DataWorks搬站方案:Azkaban作业迁移至DataWorks
DataWorks迁移助手提供任务搬站功能,支持将开源调度引擎Oozie、Azkaban、Airflow的任务快速迁移至DataWorks。本文主要介绍如何将开源Azkaban工作流调度引擎中的作业迁移至DataWorks上。
支持迁移的Azkaban版本
支持全部版本的Azkaban迁移。
整体迁移流程
迁移助手支持开源工作流调度引擎到DataWorks体系的大数据开发任务迁移的基本流程如下图所示。
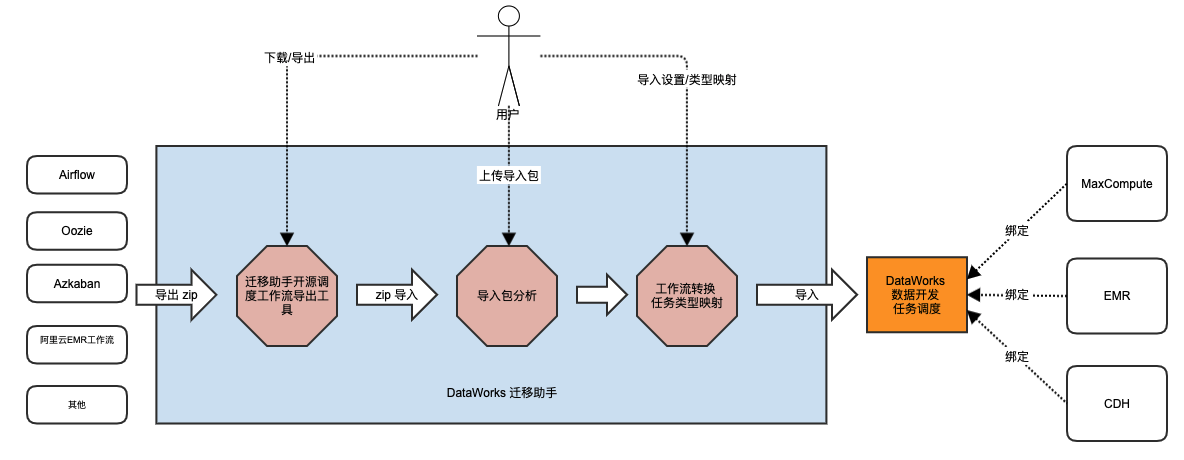
针对不同的开源调度引擎,DataWorks迁移助手会出一个相关的任务导出方案。
整体迁移流程为:通过迁移助手调度引擎作业导出能力,将开源调度引擎中的作业导出;再将作业导出包上传至迁移助手中,通过任务类型映射,将映射后的作业导入至DataWorks中。作业导入时可设置将任务转换为MaxCompute类型作业、EMR类型作业、CDH类型作业等。
Azkaban作业导出
Azkaban工具本身具备导出工作流的能力,有自己的Web控制台,如下图所示:
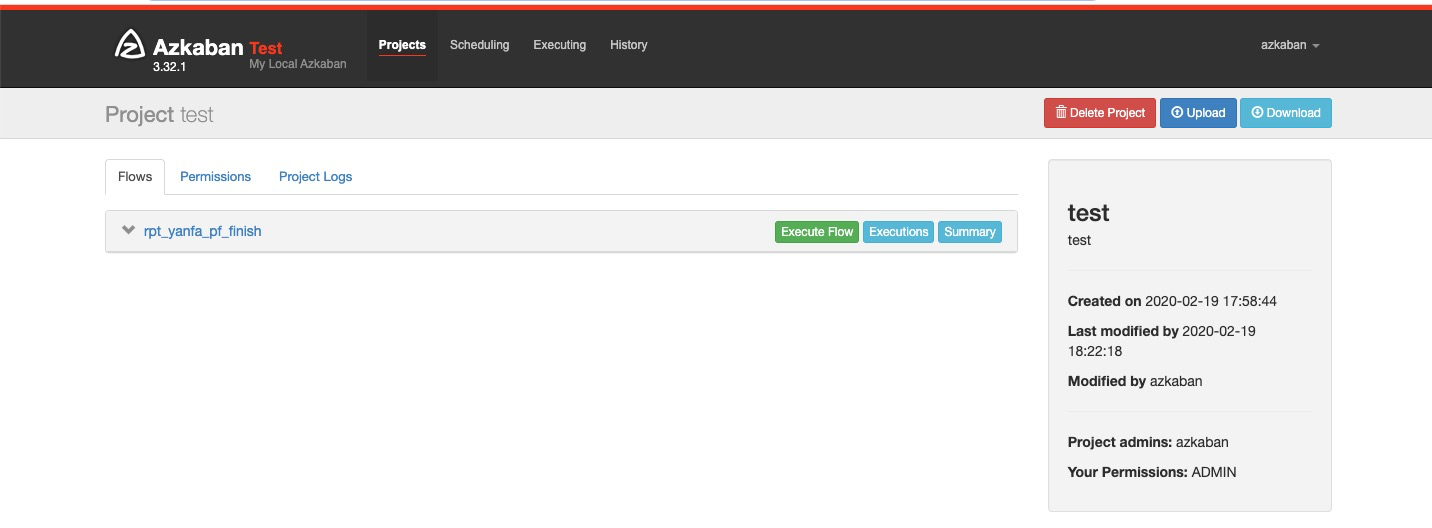
Azkaban界面支持直接Download某个Flow。Flow的导出流程:
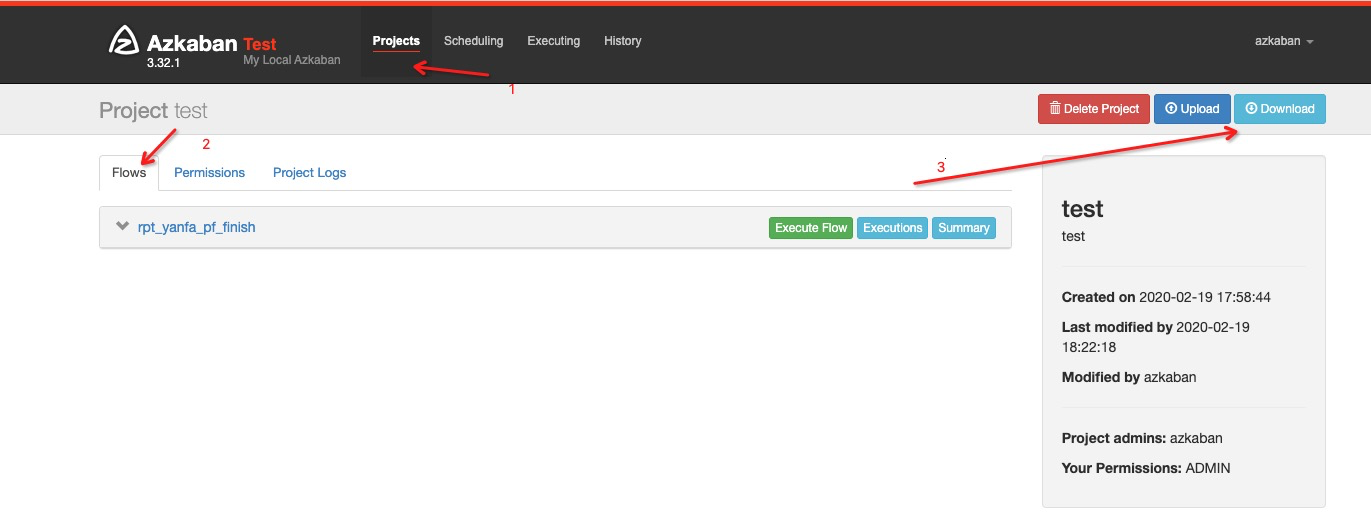
操作步骤:
1.进入Project页面
2.点击Flows,会列出Project下面所有的工作流(Flow)
3.点击Download即可下载Project的导出文件
Azkaban导出包格式原生Azkaban即可,导出包Zip文件内部为Azakaban的某个Project的所有任务(Job)和关系信息。
Azkaban作业导入
拿到了开源调度引擎的导出任务包后,用户可以拿这个zip包到迁移助手的迁移助手->任务上云->调度引擎作业导入页面上传导入包进行包分析。
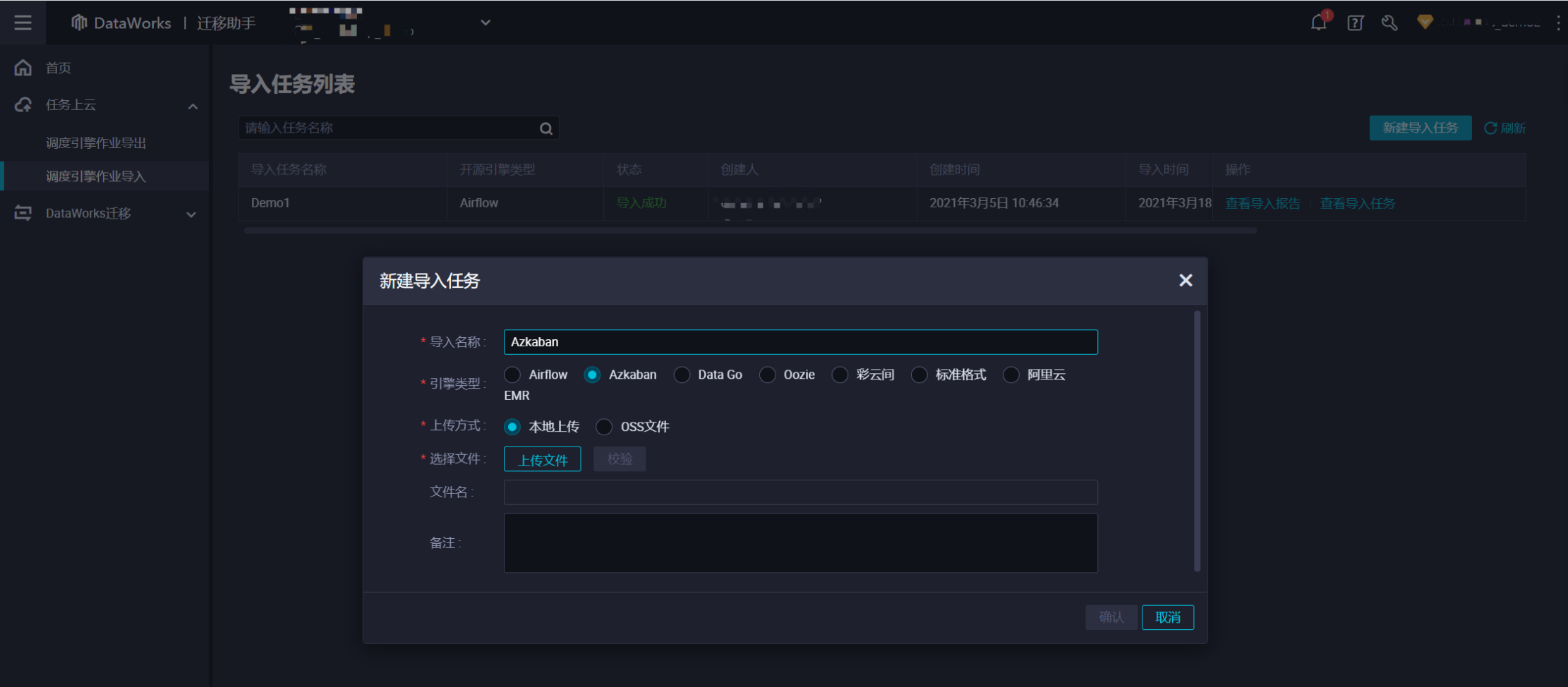
导入包分析成功后点击确认,进入导入任务设置页面,页面中会展示分析出来的调度任务信息。
开源调度导入设置
用户可以点击高级设置,设置Azkaban任务与DataWorks任务的转换关系。不同的开源调度引擎,在高级设置里面的设置界面基本一致,如下图:
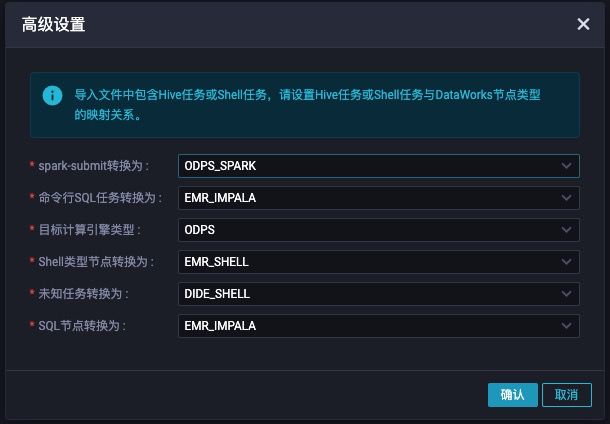
高级设置项介绍:
- sparkt-submit转换为:导入过程会去分析用户的任务是不是sparkt-submit任务,如果是的话,会将spark-submit任务转换为对应的DataWorks任务类型,比如说:ODPS_SPARK/EMR_SPARK/CDH_SPARK等
- 命令行 SQL任务转换为:开源引擎很多任务类型是命令行运行SQL,比如说hive -e, beeline -e, impala-shell等等,迁移助手会根据用户选择的目标类型做对应的转换。比如可以转换成ODPS_SQL, EMR_HIVE, EMR_IMPALA, EMR_PRESTO, CDH_HIVE, CDH_PRESTO, CDH_IMPALA等等
- 目标计算引擎类型:这个主要是影响的是Sqoop同步的目的端的数据写入配置。我们会默认将sqoop命令转换为数据集成任务。计算引擎类型决定了数据集成任务的目的端数据源使用哪个计算引擎的project。
- Shell类型转换为:SHELL类型的节点在Dataworks根据不同计算引擎会有很多种,比如EMR_SHELL,CDH_SHELL,DataWorks自己的Shell节点等等。
- 未知任务转换为:对目前迁移助手无法处理的任务,我们默认用一个任务类型去对应,用户可以选择SHELL或者虚节点VIRTUAL
- SQL节点转换为:DataWorks上的SQL节点类型也因为绑定的计算引擎的不同也有很多种。比如 EMR_HIVE,EMR_IMPALA、EMR_PRESTO,CDH_HIVE,CDH_IMPALA,CDH_PRESTO,ODPS_SQL,EMR_SPARK_SQL,CDH_SPARK_SQL等,用户可以选择转换为哪种任务类型。
注意:这些导入映射的转换值是动态变化的,和当前项目空间绑定的计算引擎有关,转换关系如下。
导入至DataWorks + MaxCompute
|
设置项 |
可选值 |
|
sparkt-submit转换为 |
ODPS_SPARK |
|
命令行 SQL任务转换为 |
ODPS_SQL、ODPS_SPARK_SQL |
|
目标计算引擎类型 |
ODPS |
|
Shell类型转换为 |
DIDE_SHELL |
|
未知任务转换为 |
DIDE_SHELL、VIRTUAL |
|
SQL节点转换为 |
ODPS_SQL、ODPS_SPARK_SQL |
导入至DataWorks + EMR
|
设置项 |
可选值 |
|
sparkt-submit转换为 |
EMR_SPARK |
|
命令行 SQL任务转换为 |
EMR_HIVE, EMR_IMPALA, EMR_PRESTO, EMR_SPARK_SQL |
|
目标计算引擎类型 |
EMR |
|
Shell类型转换为 |
DIDE_SHELL, EMR_SHELL |
|
未知任务转换为 |
DIDE_SHELL、VIRTUAL |
|
SQL节点转换为 |
EMR_HIVE, EMR_IMPALA, EMR_PRESTO, EMR_SPARK_SQL |
导入至DataWorks + CDH
|
设置项 |
可选值 |
|
sparkt-submit转换为 |
CDH_SPARK |
|
命令行 SQL任务转换为 |
CDH_HIVE, CDH_IMPALA, CDH_PRESTO, CDH_SPARK_SQL |
|
目标计算引擎类型 |
CDH |
|
Shell类型转换为 |
DIDE_SHELL |
|
未知任务转换为 |
DIDE_SHELL、VIRTUAL |
|
SQL节点转换为 |
CDH_HIVE, CDH_IMPALA, CDH_PRESTO, CDH_SPARK_SQL |
执行导入
设置完映射关系后,点击开始导入即可。导入完成后,请进入数据开发中查看导入结果。
数据迁移
大数据集群上的数据迁移,可参考:DataWorks数据集成或MMA。
本文为阿里云原创内容,未经允许不得转载。
DataWorks搬站方案:Azkaban作业迁移至DataWorks的更多相关文章
- azkaban作业参数使用介绍
azkaban作业参数使用介绍 参数传递是调度系统工作流运行时非常重要的一部分,工作流的执行,单个作业的执行,多个工作流之间的依赖执行,历史任务重算,都涉及参数传递和同步. azkaban的工作流中的 ...
- 《Scrum实战》第3次课【富有成效的每日站会】作业汇总
1组 崔儒: http://kecyru.blog.163.com/blog/static/2741661732017626101944123/ 2017-07-26 孟帅: http://www.c ...
- BlueHost主机建站方案怎样选择?
BlueHost是知名美国主机商,近年来BlueHost不断加强中国市场客户的用户体验,提供多种主机租用方案,基本能够满足各类网站建设需求.下面就和大家介绍一下建站应该怎样选择主机. 1.中小型网站 ...
- 软件工程-东北师大站-第十次作业(PSP)
1.本周PSP 2.本周进度条 3.本周累计进度图 代码累计折线图 博文字数累计折线图 4.本周PSP饼状图
- 软件工程-东北师大站-第九次作业(PSP)
1.本周PSP 2.本周进度条 3.本周累计进度图 代码累计折线图 博文字数累计折线图 4.本周PSP饼状图
- 软件工程-东北师大站-第二次作业psp
1.本周PSP 2.本周进度条 3.本周累计进度图 代码累计折线图 博文字数累计折线图 本周PSP饼状图
- PHPCMS快速建站系列之网站迁移(本地到服务器,服务器迁移,更换域名等)
可能出现的问题: 1.后台登录验证码显示不正常(修改/caches/configs/system.php文件) //网站路径'web_path' => '/', 2.phpsso修改 如果不修改 ...
- 不同场景下 MySQL 的迁移方案
一 目录 一 目录 二 为什么要迁移 三 MySQL 迁移方案概览 四 MySQL 迁移实战 4.1 场景一 一主一从结构迁移从库 4.2 场景二 一主一从结构迁移指定库 4.3 场景三 一主一从结构 ...
- 开源WebGIS实施方案(六):空间数据(PostGIS)与GeoServer服务迁移
研发环境的变更,或者研发完成进行项目现场实施.运维的时候,经常就会面临数据及服务的迁移,这其中就包含空间数据以及GeoServer服务的迁移工作. 这里需要提醒的是:如果采用的是类似的开源WebGIS ...
- Linux下快速迁移海量文件的操作记录
有这么一种迁移海量文件的运维场景:由于现有网站服务器配置不够,需要做网站迁移(就是迁移到另一台高配置服务器上跑着),站点目录下有海量的小文件,大概100G左右,图片文件居多.目测直接拷贝过去的话,要好 ...
随机推荐
- View事件机制分析
目录介绍 01.Android中事件分发顺序 1.1 事件分发的对象是谁 1.2 事件分发的本质 1.3 事件在哪些对象间进行传递 1.4 事件分发过程涉及方法 1.5 Android中事件分发顺序 ...
- 超高并发下,Redis热点数据风险破解
★ Redis24篇集合 1 介绍 作者是互联网一线研发负责人,所在业务也是业内核心流量来源,经常参与 业务预定.积分竞拍.商品秒杀等工作. 近期参与多场新员工的面试工作,经常就 『超高并发场景下热点 ...
- 在 Google Colab 中使用 JuiceFS
Google Colaboratory(Colab)是一个由 Google 提供的云端 Jupyter 编程笔记本,直接通过浏览器即可进行 Python 编程.Colab 充分利用谷歌的闲置云计算资源 ...
- KingbaseES V8R6备份恢复案例之---sys_restore实现schema转换
**案例说明:** sys_restore用于sys_dump备份的数据恢复,在实际的应用中有需求,将从sys_dump备份对象从原schema中转换到到另外的schema,sys_restore支持 ...
- SQL调优系列--数据严重倾斜的连接优化
背景 对于两个大表关联的场景,如果过滤条件的列值,存在高度倾斜,可以考虑根据反向滤值,进行过滤操作,减少连接的CPU时间. 数据准备 -- 状态表 tp01_state 记录 大表tp01 记录的多种 ...
- 鸿蒙HarmonyOS实战-ArkUI组件(Swiper)
一.Swiper 1.概述 Swiper可以实现手机.平板等移动端设备上的图片轮播效果,支持无缝轮播.自动播放.响应式布局等功能.Swiper轮播图具有使用简单.样式可定制.功能丰富.兼容性好等优点, ...
- #SG函数#HDU 1848 Fibonacci again and again
题目 分析 可取状态只能是斐波那契数,求出SG函数 然后判断三个数sg函数异或和不为0先手必胜 代码 #include <cstdio> #include <cctype> # ...
- #树形dp#C 树上排列
分析 设\(dp[x][i]\)表示以\(x\)为根的子树中\(x\)的排名为\(i\)的方案数, 然后枚举子节点转移即可,Talk is cheap,Show me the code 代码 #inc ...
- docker运行javaWeb服务,操作文件异常
一.问题由来 部署一个测试服务在自己的服务器上面,然后运行其中的一个功能.然后报错,报错信息如下 二.问题分析 自己一开始也很疑惑,怎么会出现这个问题呢,自己明明把对应的文件放在对应的目录下面,并且已 ...
- Go 中的格式化字符串`fmt.Sprintf()` 和 `fmt.Printf()`
在 Go 中,可以使用 fmt.Sprintf() 和 fmt.Printf() 函数来格式化字符串,这两个函数类似于 C 语言中的 scanf 和 printf 函数. fmt.Sprintf() ...