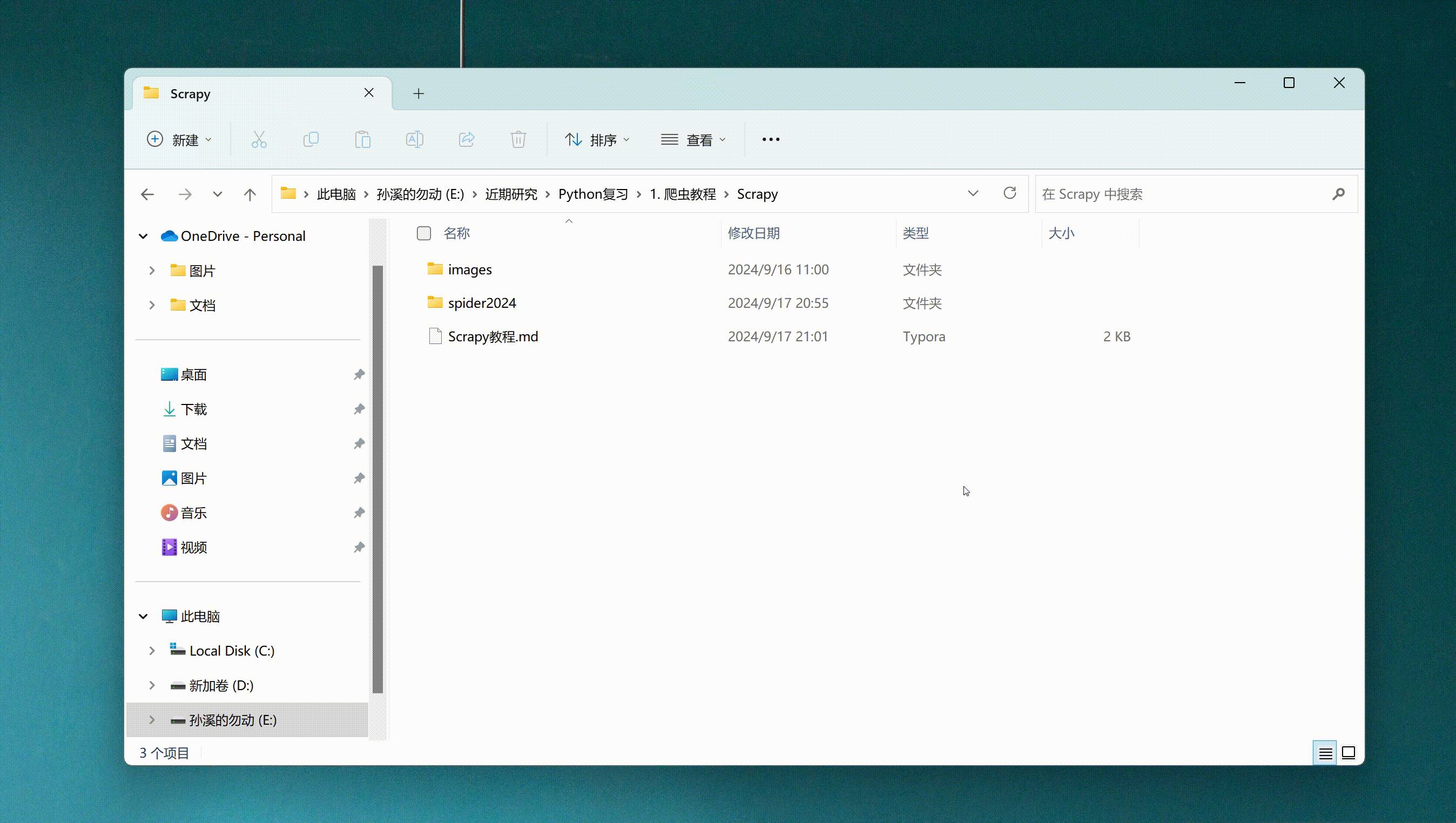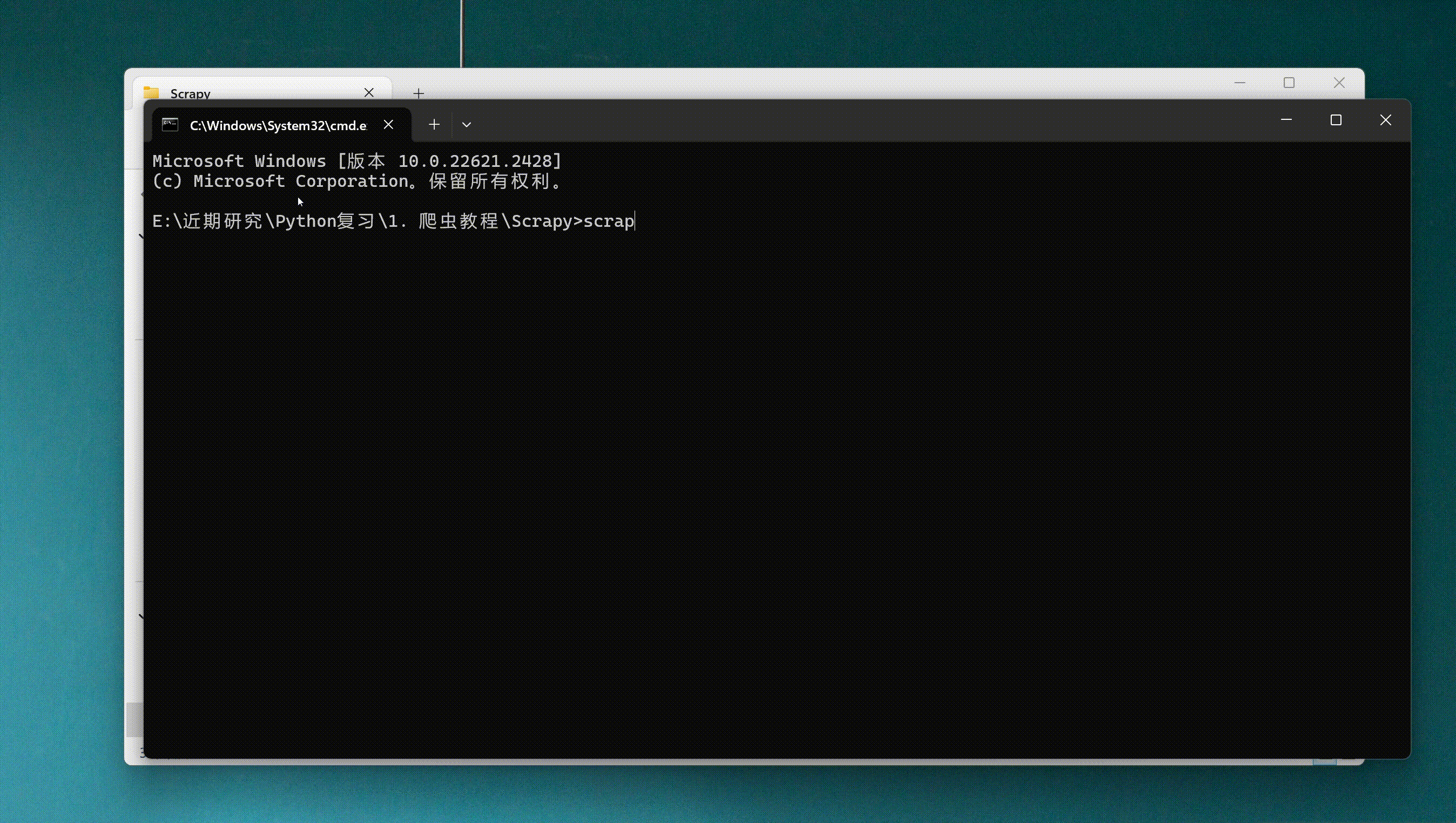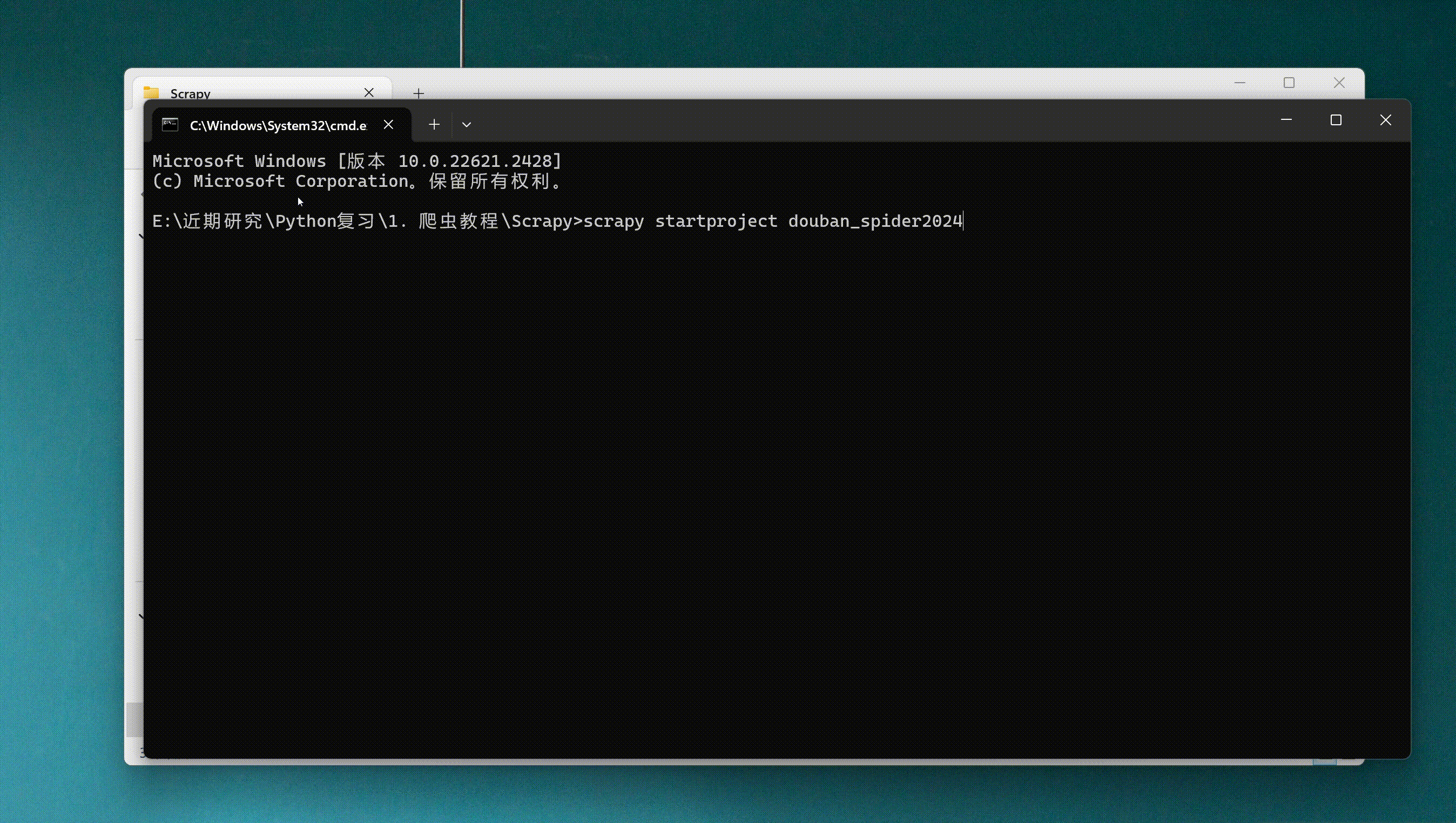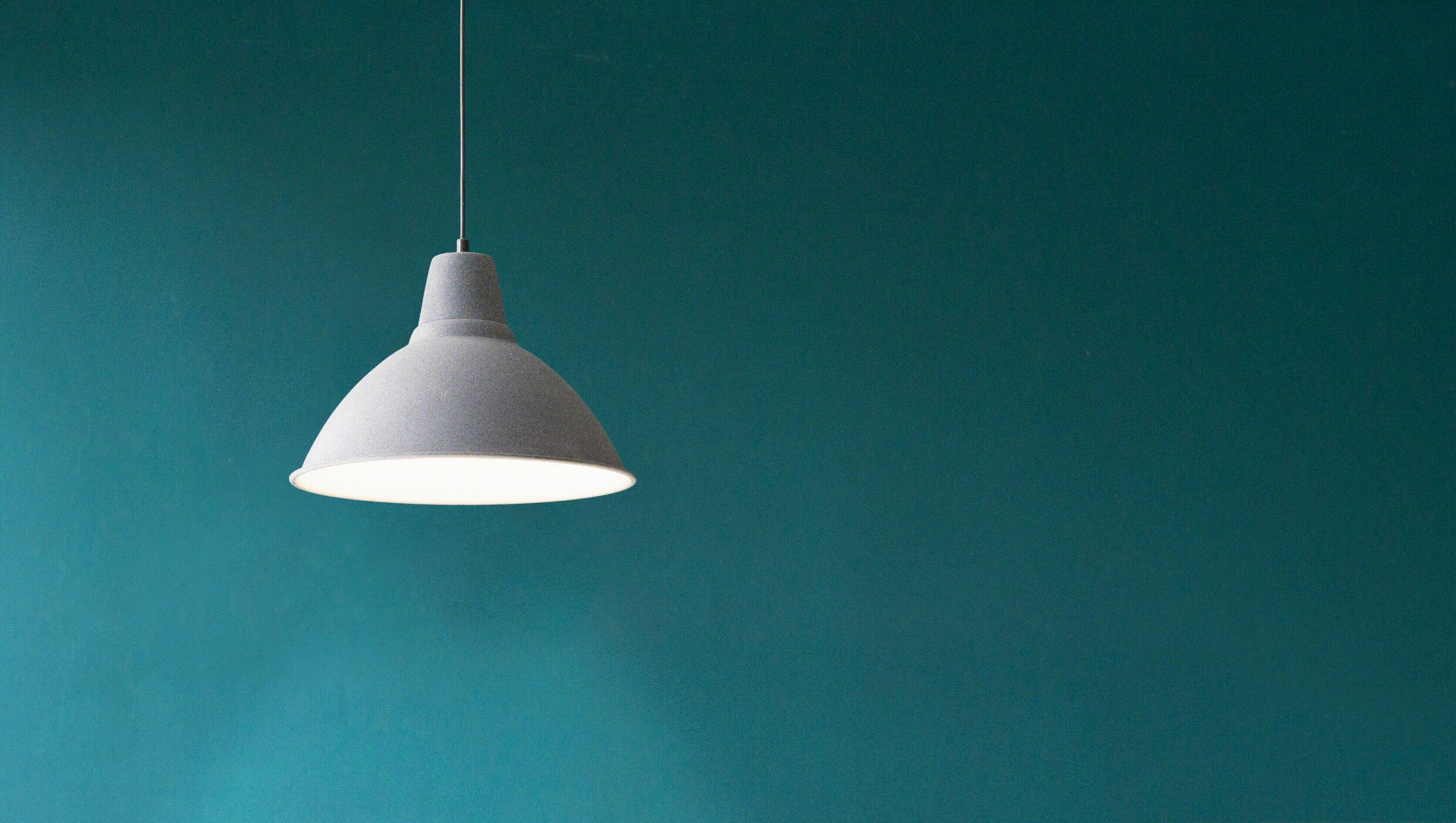
创建爬虫项目
执行scrapy genspider xxx(爬虫名称) xxx(网址)创建爬虫项目。
scrapy genspider douban www.bouban.com
1.2 虚拟环境构建
使用Pycharm打开创建好的douban_spider2024文件夹,进入项目。
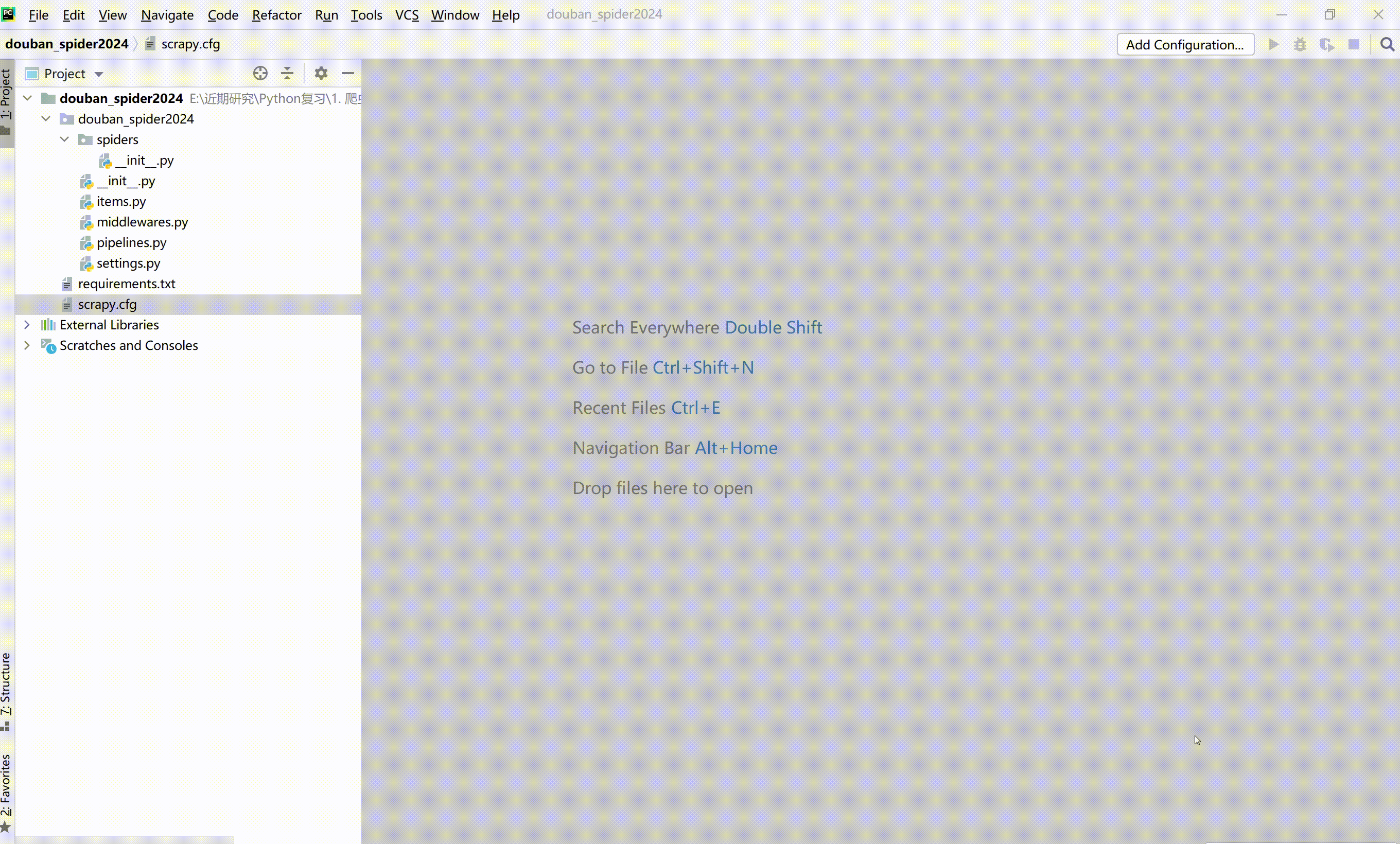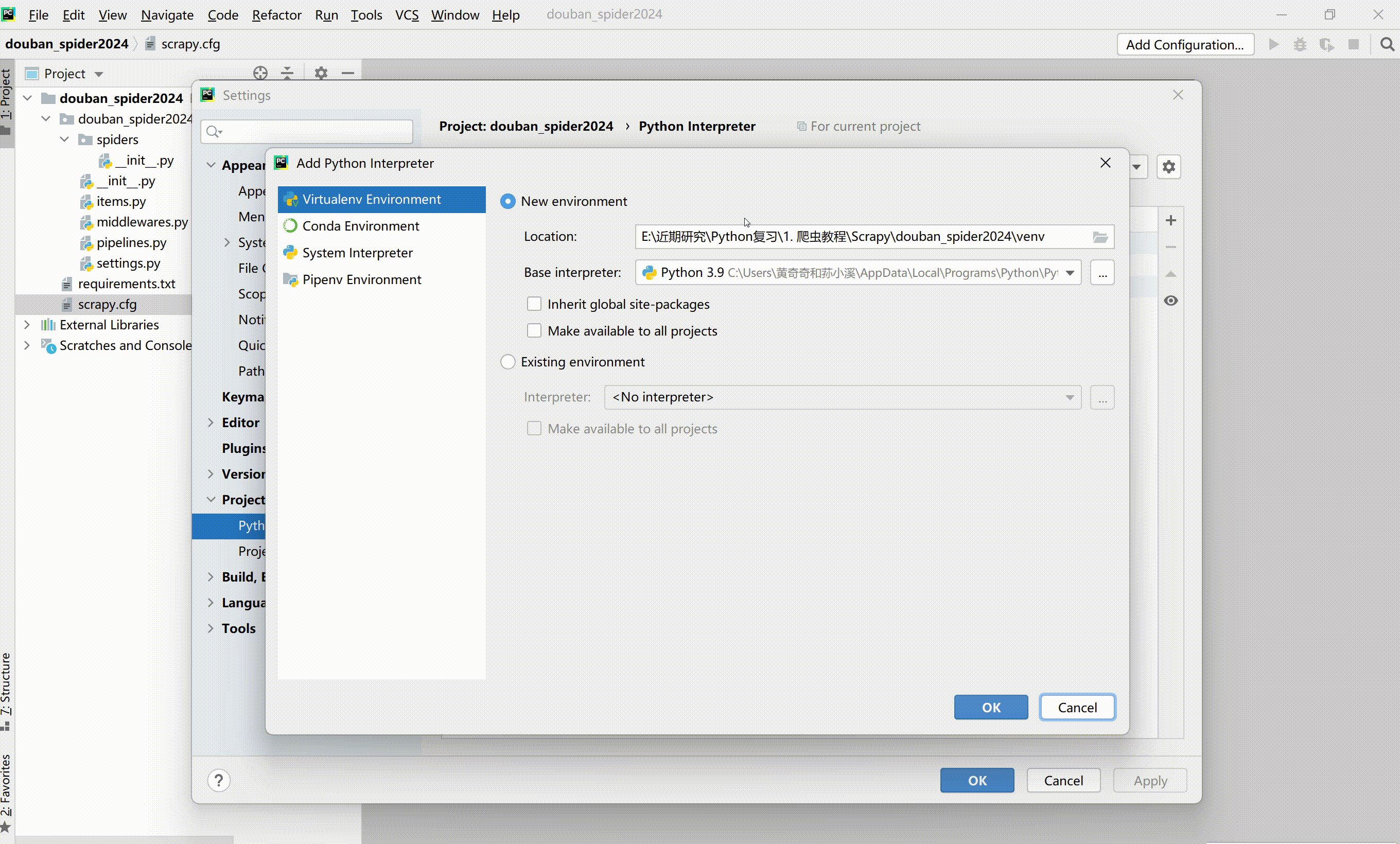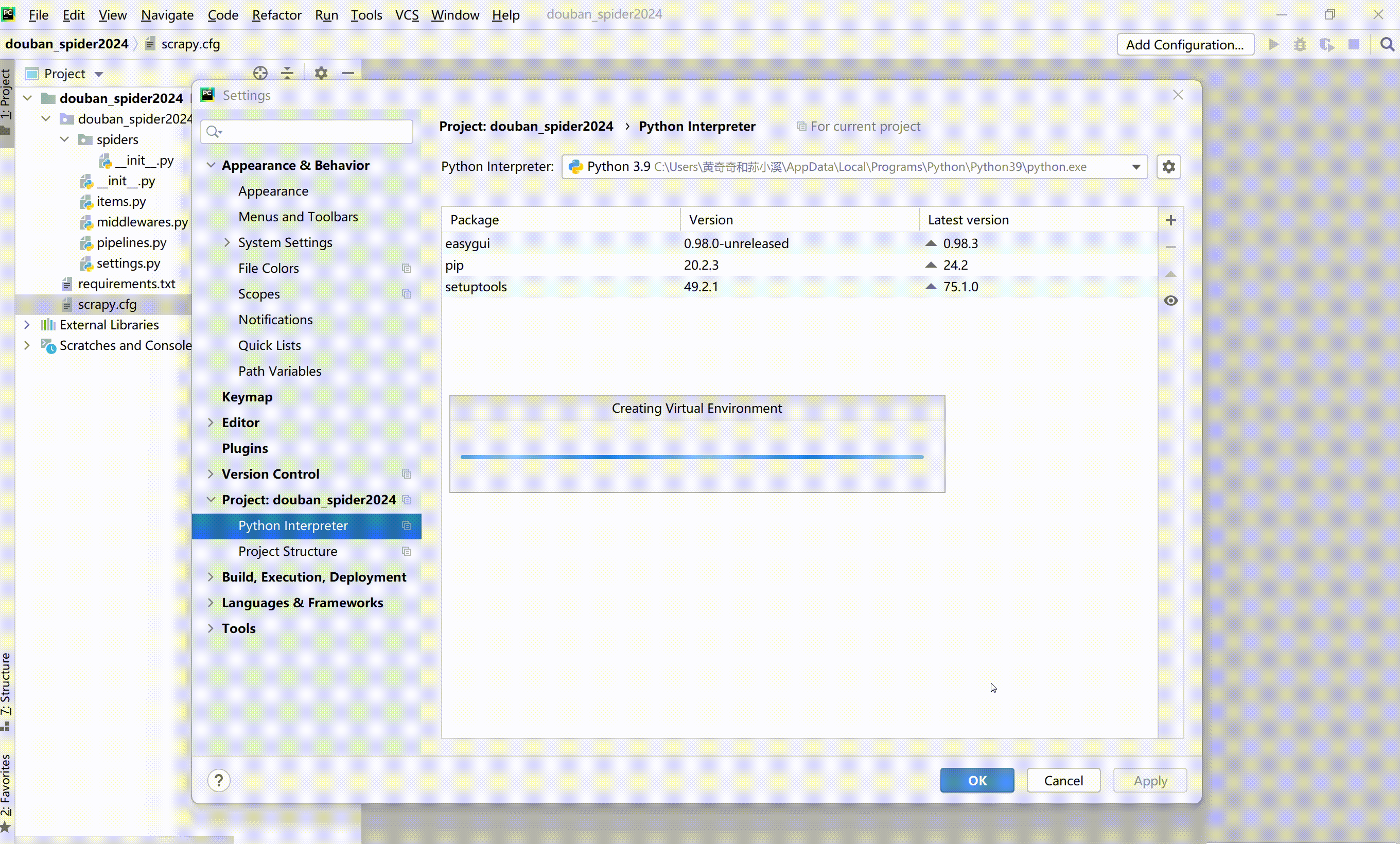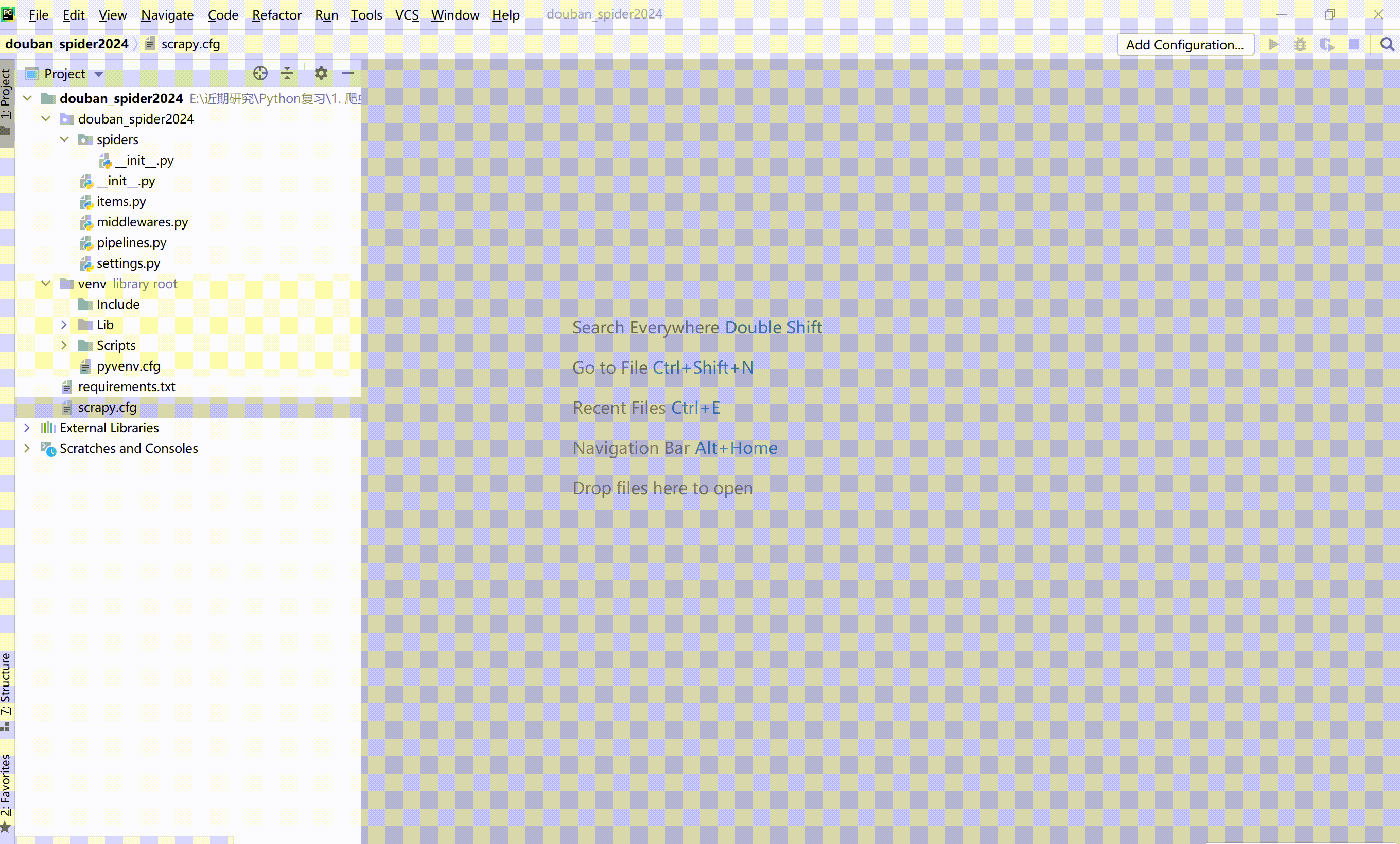
构建虚拟环境(venv)
利用requirement.txt文件安装依赖库,也可以自己一个个pip安装。
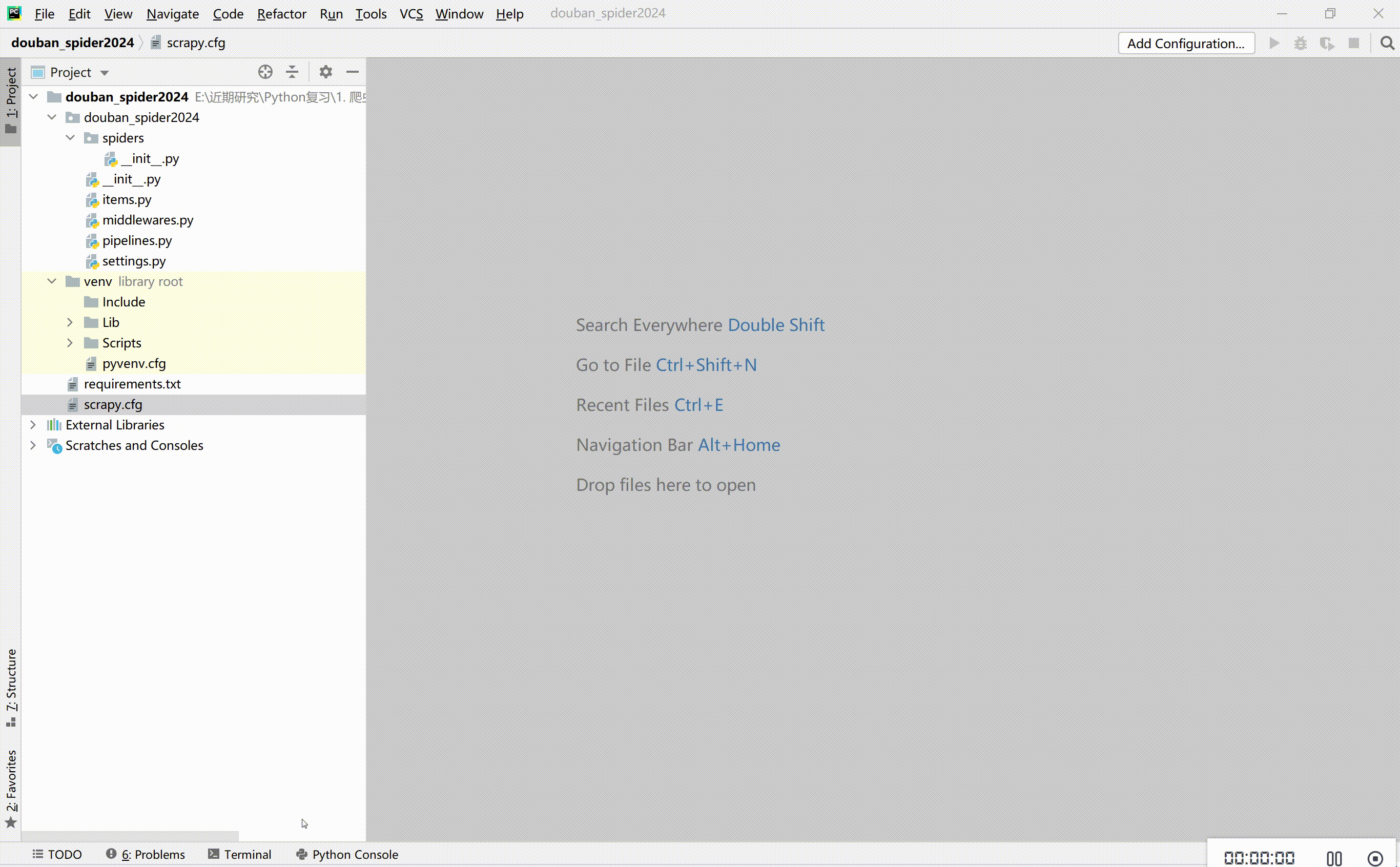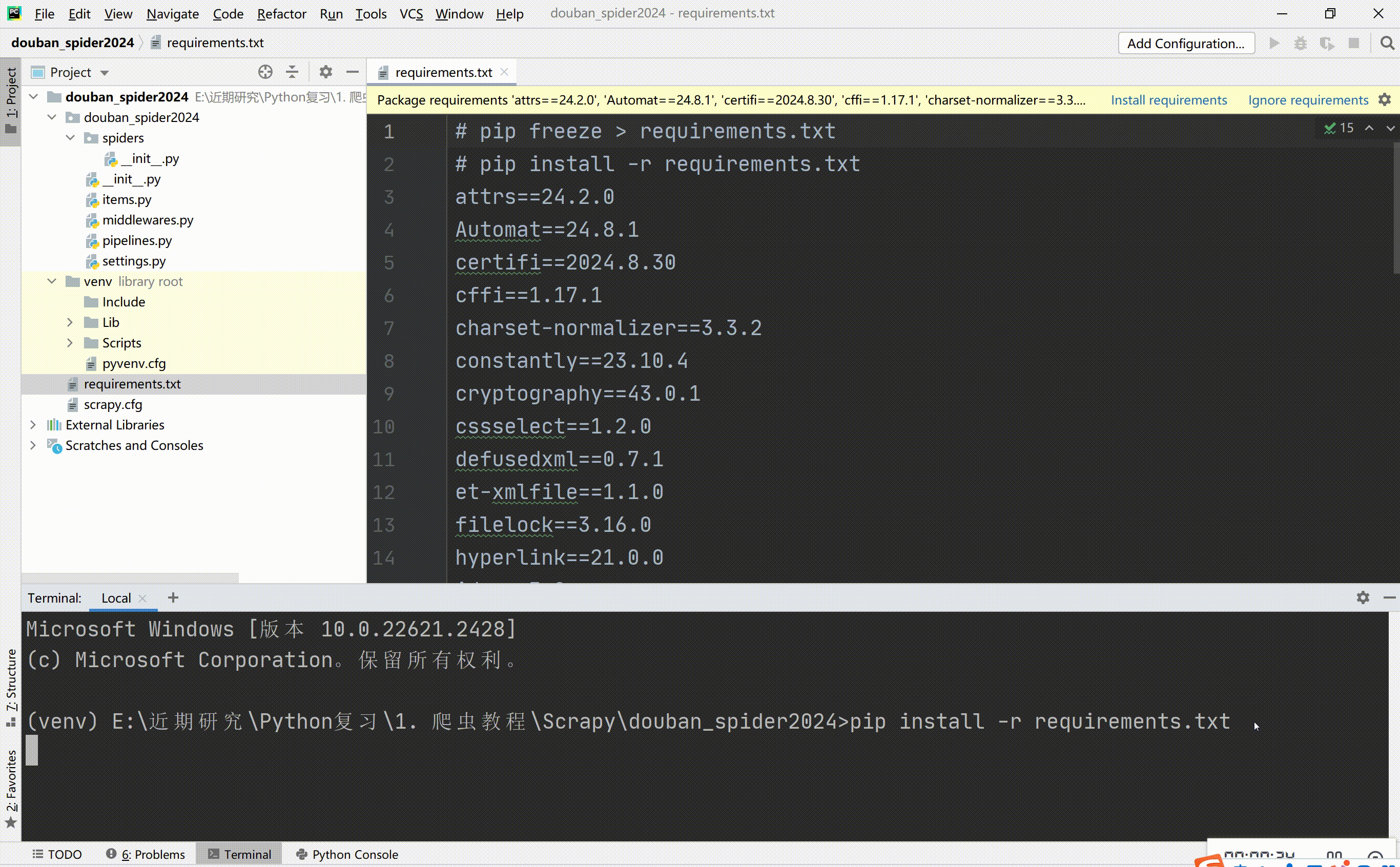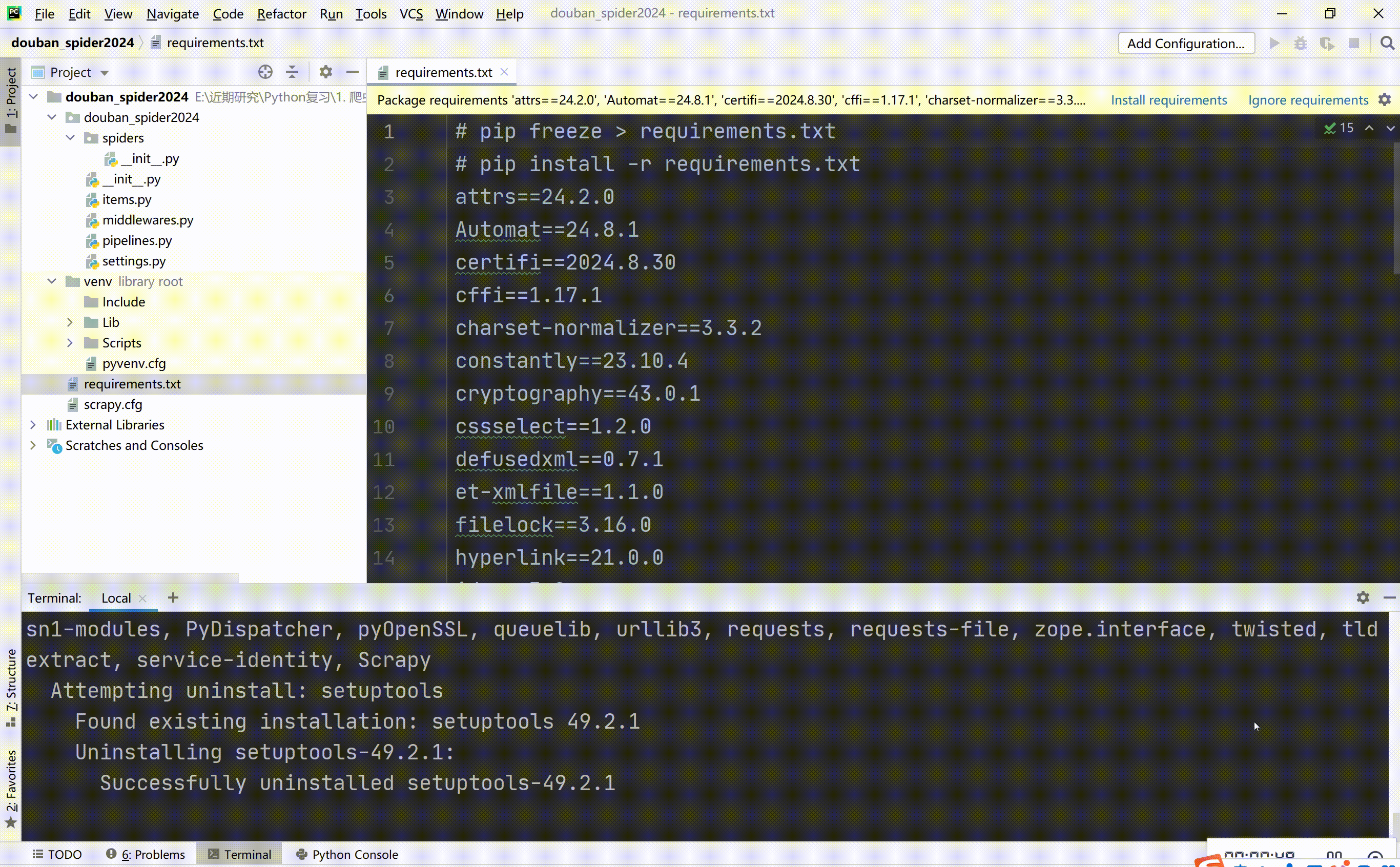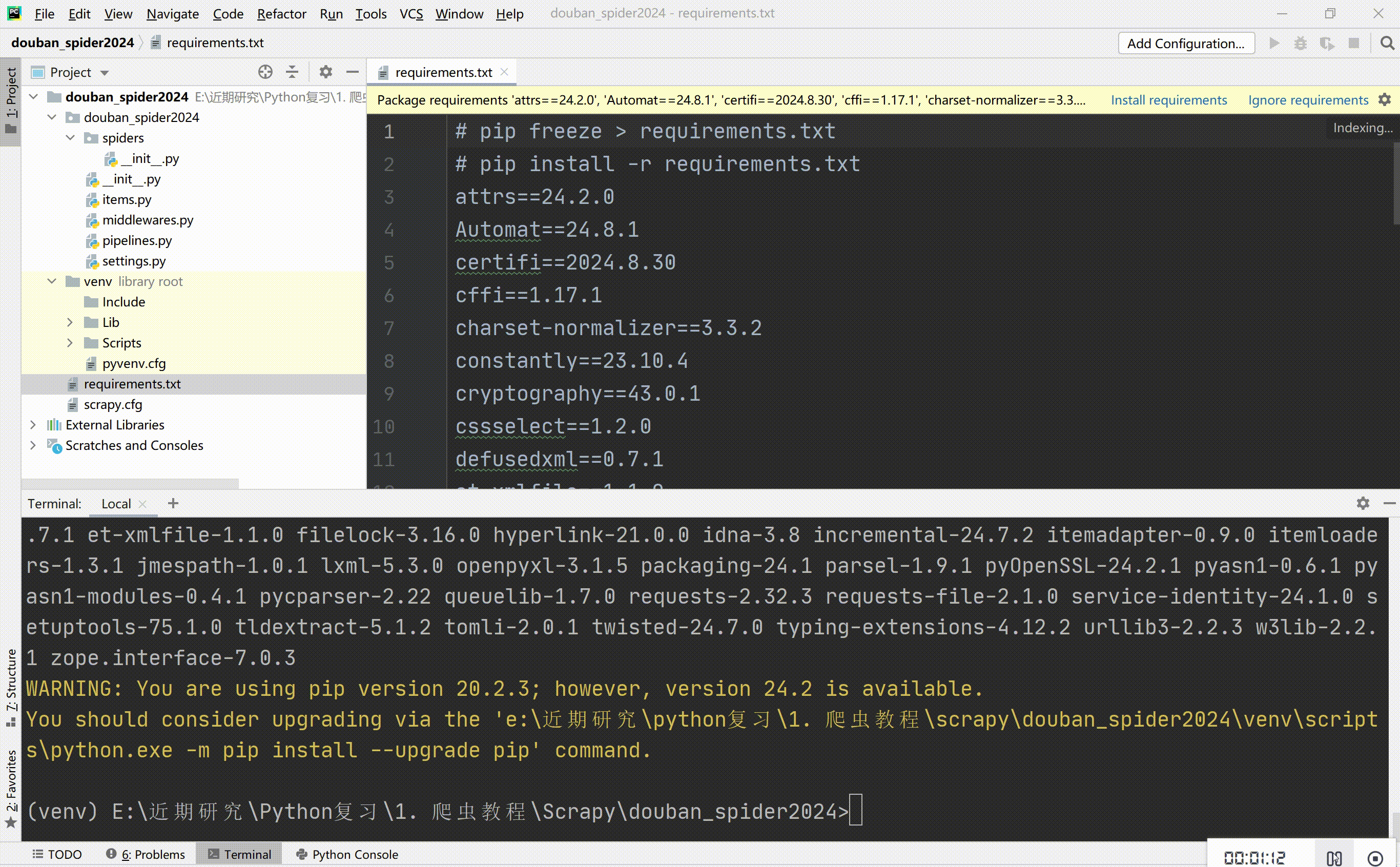
查看依赖库:pip freeze > requirements.txt
安装依赖库:pip install -r requirements.txt
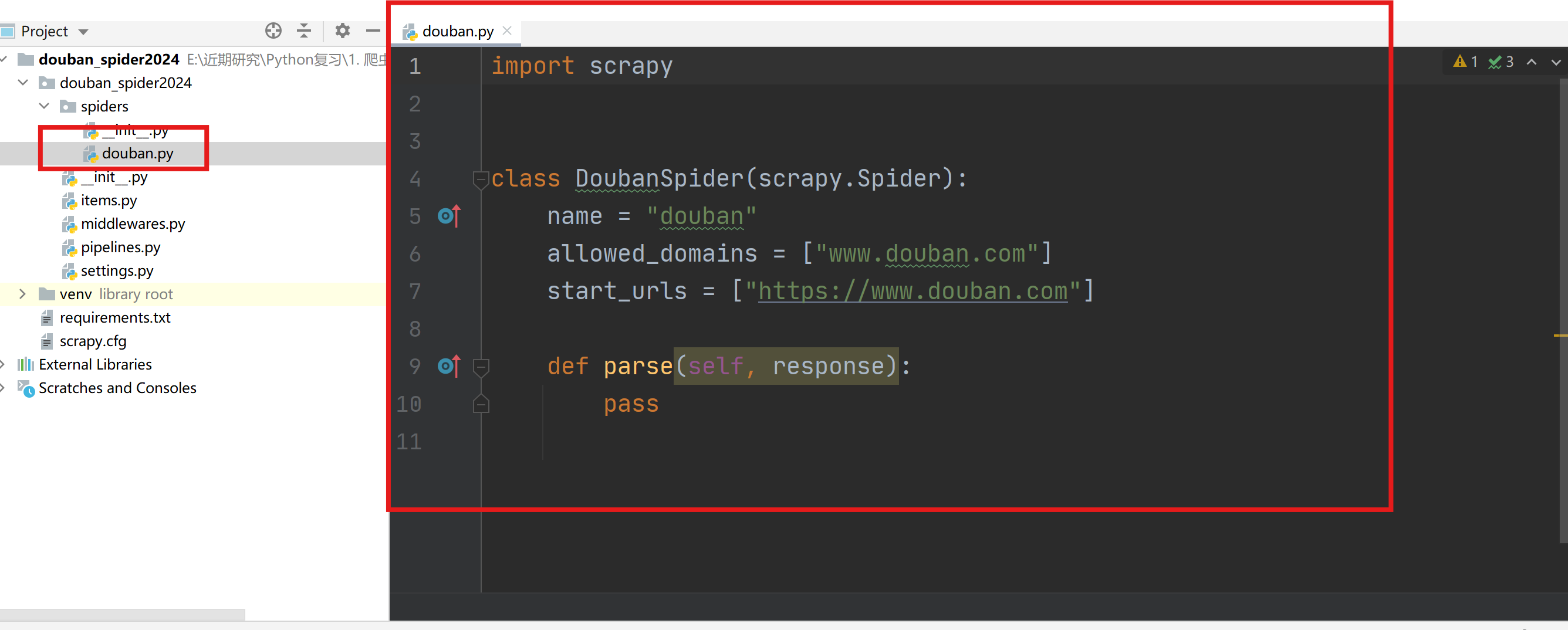
1.3 主程序编写
主程序(douban.py)用于编写解析页面的主要内容的代码。
通过start_requests函数获取urls列表,并用Request封装(需要配合在settings.py中启用下载中间件)。
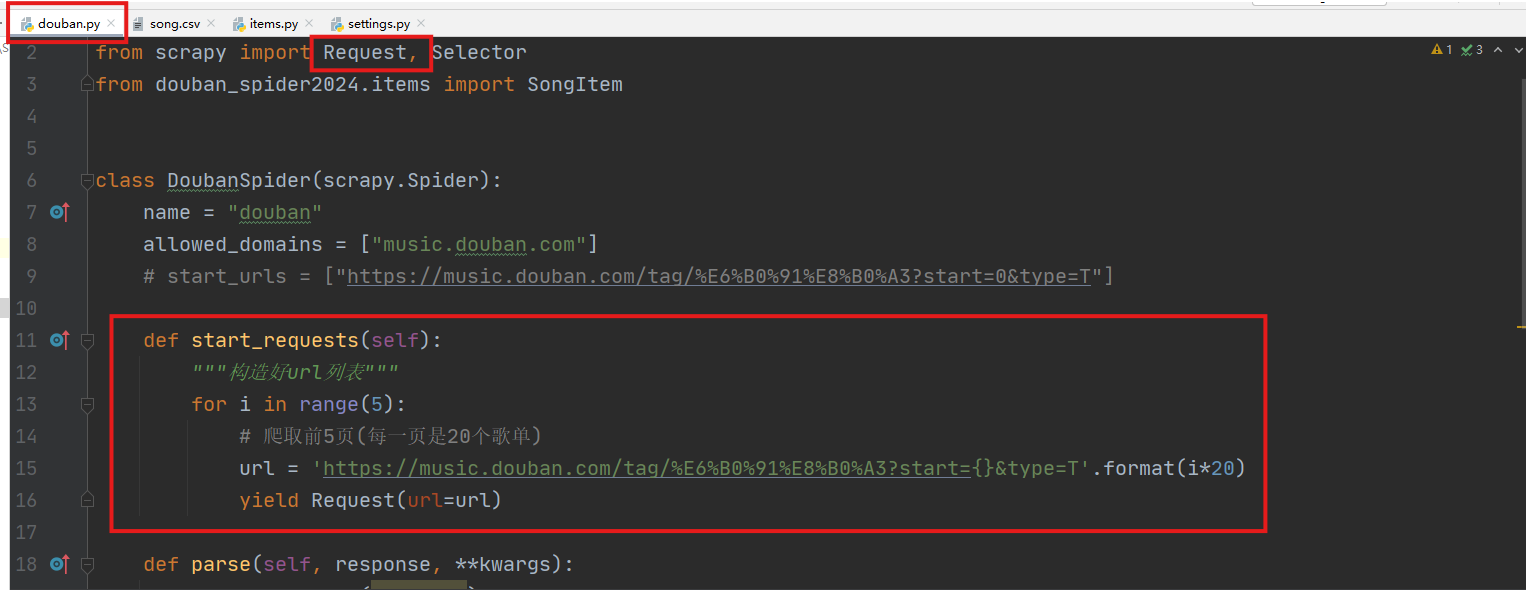
通过parse函数进行网页解析。

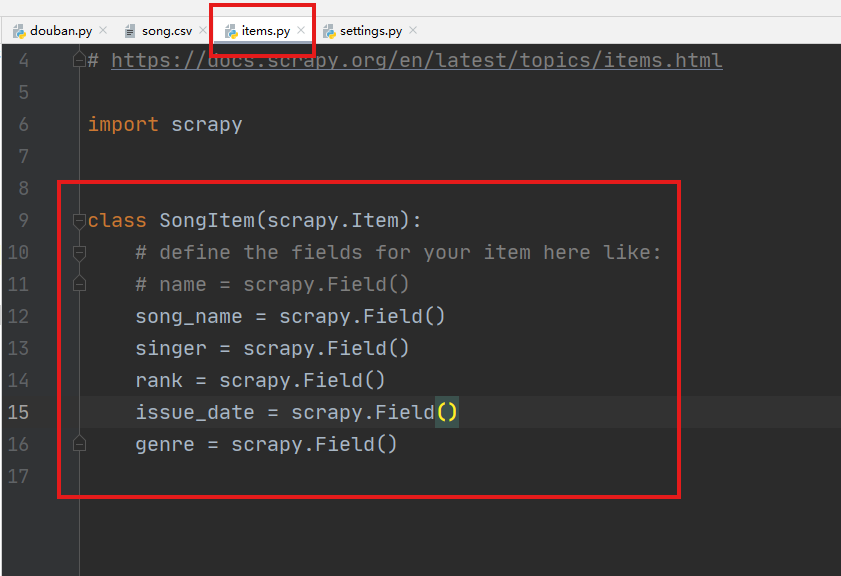
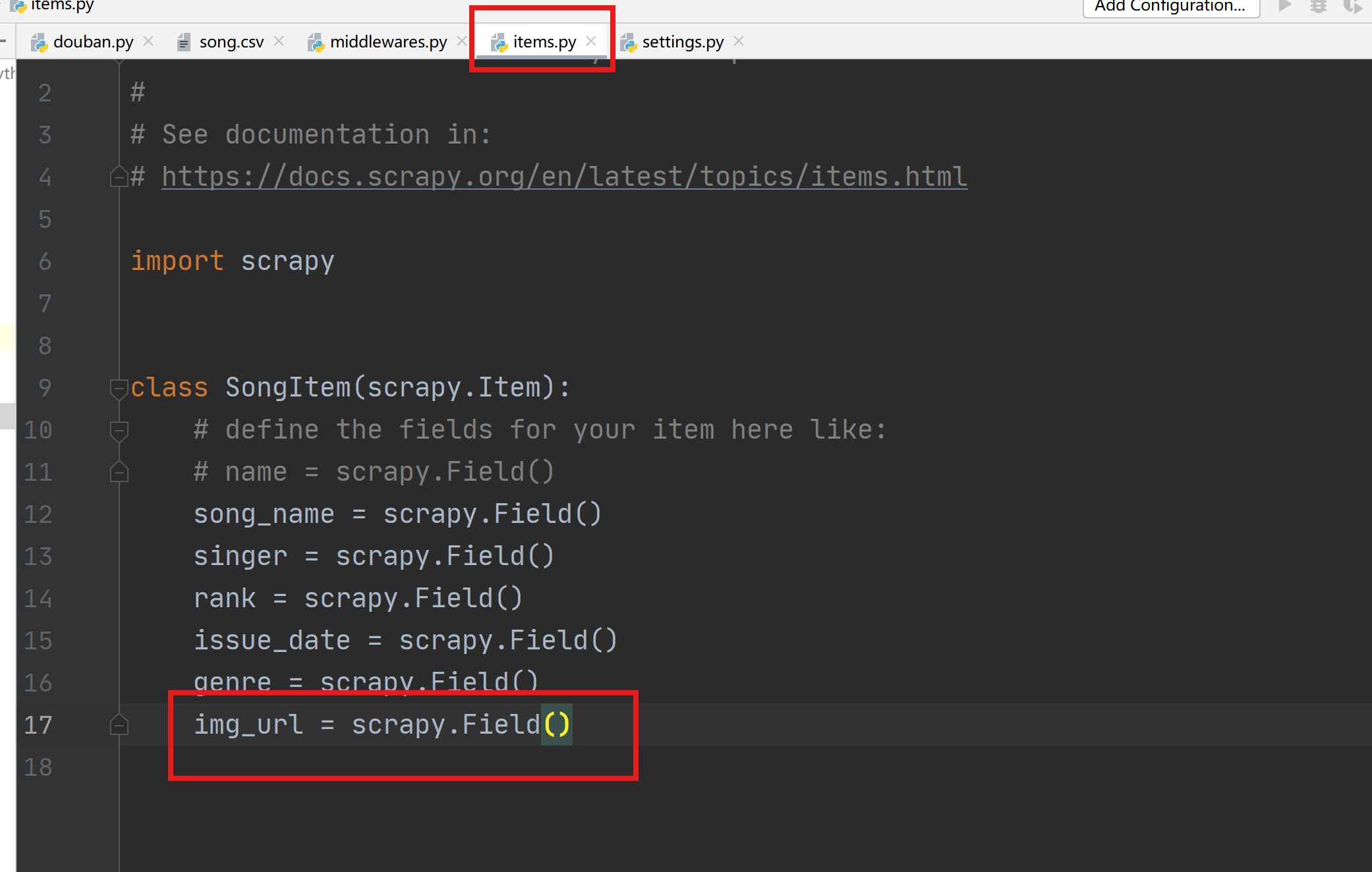
1.4 items.py设置
继承scrapy.Item的自定义类SongItem,导入到主程序douban.py中用于存储爬取的字段。
1.5 settings.py设置
用于控制Scrapy框架中各部件的参数,例如USER_AGENT、COOKIES、代理、中间件启停等。
修改USER_AGENT,模拟浏览器登录。
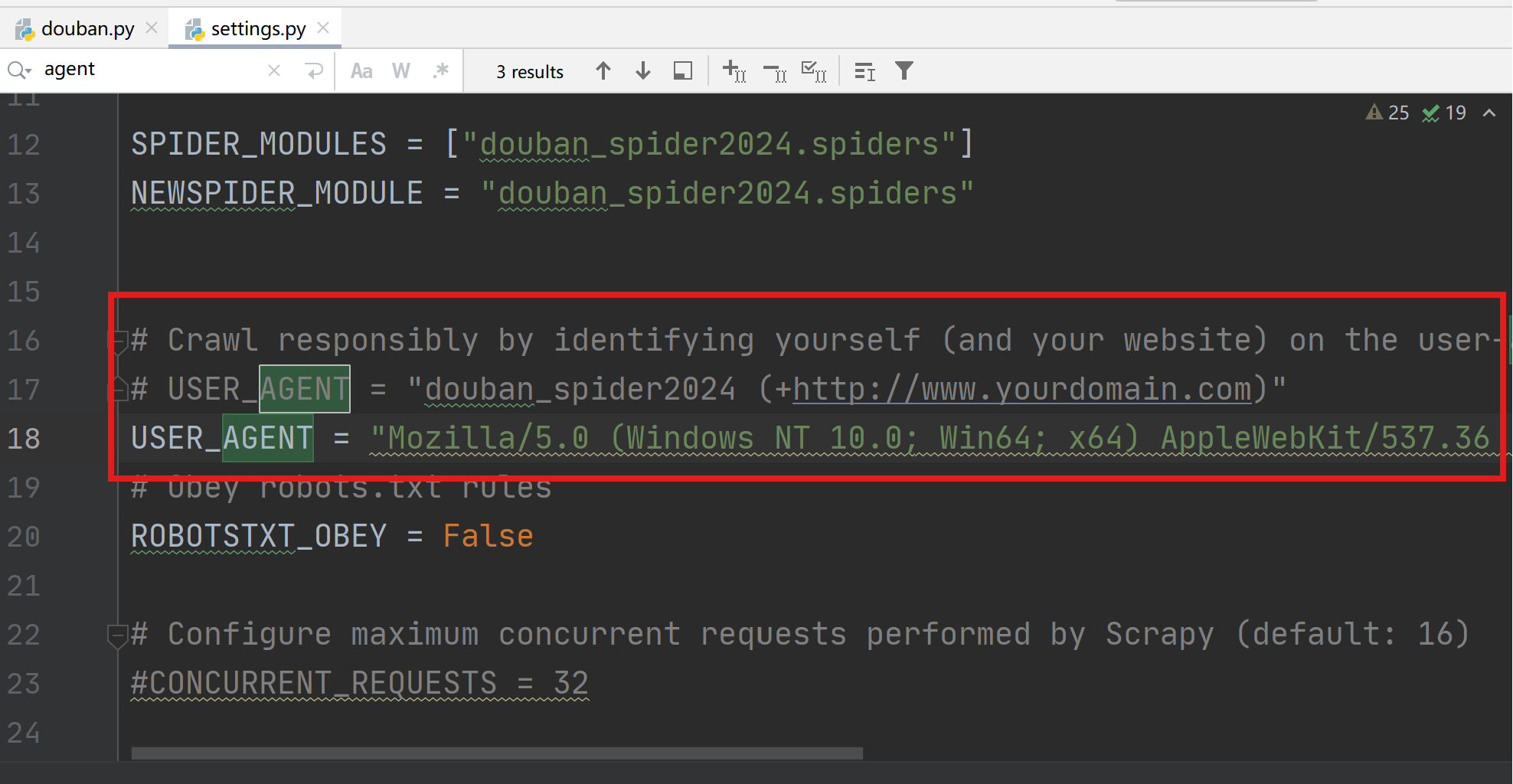
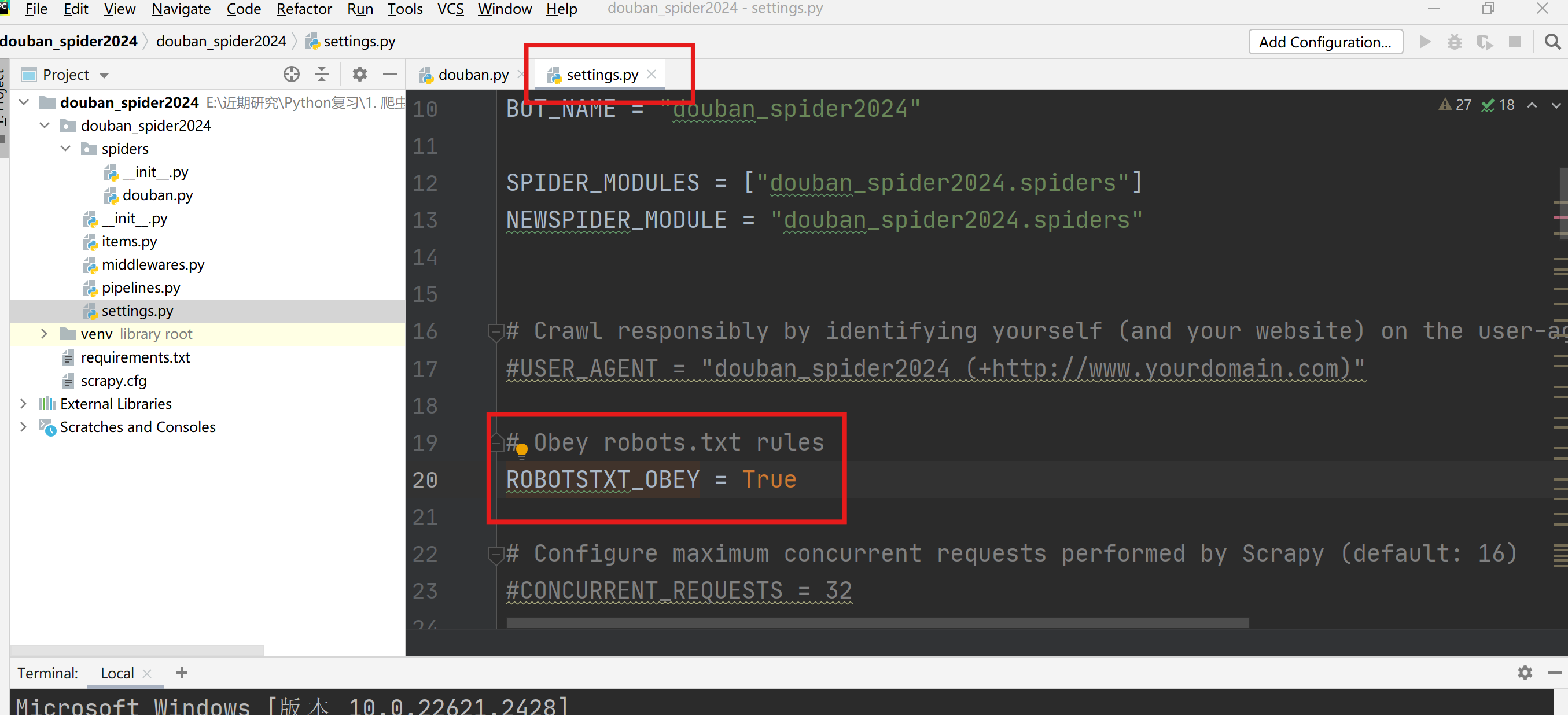
关闭Obey robots.txt rules,将True设置为False。
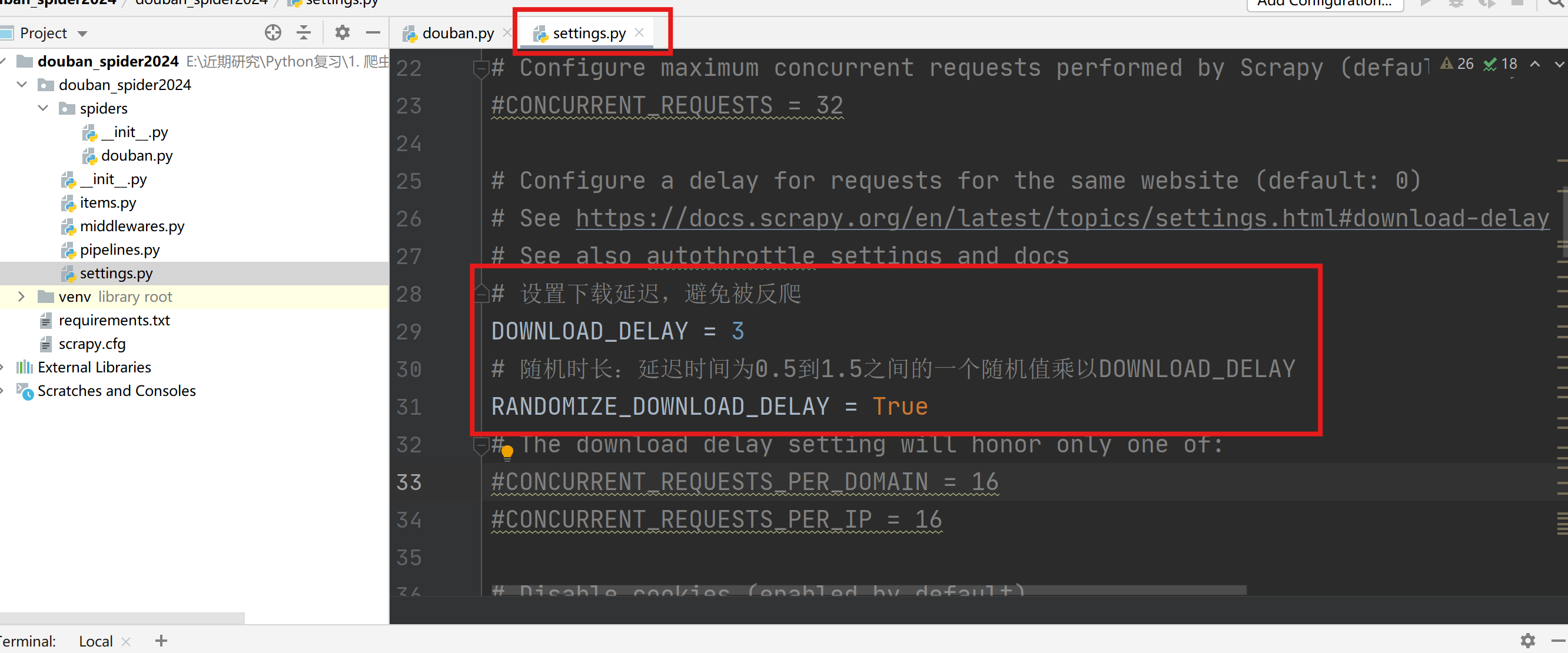
设置下载延迟
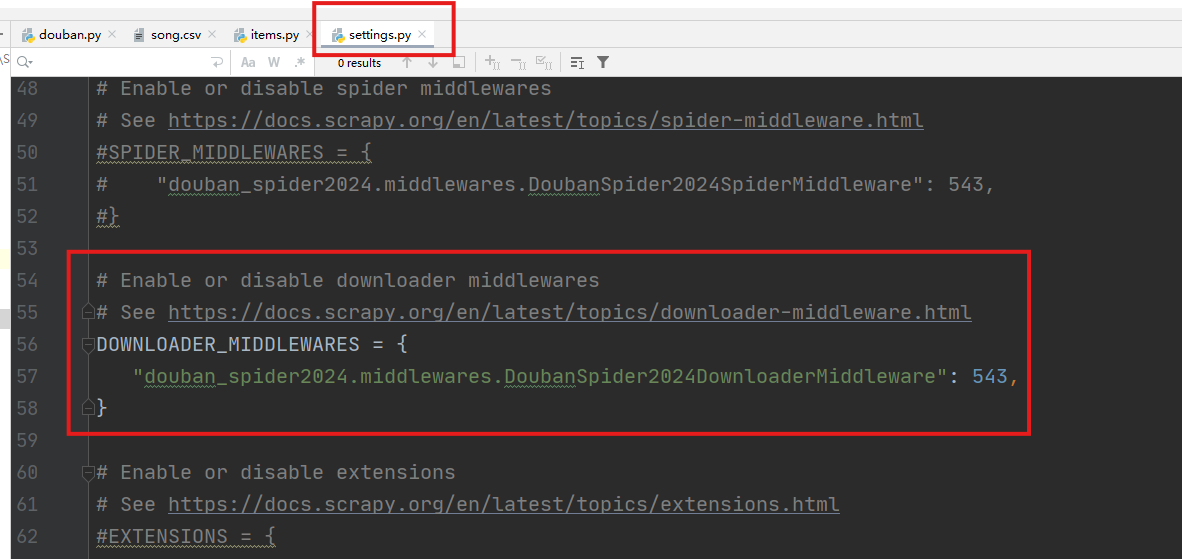
打开下载中间件(downloader_middlewares),实现拦截并修改Request的请求内容。
1.6 middlewares.py设置
cookies设置
进入middlewares.py程序中设置,新增一个处理cookies的函数,执行cookies函数返回一个包含cookies的字典COOKIE_ITEM。
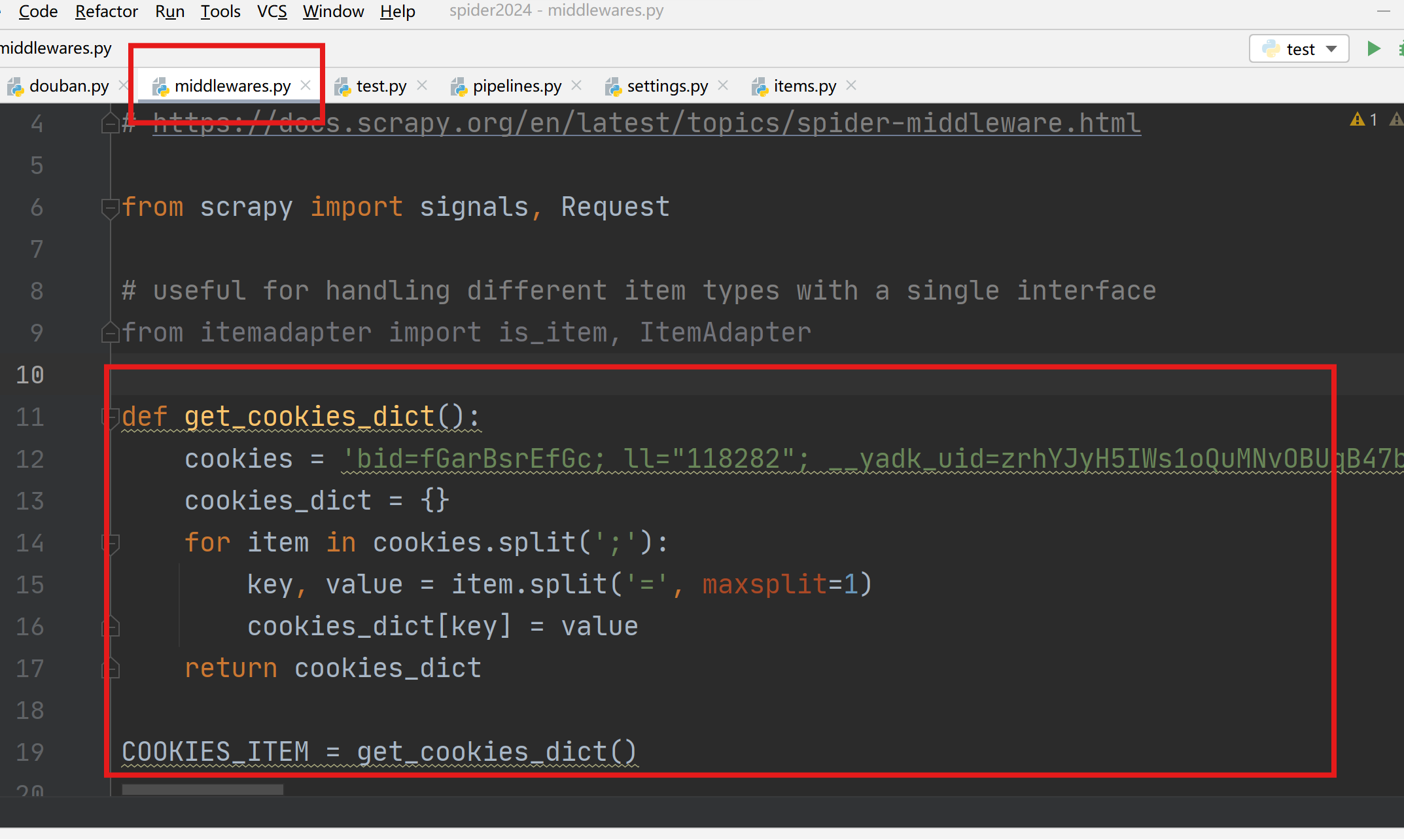
在xxDownloaderMiddleware类中process_request函数配置COOKIES_ITEM。
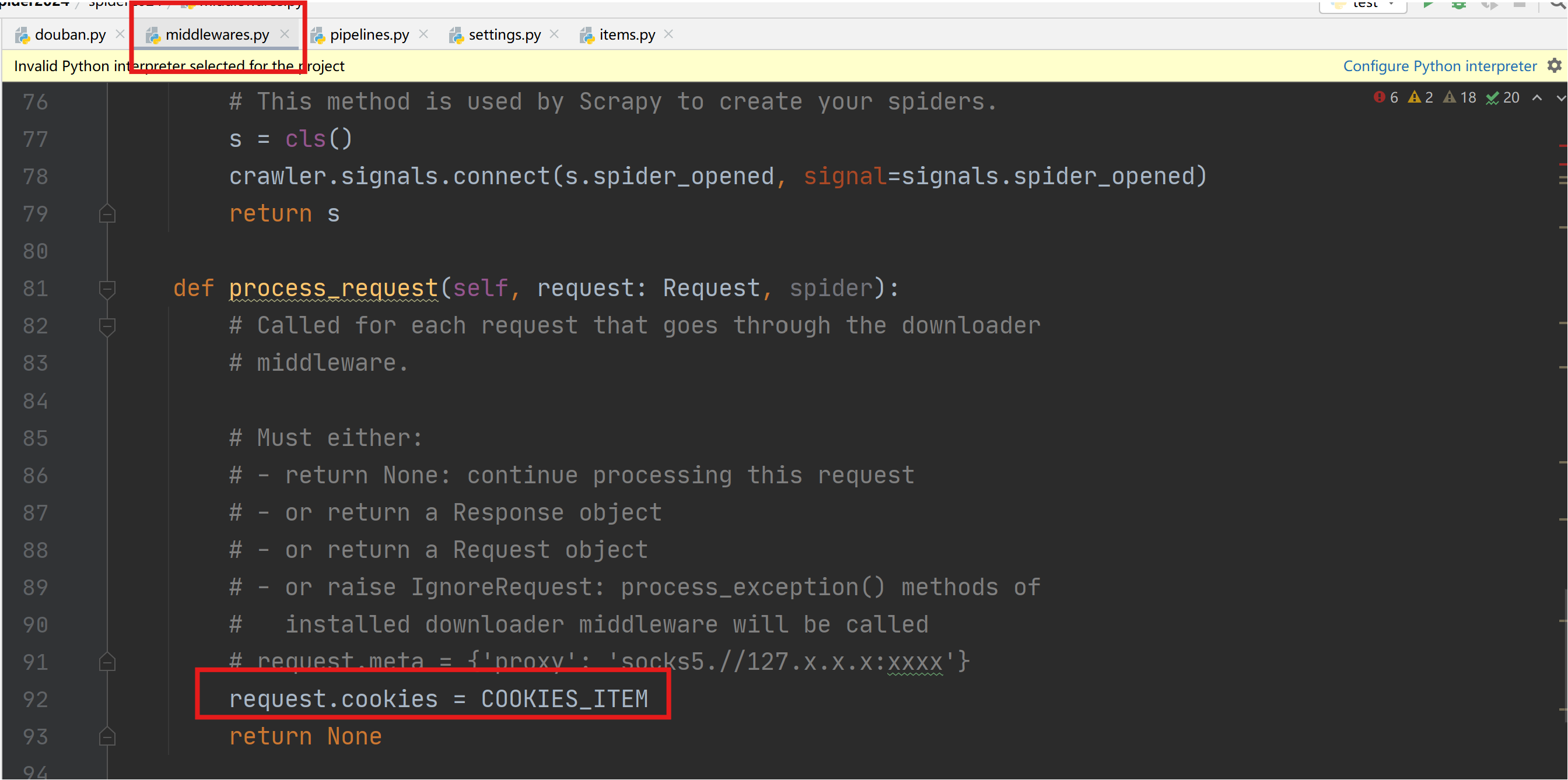
scrapy 利用sock代理??
1.7 多层url解析
利用回调函数解析多层url:在parse函数最后解析获取新的url,并提交新的Request,并传递item到回调函数parse_detail中解析。
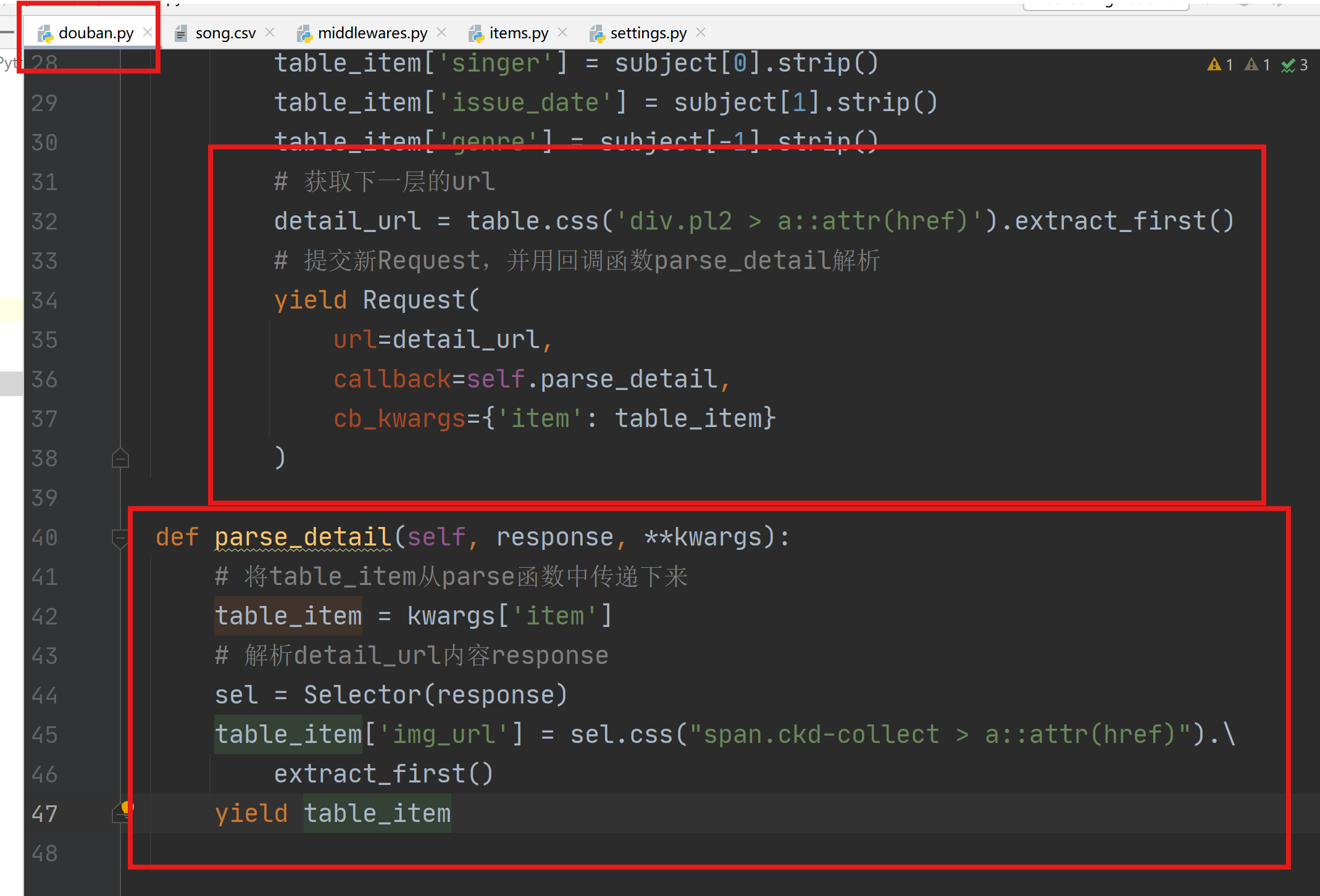
在items.py中添加新的item信息。
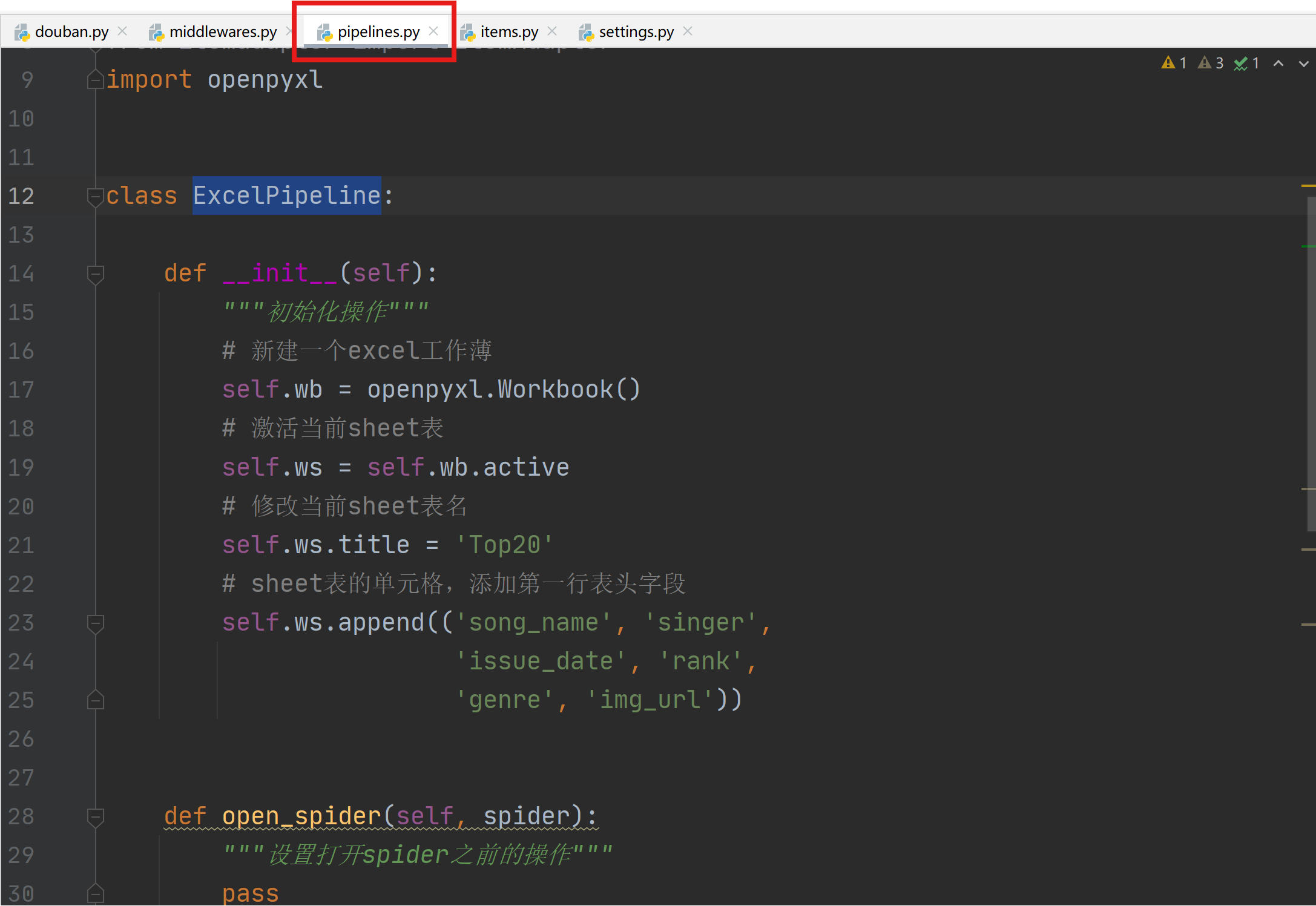
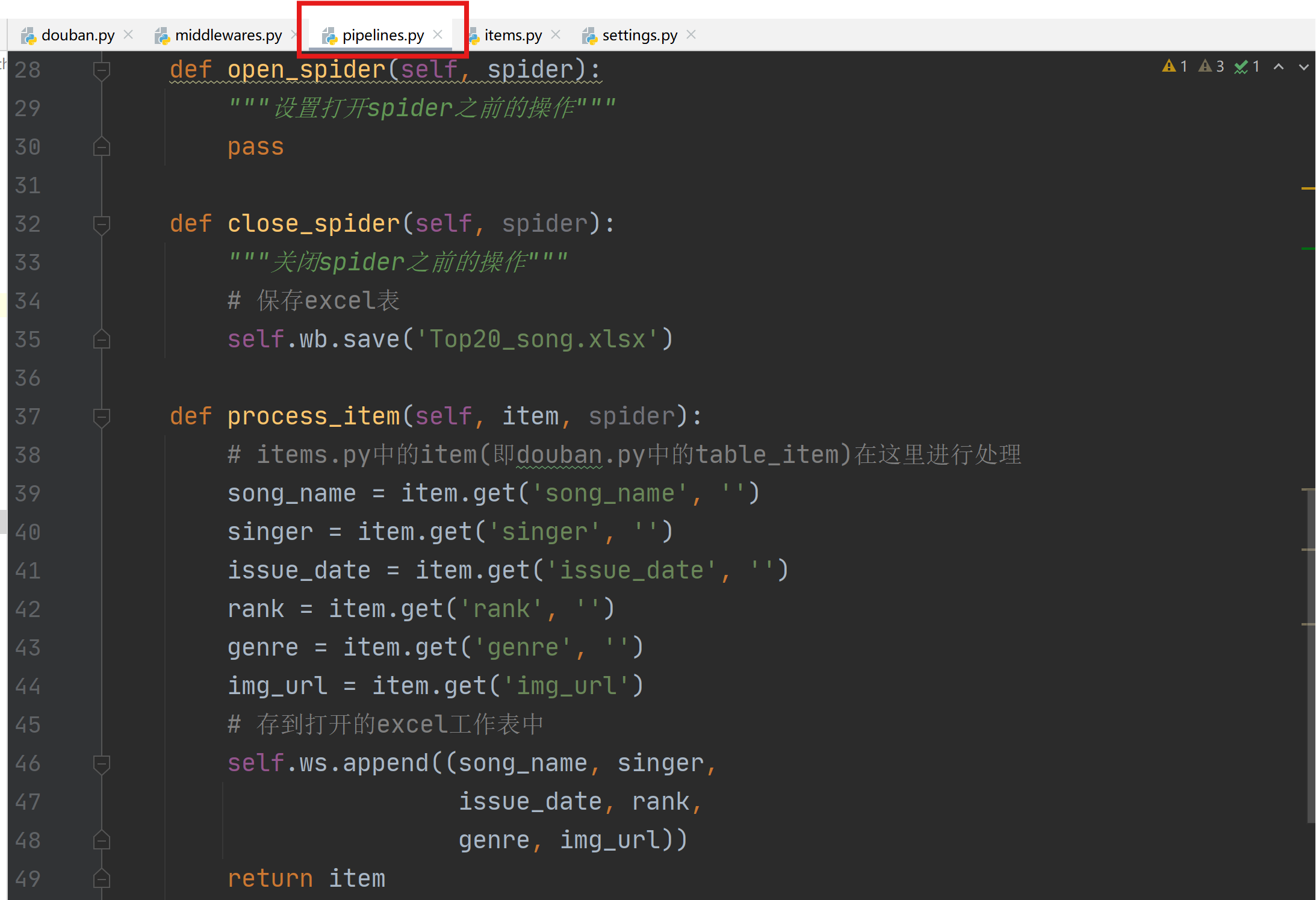
1.8 pipelines.py设置
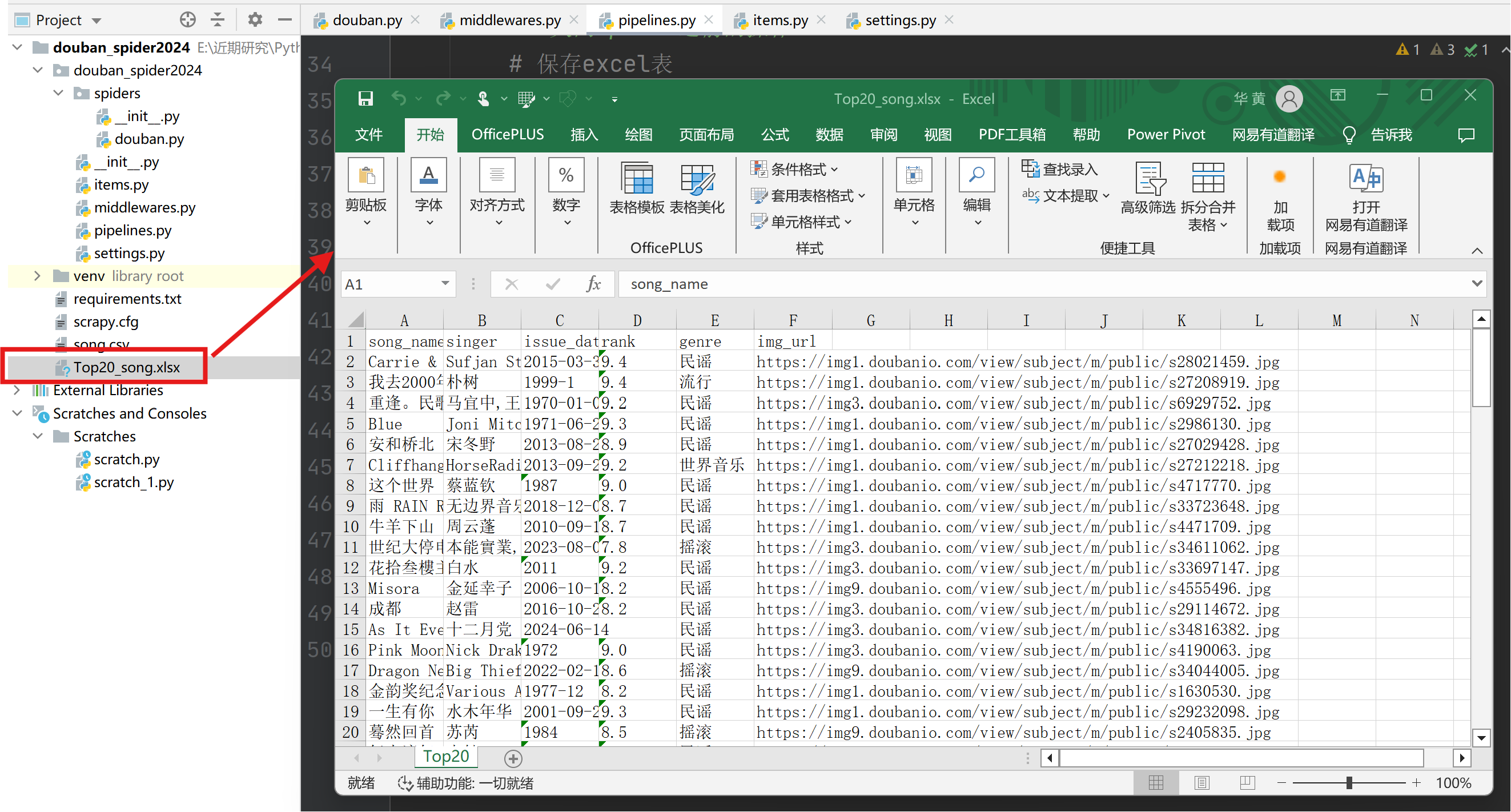
通过pipelines.py构建Excel存储管道,用于将爬取的数据存储到excel中。
七、Scrapy框架-案例1的更多相关文章
- 爬虫——Scrapy框架案例二:阳光问政平台
阳光热线问政平台 URL地址:http://wz.sun0769.com/index.php/question/questionType?type=4&page= 爬取字段:帖子的编号.投诉类 ...
- 爬虫——Scrapy框架案例一:手机APP抓包
以爬取斗鱼直播上的信息为例: URL地址:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0 爬取字段:房间ID. ...
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- python爬虫入门(七)Scrapy框架之Spider类
Spider类 Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作 ...
- 爬虫(十四):Scrapy框架(一) 初识Scrapy、第一个案例
1. Scrapy框架 Scrapy功能非常强大,爬取效率高,相关扩展组件多,可配置和可扩展程度非常高,它几乎可以应对所有反爬网站,是目前Python中使用最广泛的爬虫框架. 1.1 Scrapy介绍 ...
- 09 Scrapy框架在爬虫中的使用
一.简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.它集成高性能异步下载,队列,分布式,解析,持久化等. Scrapy 是基于twisted框架开发而来,twisted是一个 ...
- 网络爬虫第五章之Scrapy框架
第一节:Scrapy框架架构 Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
随机推荐
- MySQL预处理语句PREPARE、EXECUTE、DEALLOCATE使用大全
说明 MySQL官方将PREPARE.EXECUTE.DEALLOCATE统称为PREPARE STATEMENT,我习惯称其为[预处理语句]. 其语法为: PREPARE stmt_name FRO ...
- SUM_ACM-Codeforces Round 941 (Div. 2)
A Card Exchange https://codeforces.com/contest/1966/problem/A 思路:找规律,如果b>a,输出a,如果a中有大于等于b个数,输出b-1 ...
- 深入理解Spring Boot:Bean管理、原理解析与Maven高级应用
深入理解Spring Boot:Bean管理.原理解析与Maven高级应用 前言 大家好,今天我们来聊聊Spring Boot的核心内容,包括Bean管理.Spring Boot的工作原理以及Mave ...
- RIME:用交叉熵 loss 大小分辨 preference 是否正确 + 内在奖励预训练 reward model
文章题目:RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences,ICML 2024 Spotlight ...
- 备份服务器eBackup
目录 软件包方式安装eBackup备份软件 1.前景提要 2.创建虚拟机 3.安装备份软件. 4.安装 eBackup 补丁 5.配置 eBackup 服务器 6.访问web界 ...
- LangChain的LCEL和Runnable你搞懂了吗
LangChain的LCEL估计行业内的朋友都听过,但是LCEL里的RunnablePassthrough.RunnableParallel.RunnableBranch.RunnableLambda ...
- 【Vue】el-table 简易表格可筛选列
需求实现: 代码逻辑: 按钮控件: <el-popover placement="top-start"> <el-checkbox-group v-model=& ...
- 【Java-GUI】08 Swing02 边框和选择器
边框案例: package cn.dzz.swing; import javax.swing.*; import javax.swing.border.*; import java.awt.*; pu ...
- java多线程之-不可变final
1.背景 final这个关键字相信大家不陌生吧... 看看下面的案例 2.时间格式化之线程不安全SimpleDateFormat package com.ldp.demo08final; import ...
- Apache DolphinScheduler如何开启开机自启动功能?
转载自东华果汁哥 Apache DolphinScheduler 是一个分布式.去中心化的大数据工作流调度系统,支持大数据任务调度.若要设置 DolphinScheduler 开机自启动,通常需要将其 ...