知识图谱(Knowledge Graph)根本概念
2012年5月17日,Google 正式提出了知识图谱(Knowledge Graph)的概念,其初衷是为了优化搜索引擎返回的结果,增强用户搜索质量及体验。
假设我们想知道 “王健林的儿子” 是谁,百度或谷歌一下,搜索引擎会准确返回王思聪的信息,说明搜索引擎理解了用户的意图,知道我们要找 “王思聪”,而不是仅仅返回关键词为 “王健林的儿子” 的网页:
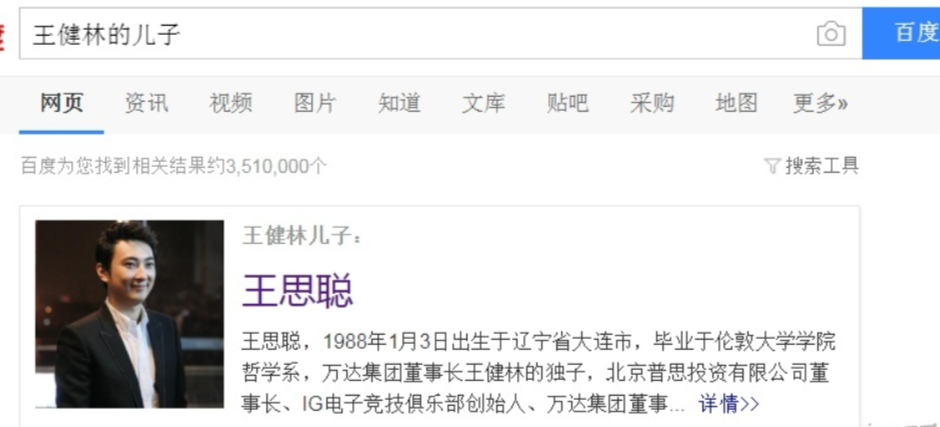
知识图谱
- 信息是指外部的客观事实。举例:这里有一瓶水,它现在是7°。
- 知识是对外部客观规律的归纳和总结。举例:水在零度的时候会结冰。
“客观规律的归纳和总结” 似乎有些难以实现。Quora 上有另一种经典的解读,区分 “信息” 和 “知识” 。
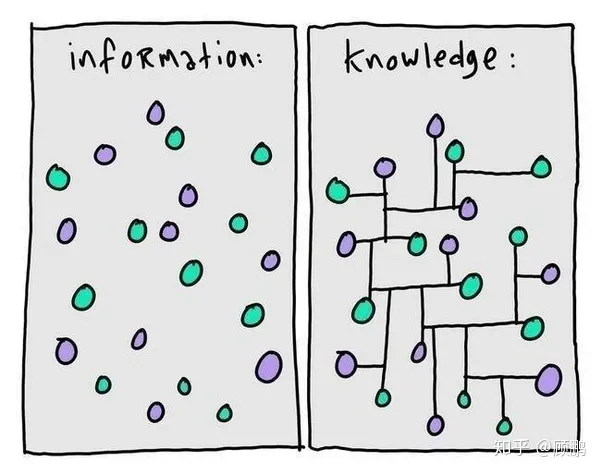
定义
知识图谱,本质上,是一种揭示实体之间关系的语义网络,是一种基于图的数据结构。
是一种结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。它的基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构 。
语义网络(Semantic Network)是上个世纪五六十年代所提出的一种知识表示形式。如图:猫是一种哺乳动物;脊椎是哺乳动物的一部分。然而,语义网络由于缺少标准,其比较难应用于实践。
基础概念:
通俗定义:知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,因此知识图谱提供了从“关系”的角度去分析问题的能力。
- 由节点(Point)和边(Edge)组成的网状的知识结构,也就是数据结构中的图(Graph)。
- 每个节点表示现实世界中存在的实体Entity,每条边为实体与实体之间的关系
- 每个节点代表的实体还存在着一些属性,比如“梅西”这个节点,可以把生日、国籍、球队等一些基本信息作为属性。
- 知识图谱由一条条知识组成,每条知识是一个基本组成单位,表示为一个三元组:(实体,关系,实体)或者(实体,属性,属性值)
- 可以用RDF形式化地表示这种三元关系,但RDF的缺点在于表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性。RDFS和OWL这两种技术解决了RDF表达能力有限的缺点。具体不展开了。
实体指的可以是现实世界中的事物,比如人、地名、公司、电话、动物等;关系则用来表达不同实体之间的某种联系。
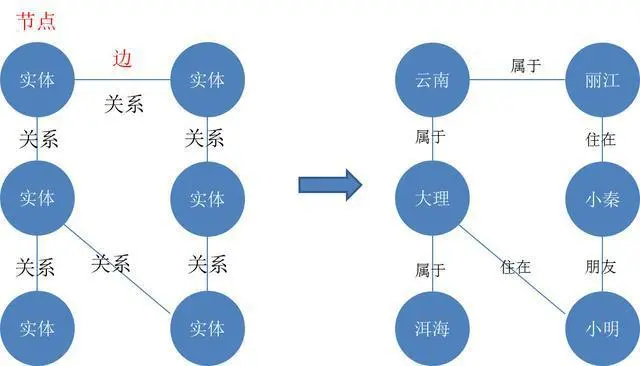
由上图,可以看到实体有地名和人;大理属于云南、小明住在大理、小明和小秦是朋友,这些都是实体与实体之间的关系。
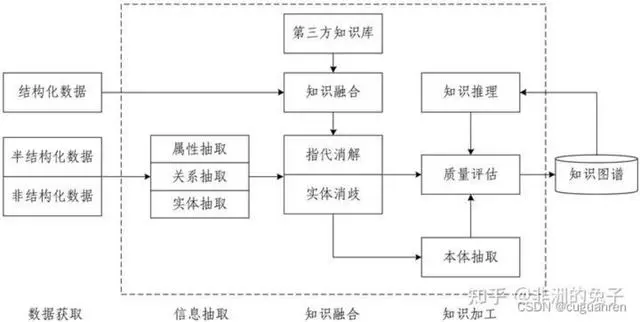
知识图谱构建的关键技术
知识图谱构建的过程中,最主要的一个步骤就是把数据从不同的数据源中抽取出来,然后按一定的规则加入到知识图谱中,这个过程我们称为知识抽取。
数据源的分为两种:
- 结构化的数据:结构化的数据是比较好处理的,难点在于处理非结构化的数据
- 非结构化的数据:处理非结构化数据通常需要使用自然语言处理技术:实体命名识别、关系抽取、实体统一、指代消解等
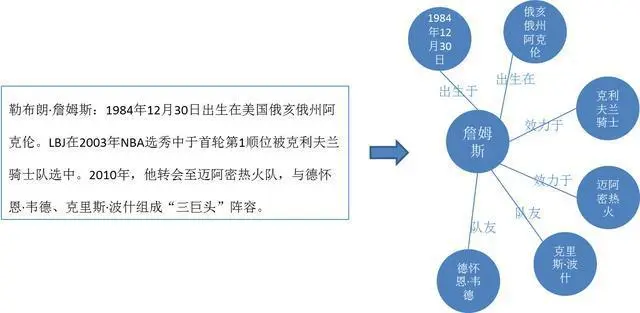
上图左边的文案就是一个非结构化的文本数据,需要经过一系列的技术处理,才能转化为右边的知识图谱。
具体是怎么实现的呢,接下来一一讨论。
知识图谱的构建
实体命名识别
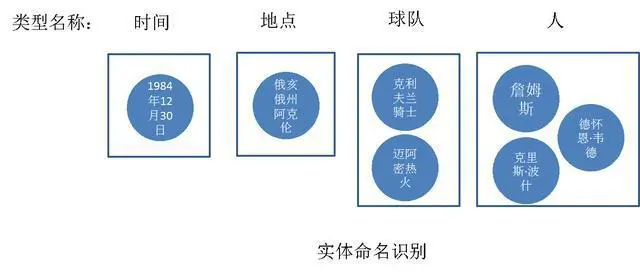
提取文本中的实体,并对每个实体进行分类或打标签,比如把文中“1984年12月30日”记为“时间”类型;“克利夫兰骑士”和“迈阿密热火”记为“球队”类型,这个过程就是实体命名。
知识抽取
知识抽取主要是面向开放的链接数据,通过自动化的技术抽取出可用的知识单元,知识单元主要包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。知识抽取有三个主要工作:
实体抽取:在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步;
关系抽取:目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则
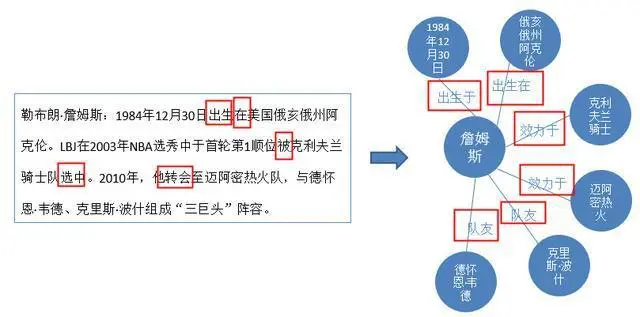
关系抽取是把实体之间的关系抽取出来的一项技术,其中主要是根据文本中的一些关键词,如“出生”、“在”、“转会”等,我们就可以判断詹姆斯与地点俄亥俄州、与迈阿密热火等实体之间的关系。属性抽取:属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。
实体统一

在文本中可能同一个实体会有不同的写法,比如说“LBJ”就是詹姆斯的缩写,因此“勒布朗詹姆斯”和“LBJ”指的就是同一个实体,实体统一就是处理这样问题的一项技术。
指代消解

指代消解跟实体统一类似,都是处理同一个实体的问题。比如说文本中的“他”其实指的就是“勒布朗詹姆斯”。所以指代消解要做的事情就是,找出这些代词,都指的是哪个实体。
指代消解和实体统一是知识抽取中比较难的环节。
知识图谱的存储
知识图谱主要有两种存储方式:
- RDF:RDF一个重要的设计原则是数据的易发布以及共享,另外,RDF以三元组的方式来存储数据而且不包含属性信息。
- 图数据库:图数据库主要把重点放在了高效的图查询和搜索上,一般以属性图为基本的表示形式,所以实体和关系可以包含属性。
RDF和图数据库的主要特点区别
RDF
- 存储三元组
- 标准的推理引擎
- W3C标准
- 易于发布数据
- 多数为学术界场景
图数据库
- 关系和节点可以带属性
- 没有标准的推荐引擎
- 图的遍历效率高
- 事务管理
- 基本为工业界场景
知识图谱能干什么
通用知识图谱:不太涉及行业知识及专业内容,一般是解决科普类、常识类等问题。主要应用于面向互联网的搜索、推荐、问答等业务场景。比如,搜索李小龙有几部电影,战狼2的导演是谁等。
行业知识图谱:针对某个垂直行业或细分领域的深入研究而定制的版本,主要是解决当前行业或细分领域的专业问题。一些应用如下:
- 企业服务:比如企业最终控股人查询
- 生活服务领域:比如美团搜索“10人聚餐,带宝宝,安静一点的餐厅”,就需要找到“有大桌”“有包间”、“有儿童椅”等标签。比如菜品构建知识体系。
- 导航POI知识图谱:支持用户点线面导航搜索需求,支持点线面的方位、距离、包含关系等:万达广场附近的充电桩在哪,广州塔那一片有商场吗?国贸楼里有7-11吗?
反欺诈
假设银行要借钱给一个人,那要怎么判断这个人是真实用户还是欺诈的呢?
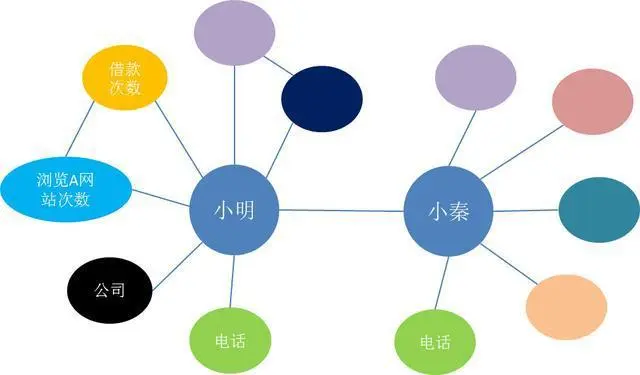
我们需要以人为核心,展开一系列的数据构建,比如说用户的基本信息、借款记录、工作信息、消费记录、行为记录、网站浏览记录等等。把这些信息整合到知识图谱中。从而整体进行预测和评分,用户欺诈行为的概率有多大。当然这个预测是需要通过机器学习,得到一个合理的模型,模型中可能会包括消费记录的权重、网站浏览记录的权重等等信息。
不一致性验证
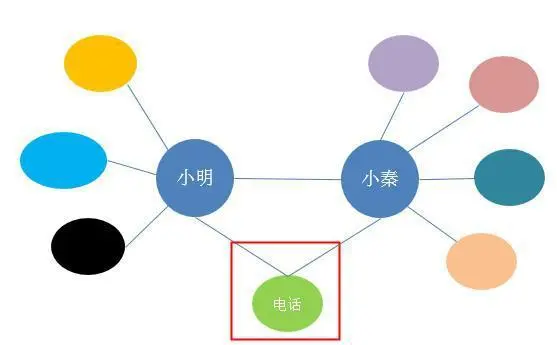
比如说不同的两个借款人,却填写了同一个电话号码,那说明这两个人中至少有一个是可疑的了,这时就需要重点关注了。
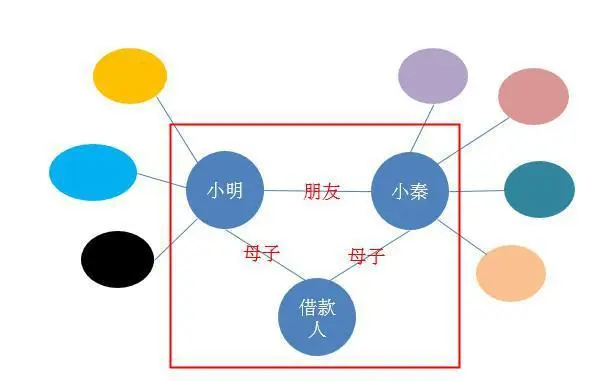
更复杂点的,可能需要知识图谱通过一些关系去推理了。比如说“借款人”跟小明和小秦都是母子关系,按推理的话小明跟小秦应该是兄弟关系,而在知识图谱上显示的是朋友关系,就有可能有异常了,因此也需要重点关注。
客户失联管理
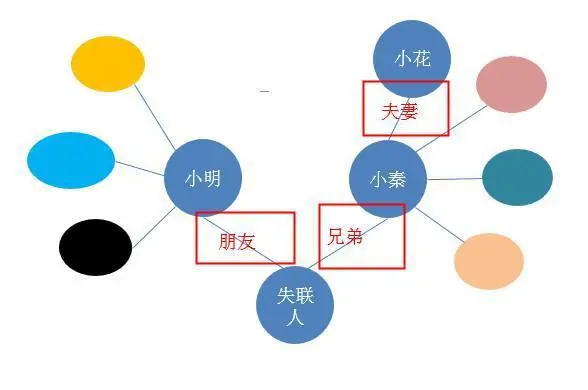
如果借款人失联了,通过知识图谱,是不是可以联系他的朋友,或兄弟,甚至是兄弟的妻子,去追踪失联人。
因此在失联的情况下,知识图谱可以挖掘更多失联人的联系人,从而提高催收效率。
知识推理
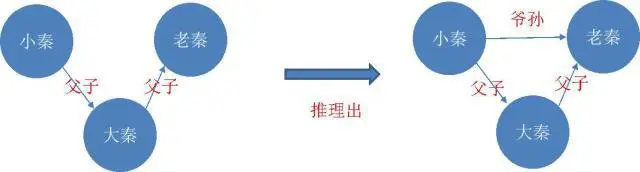
如上左图(注意这里的箭头方向),小秦是大秦的儿子,大秦是老秦的儿子,从这这样的关系,我们就可以推理出,小秦是老秦的孙子,这样就能使知识图谱更加完善了。
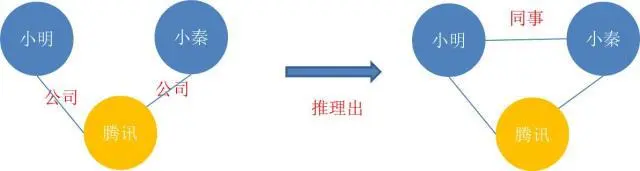
如上左图,小明在腾讯上班,小秦也在腾讯上班,从这样的关系,我们可以推理出,小明和小秦是同事关系。
推理能力其实就是机器模仿人的一种重要的能力,可以从已有的知识中发现一些隐藏的知识。当然这样的能力离不开深度学习,而随着深度学习的不断成熟,我相信知识图谱的能力也会越来越强大。
在此就介绍完了知识图谱的一些简单知识,在写这篇文章的同时,也参考了很多业界优秀大佬的文章,感谢各位大佬的无私分享。
常见图数据库
- Neo4j:是一个流行的图形数据库,它是开源的,Neo4j基于Java实现,兼容ACID特性,也支持其他编程语言,如Ruby和Python。
- Amazon Neptune:全托管的图数据库,支持多种图数据模型和查询语言。是一种快速、可靠、完全管理的图形数据库服务,可以轻松构建和运行与高度连接的数据集一起工作的应用程序
- JanusGraph:分布式图数据库,支持多种后端存储和多种查询语言。其本身专注于紧凑图序列化、丰富图数据建模、高效的查询执行
- OrientDB:多模式的NoSQL数据库,支持面向文档和面向图的数据模型和查询语言。兼具文档数据库的灵活性和图形数据库管理链接能力的可深层次扩展的文档-图形数据库管理系统。可选无模式、全模式或混合模式下。支持许多特性,诸如ACID事务、快速索引,原生和SQL查询功能。可以JSON格式导入、导出文档。若不执行昂贵的JOIN操作的话,如同关系数据库可在几毫秒内可检索数以百记的链接文档图。
- ArangoDB:是一个基于W3c标准的为资源描述框架构建的图形数据库。它为处理链接数据和Web语义而设计,支持SPARQL、RDFS++和Prolog。多模式的NoSQL数据库,支持面向文档、键值和图的数据模型和查询语言。
- GraphDB:是德国sones公司在.NET基础上构建的。Sones公司于2007年成立,近年来陆续进行了几轮融资。GraphDB托管在Windows Azure平台上。
知识图谱(Knowledge Graph)根本概念的更多相关文章
- 哈工大知识图谱(Knowledge Graph)课程概述
一.什么是知识图谱 知识(Knowledge)可以理解为 精炼的数据,知识图谱(Knowledge Graph)即是对知识的图形化表示,本质上是一种大规模语义网络 (semantic network) ...
- 学习笔记之知识图谱 (Knowledge Graph)
Knowledge Graph - Wikipedia https://en.wikipedia.org/wiki/Knowledge_Graph The Knowledge Graph is a k ...
- 百度大脑UNIT3.0详解之知识图谱与对话
如今,越来越多的企业想要在电商客服.法律顾问等领域做一套包含行业知识的智能对话系统,而行业或领域知识的积累.构建.抽取等工作对于企业来说是个不小的难题,百度大脑UNIT3.0推出「我的知识」版块专门为 ...
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(知识图谱)
知识图谱(Knowledge Graph,KG)可以理解成一个知识库,用来存储实体与实体之间的关系.知识图谱可以为机器学习算法提供更多的信息,帮助模型更好地完成任务. 在推荐算法中融入电影的知识图谱, ...
- TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion 增量时序知识图谱补全论文解读
论文网址:https://dl.acm.org/doi/10.1145/3404835.3462961 论文提出一种用增量学习思想做时序知识图谱补全(Temporal Knowledge Graph ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- 使用图数据库 Nebula Graph 数据导入快速体验知识图谱 OwnThink
前言 本文由 Nebula Graph 实习生@王杰贡献. 最近 @Yener 开源了史上最大规模的中文知识图谱--OwnThink(链接:https://github.com/ownthink/Kn ...
- 使用图数据库 Nebula Graph 数据导入快速体验知识图谱
本文由 Nebula Graph 实习生@王杰贡献. 最近 @Yener 开源了史上最大规模的中文知识图谱——OwnThink(链接:https://github.com/ownthink/Knowl ...
- Semantic Parsing(语义分析) Knowledge base(知识图谱) 对用户的问题进行语义理解 信息检索方法
简单说一下所谓Knowledge base(知识图谱)有两条路走,一条是对用户的问题进行语义理解,一般用Semantic Parsing(语义分析),语义分析有很多种,比如有用CCG.DCS,也有用机 ...
随机推荐
- 2022-07-09:总长度为n的数组中,所有长度为k的子序列里,有多少子序列的和为偶数?
2022-07-09:总长度为n的数组中,所有长度为k的子序列里,有多少子序列的和为偶数? 答案2022-07-09: 方法一:递归,要i还是不要i. 方法二:动态规划.需要两张dp表. 代码用rus ...
- vue全家桶进阶之路19:webpack资源打包工具
Vue.js 是一个前端开发框架,它可以帮助我们快速构建单页应用和复杂的交互界面.而 Webpack 则是一个前端资源打包工具,它可以将多个 JavaScript.CSS.HTML.图片等资源打包成一 ...
- Django-Virtualenv虚拟环境安装、新建,激活和手动指定Python解释器、虚拟环境安装Django、创建Django项目、运行Django项目
一.安装虚拟环境: 命令:pip3 install virtualenv 二.安装管理工具: 命令:pip3 install virtualenvwrapper 三.新建: 命令:python -m ...
- 数据库优化案例—某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
- Shiro 授权绕过 (CVE-2022-32532)
Shiro 授权绕过 (CVE-2022-32532) 一.产品简介 Apache Shiro是一个强大且易用的Java安全框架,执行身份验证.授权.密码和会话管理. 1.9.1 之前的 Apache ...
- 客户线上反馈:从信息搜集到疑难 bug 排查全流程经验分享
写在前面:本文是我在前端团队的第三次分享,应该很少会有开发者写客户反馈处理流程以及 bug 排查的心得技巧,全文比较长,写了一个多星期大概1W多字(也是我曾经2年工作的总结),如果你有耐心阅读,我相信 ...
- 云上使用 Stable Diffusion ,模型数据如何共享和存储
随着人工智能技术的爆发,内容生成式人工智能(AIGC)成为了当下热门领域.除了 ChatGPT 之外,文本生成图像技术更令人惊艳. Stable Diffusion,是一款开源的深度学习模型.与 Mi ...
- Codeforces Round #879 (Div. 2) A-E
比赛链接 A 代码 #include <bits/stdc++.h> using namespace std; using ll = long long; bool solve() { i ...
- PostgreSQL 12 文档: 部分 V. 服务器编程
部分 V. 服务器编程 这部分关于使用用户定义的函数.数据类型.触发器等扩展服务器功能.这些是高级主题,读者应该在理解了有关PostgreSQL的所有其他用户文档之后才阅读这些主题.这一部分的后面一些 ...
- 【Azure Event Hub】自定义告警(Alert Rule)用来提示Event Hub的消息incoming(生产)与outgoing(消费)的异常情况
问题描述 在使用Azure Service Bus的时候,我们可以根据Queue中目前存在的消息数来判断当前消息是否有积压的情况. 但是,在Event Hub中,因为所有消息都会被存留到预先设定的保留 ...