支持向量机SVM:从数学原理到实际应用
本篇文章全面深入地探讨了支持向量机(SVM)的各个方面,从基本概念、数学背景到Python和PyTorch的代码实现。文章还涵盖了SVM在文本分类、图像识别、生物信息学、金融预测等多个实际应用场景中的用法。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、引言
背景
支持向量机(SVM, Support Vector Machines)是一种广泛应用于分类、回归、甚至是异常检测的监督学习算法。自从Vapnik和Chervonenkis在1995年首次提出,SVM算法就在机器学习领域赢得了巨大的声誉。这部分因为其基于几何和统计理论的坚实数学基础,也因为其在实际应用中展示出的出色性能。
例子:比如,在人脸识别或者文本分类问题上,SVM常常能够实现优于其他算法的准确性。
SVM算法的重要性
SVM通过寻找能够最大化两个类别间“间隔”的决策边界(或称为“超平面”)来工作,这使得其在高维空间中具有良好的泛化能力。
例子:在垃圾邮件分类问题中,可能有数十甚至数百个特征,SVM能有效地在这高维特征空间中找到最优决策边界。
二、SVM基础
线性分类器简介
支持向量机(SVM)属于线性分类器的一种,旨在通过一个决策边界将不同的数据点分开。在二维平面中,这个决策边界是一条直线;在三维空间中是一个平面,以此类推,在N维空间,这个决策边界被称为“超平面”。
例子: 在二维平面上有红色和蓝色的点,线性分类器(如SVM)会寻找一条直线,尽量使得红色点和蓝色点被分开。
什么是支持向量?
在SVM算法中,"支持向量"是指距离超平面最近的那些数据点。这些数据点被用于确定超平面的位置和方向,因为它们最有可能是分类错误的点。
例子: 在一个用于区分猫和狗的分类问题中,支持向量可能是一些极易被误分类的猫或狗的图片,例如长得像猫的狗或者长得像狗的猫。
超平面和决策边界
超平面是SVM用来进行数据分类的决策边界。在二维空间里,超平面就是一条直线;在三维空间里是一个平面,以此类推。数学上,一个N维的超平面可以表示为(Ax + By + ... + Z = 0)的形式。
例子: 在一个文本分类问题中,你可能使用词频和其他文本特征作为维度,超平面就是在这个多维空间里划分不同类别(如垃圾邮件和非垃圾邮件)的决策边界。
SVM的目标函数
SVM的主要目标是找到一个能“最大化”支持向量到超平面距离的超平面。数学上,这被称为“最大化间隔”。目标函数通常是一个凸优化问题,可通过各种算法(如梯度下降、SMO算法等)求解。
例子: 在信用卡欺诈检测系统中,SVM的目标是找到一个能最大化“良性”交易和“欺诈”交易之间间隔的超平面,以便能更准确地分类新的交易记录。
三、数学背景和优化
拉格朗日乘子法(Lagrange Multipliers)
拉格朗日乘子法是一种用于求解约束优化问题的数学方法,特别适用于支持向量机(SVM)中的优化问题。基础形式的拉格朗日函数(Lagrangian Function)可以表示为:
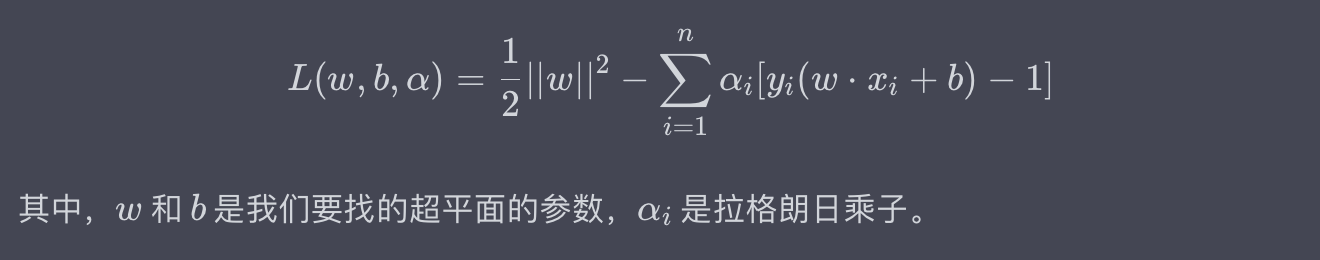
例子:在一个二分类问题中,你可能需要最小化(w) 的范数(即,优化模型的复杂度)的同时,确保所有的样本都被正确分类(或尽可能地接近这个目标)。拉格朗日乘子法正是解决这种问题的一种方法。
KKT条件
Karush-Kuhn-Tucker(KKT)条件是非线性规划问题中的一组必要条件,也用于SVM中的优化问题。它是拉格朗日乘子法的一种扩展,用于处理不等式约束。在SVM中,KKT条件主要用来检验一个给定的解是否是最优解。
例子:在SVM模型中,KKT条件能帮助我们验证找到的超平面是否是最大化间隔的超平面,从而确认模型的优越性。
核技巧(Kernel Trick)
核技巧是一种在高维空间中隐式计算数据点之间相似度的方法,而无需实际进行高维计算。这让SVM能够有效地解决非线性问题。常用的核函数包括线性核、多项式核、径向基核(RBF)等。
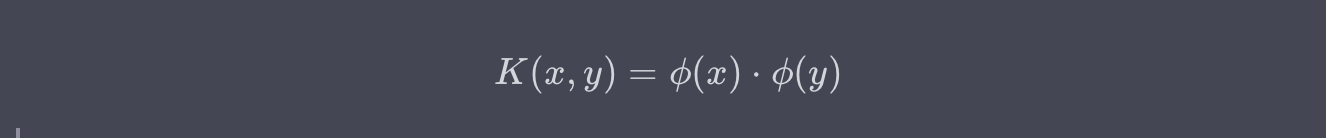
例子:如果你在一个文本分类任务中遇到了非线性可分的数据,使用核技巧可以在高维空间中找到一个能够将数据有效分开的决策边界。
双重问题和主问题(Dual and Primal Problems)
在SVM中,优化问题通常可以转换为其对偶问题,这样做的好处是对偶问题往往更容易求解,并且能更自然地引入核函数。双重问题与主问题通过所谓的对偶间隙(duality gap)联系在一起,而当对偶间隙为0时,双重问题的解即为主问题的解。
例子:在处理大规模数据集时,通过解决双重问题而不是主问题,可以大大减少计算复杂性和时间。
四、代码实现
在这一部分中,我们将使用Python和PyTorch库来实现一个基础的支持向量机(SVM)。我们会遵循以下几个主要步骤:
- 数据预处理:准备用于训练和测试的数据。
- 模型定义:定义SVM模型的架构。
- 优化器选择:选择合适的优化算法。
- 训练模型:使用训练数据来训练模型。
- 评估模型:使用测试数据来评估模型的性能。
数据预处理
首先,我们需要准备一些用于训练和测试的数据。为简单起见,我们使用PyTorch内置的Tensor数据结构。
import torch
# 创建训练数据和标签
X_train = torch.FloatTensor([[1, 1], [1, 2], [1, 3], [2, 1], [2, 2], [2, 3]])
y_train = torch.FloatTensor([1, 1, 1, -1, -1, -1])
# 创建测试数据
X_test = torch.FloatTensor([[1, 0.5], [2, 0.5]])
例子:
X_train中的数据表示二维平面上的点,而y_train中的数据则代表这些点的标签。例如,点(1, 1)的标签是1,而点(2, 3)的标签是-1。
模型定义
下面我们定义SVM模型。在这里,我们使用线性核函数。
class LinearSVM(torch.nn.Module):
def __init__(self):
super(LinearSVM, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(2), requires_grad=True)
self.bias = torch.nn.Parameter(torch.rand(1), requires_grad=True)
def forward(self, x):
return torch.matmul(x, self.weight) + self.bias
例子: 在这个例子中,我们定义了一个线性SVM模型。
self.weight和self.bias是模型的参数,它们在训练过程中会被优化。
优化器选择
我们将使用PyTorch的内置SGD(随机梯度下降)作为优化器。
# 实例化模型和优化器
model = LinearSVM()
optimizer = torch.optim.SGD([model.weight, model.bias], lr=0.01)
训练模型
下面的代码段展示了如何训练模型:
# 设置训练轮次和正则化参数C
epochs = 100
C = 0.1
for epoch in range(epochs):
for i, x in enumerate(X_train):
y = y_train[i]
optimizer.zero_grad()
# 计算间隔损失 hinge loss: max(0, 1 - y*(wx + b))
loss = torch.max(torch.tensor(0), 1 - y * model(x))
# 添加正则化项: C * ||w||^2
loss += C * torch.norm(model.weight)**2
loss.backward()
optimizer.step()
例子: 在这个例子中,我们使用了hinge loss作为损失函数,并添加了正则化项
C * ||w||^2以防止过拟合。
评估模型
最后,我们使用测试数据来评估模型的性能。
with torch.no_grad():
for x in X_test:
prediction = model(x)
print(f"Prediction for {x} is: {prediction}")
例子: 输出的“Prediction”表示模型对测试数据点的分类预测。一个正数表示类别
1,一个负数表示类别-1。
五、实战应用
支持向量机(SVM)在各种实际应用场景中都有广泛的用途。
文本分类
在文本分类任务中,SVM可以用来自动地对文档或消息进行分类。例如,垃圾邮件过滤器可能使用SVM来识别垃圾邮件和正常邮件。
例子: 在一个新闻网站上,可以使用SVM模型来自动将新闻文章分为“政治”、“体育”、“娱乐”等不同的类别。
图像识别
SVM也被用于图像识别任务,如手写数字识别或面部识别。通过使用不同的核函数,SVM能够在高维空间中找到决策边界。
例子: 在安全监控系统中,SVM可以用于识别不同的人脸并进行身份验证。
生物信息学
在生物信息学领域,SVM用于识别基因序列模式,以及用于药物发现等多个方面。
例子: 在疾病诊断中,SVM可以用于分析基因表达数据,以识别是否存在特定疾病的风险。
金融预测
SVM在金融领域也有一系列应用,如用于预测股票价格的走势或者用于信用评分。
例子: 在信用卡欺诈检测中,SVM可以用于分析消费者的交易记录,并自动标识出可能的欺诈性交易。
客户细分
在市场分析中,SVM可以用于客户细分,通过分析客户的购买历史、地理位置等信息,来预测客户的未来行为。
例子: 在电子商务平台上,SVM模型可以用于预测哪些客户更有可能购买特定的产品。
六、总结
支持向量机(SVM)是一种强大而灵活的机器学习算法,具有广泛的应用场景和优秀的性能表现。从文本分类到图像识别,从生物信息学到金融预测,SVM都表现出其强大的泛化能力。在这篇文章中,我们不仅介绍了SVM的基本概念、数学背景和优化方法,还通过具体的Python和PyTorch代码实现了一个基础的SVM模型。此外,我们还探讨了SVM在多个实际应用场景中的用法。
虽然SVM被广泛应用于各种问题,但它并非“一把通吃”的工具。在高维空间和大数据集上,SVM模型可能会遇到计算复杂性和内存使用的问题。此时,适当的核函数选择、数据预处理和参数优化尤为重要。
值得注意的是,随着深度学习的兴起,一些更为复杂的模型(如神经网络)在某些特定任务上可能会表现得更好。然而,SVM因其解释性强、理论基础坚实而依然保有一席之地。实际上,在某些应用场景下,如小数据集或者对模型可解释性有高要求的情境,SVM可能是更好的选择。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
支持向量机SVM:从数学原理到实际应用的更多相关文章
- SVM数学原理推导&鸢尾花实例
//看了多少遍SVM的数学原理讲解,就是不懂,对偶形式推导也是不懂,看来我真的是不太适合学数学啊,这是面试前最后一次认真的看,并且使用了sklearn包中的SVM来进行实现了一个鸢尾花分类的实例,进行 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- SVM数学原理推导
//2019.08.17 #支撑向量机SVM(Support Vector Machine)1.支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- 机器学习——支持向量机(SVM)之拉格朗日乘子法,KKT条件以及简化版SMO算法分析
SVM有很多实现,现在只关注其中最流行的一种实现,即序列最小优化(Sequential Minimal Optimization,SMO)算法,然后介绍如何使用一种核函数(kernel)的方式将SVM ...
- 机器学习(二)—支持向量机SVM
1.SVM的原理是什么? SVM是一种二类分类模型.它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器.(间隔最大是它有别于感知机) 试图寻找一个超平面来对样本分割,把样本中的正例和反例 ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- [白话解析] 深入浅出支持向量机(SVM)之核函数
[白话解析] 深入浅出支持向量机(SVM)之核函数 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解支持向量机中的核函数概念,并且给大家虚构了一个水浒传的例子来做进一步的通俗 ...
- 支持向量机SVM基本问题
1.SVM的原理是什么? SVM是一种二类分类模型.它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器.(间隔最大是它有别于感知机) 试图寻找一个超平面来对样本分割,把样本中的正例和反例 ...
- 【IUML】支持向量机SVM
从1995年Vapnik等人提出一种机器学习的新方法支持向量机(SVM)之后,支持向量机成为继人工神经网络之后又一研究热点,国内外研究都很多.支持向量机方法是建立在统计学习理论的VC维理论和结构风险最 ...
随机推荐
- 树形DP + 换根DP
树形DP--基础 P1352 没有上司的舞会 设 \(f[i][0/1]\) 表示第 \(i\) 个人不去或者去. 如果第 \(i\) 个人没去,那么下属可去可不去,所以 \(f[i][0] = \s ...
- Win10 下 tensorflow-gpu 2.5 环境搭建
Win10 下 tensorflow-gpu 2.5 环境搭建 简介 机器学习环境搭建,tensorflow_gpu-2.5.0 + CUDA 11.2 + CUDNN 8.1 :环境必须是这个,具体 ...
- 处理css/js兼容性的工具之超重要的browserslist
这篇 webpack处理css资源 文章中使用到的工具 browserslist 对于兼容性处理来说非常重要!这一篇来仔细说说. 查询兼容性 不同浏览器对于 css / js 的属性可能存在兼容性,具 ...
- 【Nacos篇】Nacos基本操作及配置
官方文档:https://nacos.io/zh-cn/docs/v2/ecology/use-nacos-with-spring-cloud.html 前置条件:SpringCloud脚手架 单机模 ...
- redis开启多线程
在Redis 6.0中,非常受关注的第一个新特性就是多线程. 在Redis 6.0中,多线程默认是禁用的,只使用主线程.如果需要使用多线程功能,需要在 redis.conf文件中进行配置(重启服务). ...
- Cookies 完全指南
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:佳岚 前言 Cookie实际上是一小段的文本信息,它产生的 ...
- Visual Studio Code(vscode)下载慢 插件安装失败解决方案
目录 一.系统环境 二.前言 三.Visual Studio Code(vscode)简介 四.解决Visual Studio Code(vscode)下载慢的问题 4.1 问题描述 4.2 解决方案 ...
- 《SQL与数据库基础》16. 锁
目录 锁 全局锁 表级锁 表锁 元数据锁 意向锁 行级锁 行锁 间隙锁 临键锁 本文以 MySQL 为例 锁 锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源(CPU. ...
- Iphone通过ssh进行访问
Iphone通过usb进行ssh访问文件系统 在公司里wifi很不给力,而我又想通过ssh访问我的iphone,进行一些权限访问,这时我们该 itunnel_mux_rev71这个工具可以帮我们的忙 ...
- Falcon-7B大型语言模型在心理健康对话数据集上使用QLoRA进行微调
文本是参考文献[1]的中文翻译,主要讲解了Falcon-7B大型语言模型在心理健康对话数据集上使用QLoRA进行微调的过程.项目GitHub链接为https://github.com/iamaru ...