ETL工具-nifi干货系列 第十六讲 nifi Process Group实战教程,一文轻松搞定
1、目前nifi系列已经更新了10多篇教程了,跟着教程走的同学应该已经对nifi有了初步的解,但是我相信同学们应该有一个疑问:nifi设计好的数据流列表在哪里?如何同时运行多个数据流?如启停单个数据流?
带着这些疑问,今天的主角nifi Process Group正式登场,先给大家看个图。
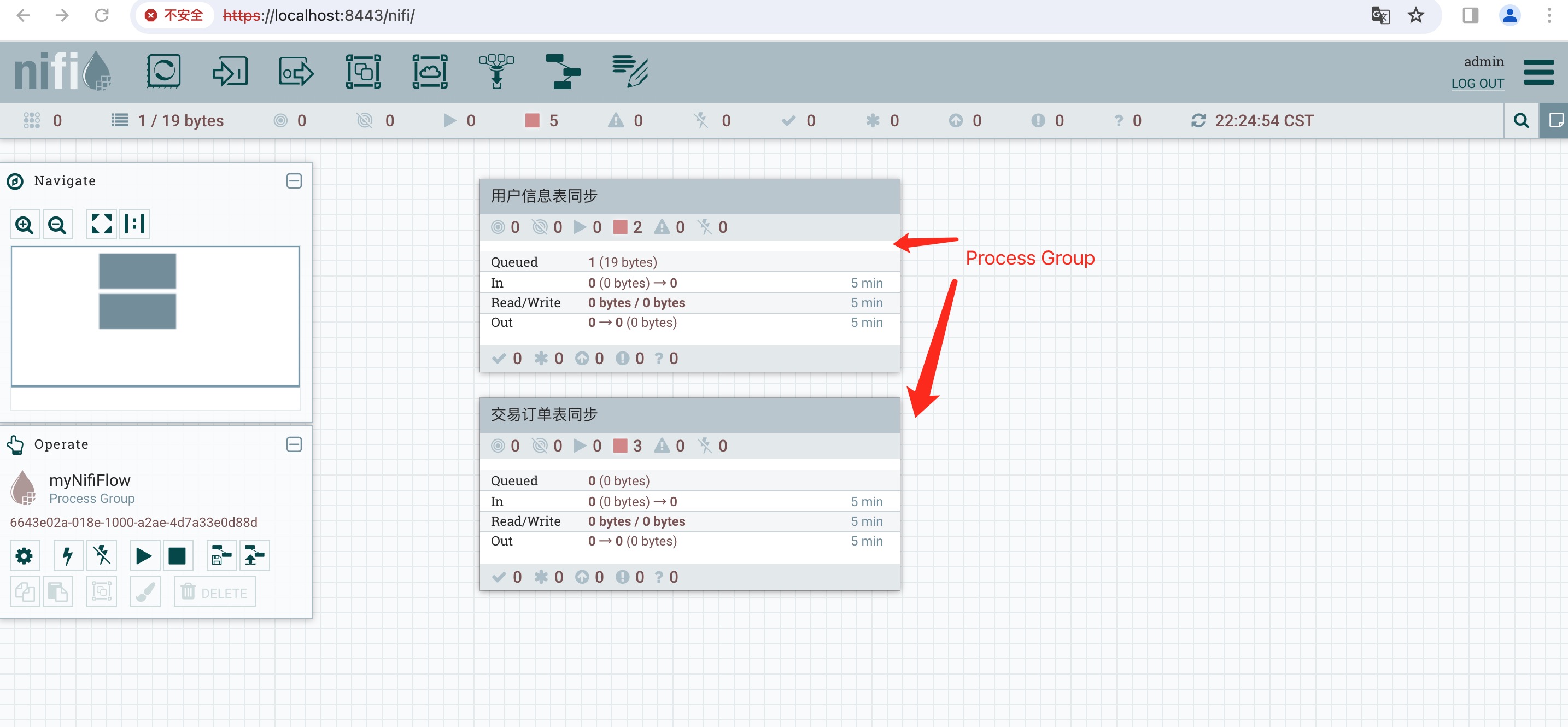
2、Process Group(处理组)
1)当数据流变得复杂时,以更高级、更抽象的层次来思考数据流往往是有益的。也就是说通过处理组将一个或多个流程封装起来,屏蔽其复杂性。
2)NiFi允许将多个组件,如处理器(Processors),组合成一个处理组(Process Group)。处理组中可以是一些列的处理器,也可以是处理组。
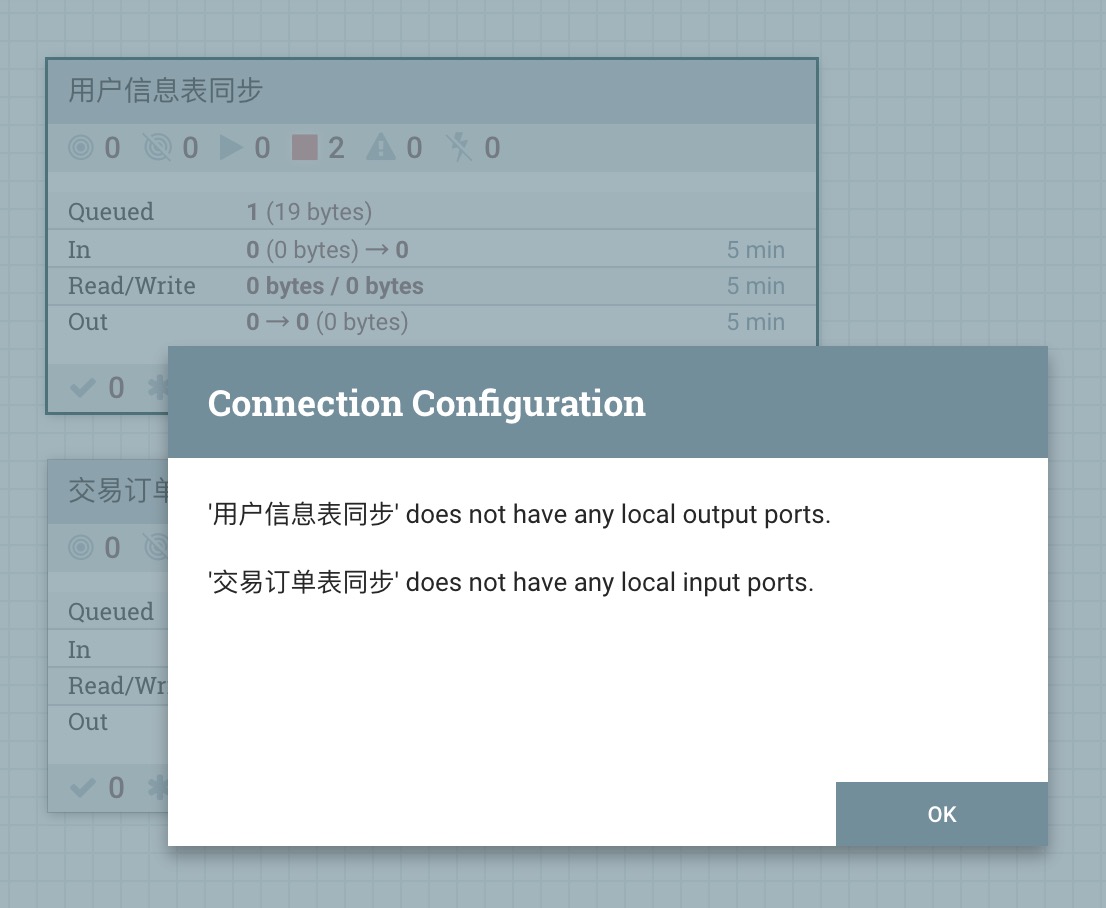
3)NiFi用户界面使得数据流管理者(DFM)能够轻松将多个处理组连接成一个逻辑数据流。用户能够将多个处理组连成一个逻辑数据流。但是处理组之间进行连接需要用到Input Port和Out Port,后续会进行讲解。
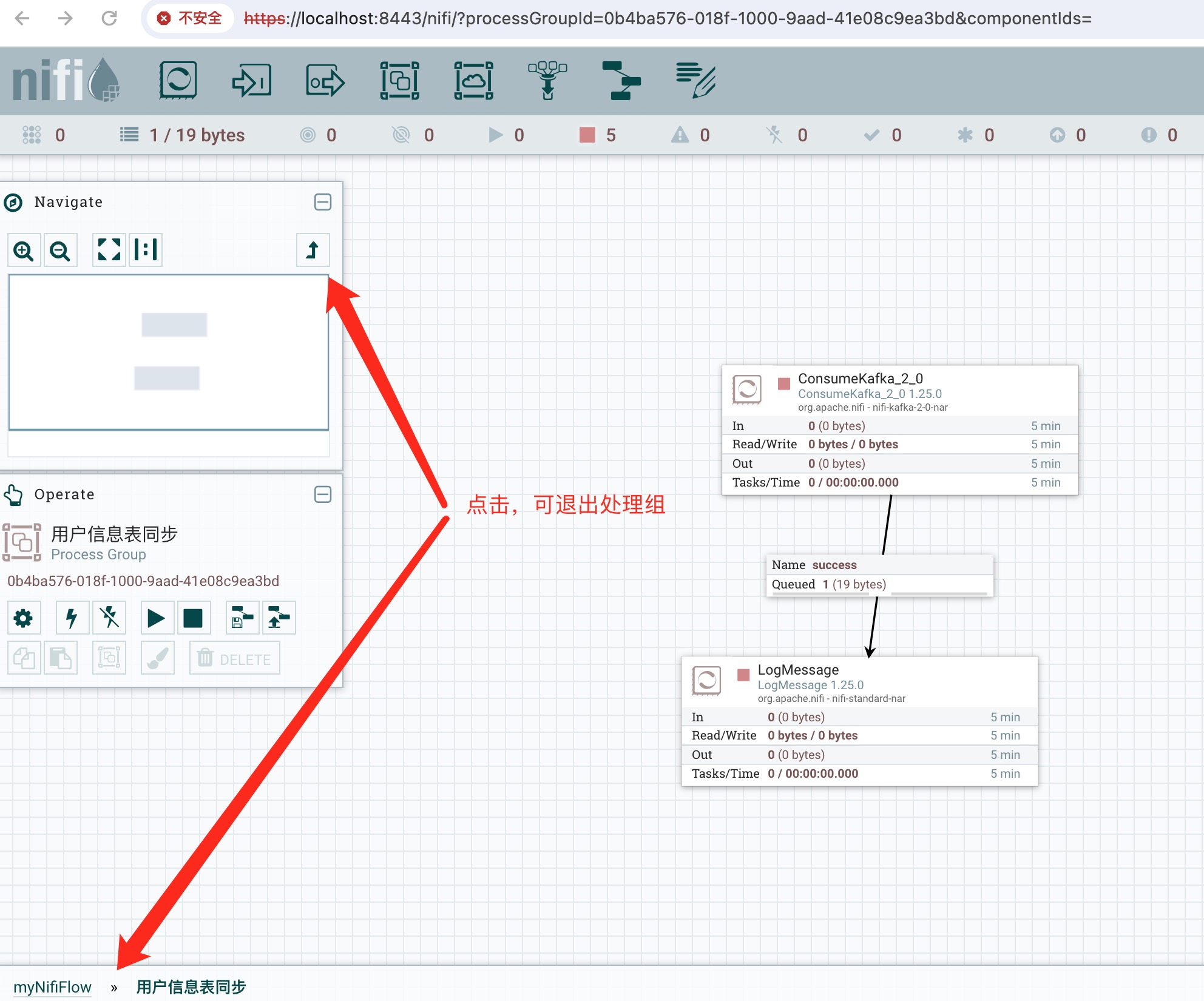
4)同时也允许DFM进入处理组以查看和操作处理组内的组件。操作人员可以很方便的进入(双击处理组)和退出处理组(点击面包屑导航)。
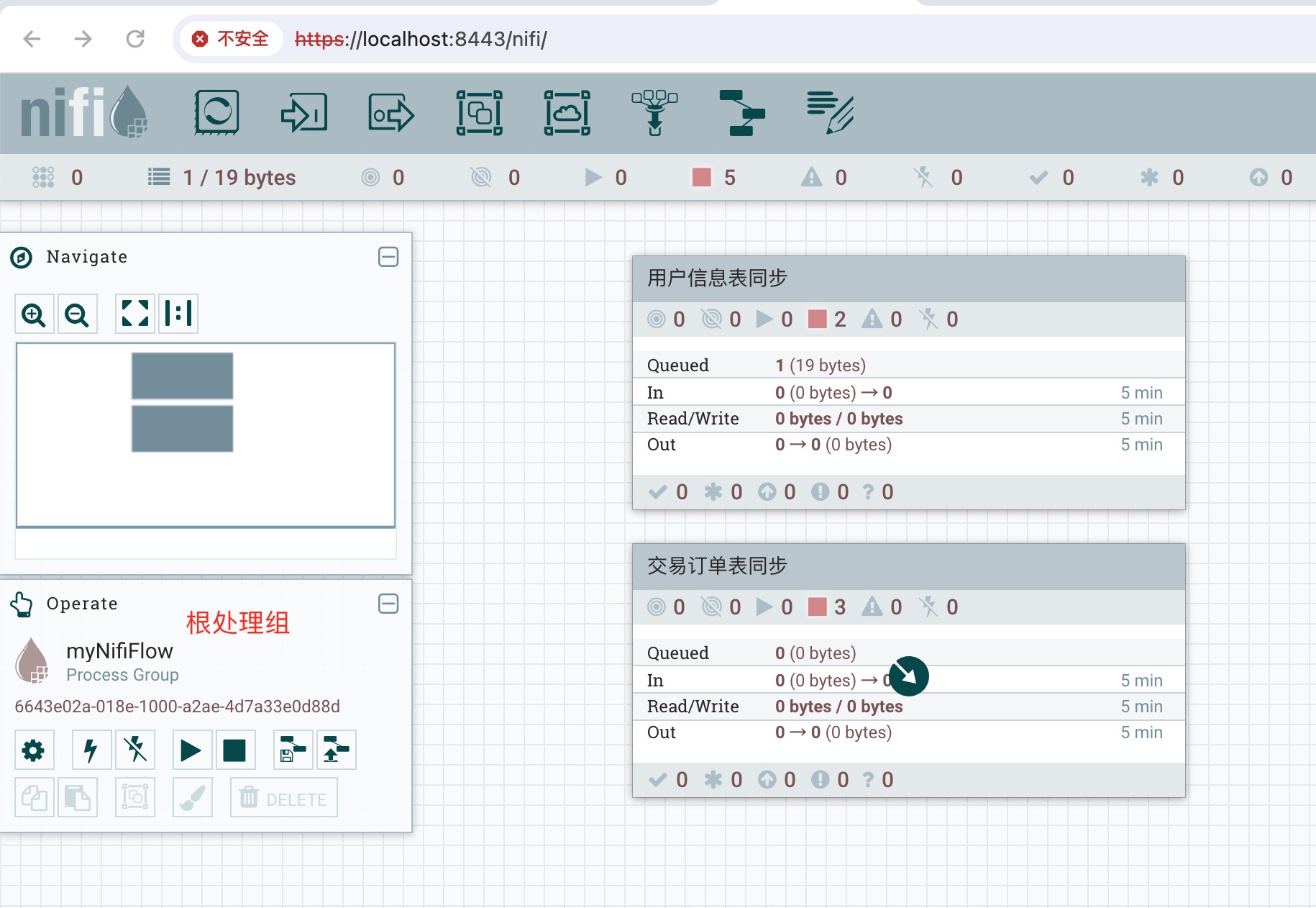
3、处理组配置,空白画布默认为根处理组,我把根处理组的名字修改为myNiflFlow。myNiflFlow处理组包含处理组【用户信息同步】和【交易订单同步】两个处理组。
当然这里的分组不一定合适,有可能是按照系统分的,如myNiflFlow处理组包含处理组【申请系统】、【审核系统】、【信贷系统等】,自己可以根据业务场景进行分组。
1)鼠标点击空白处,点击️运行按钮可以启动多个处理组流程。
2)鼠标点击空白处,点击⏸️暂停按钮可以停止多个处理组流程。
3)选中某个处理组,可以单独启动或者暂停该处理组,而不影响其他处理组。
4)启用,禁用等按钮操作也可以进行类似批量或者单个处理组操作。
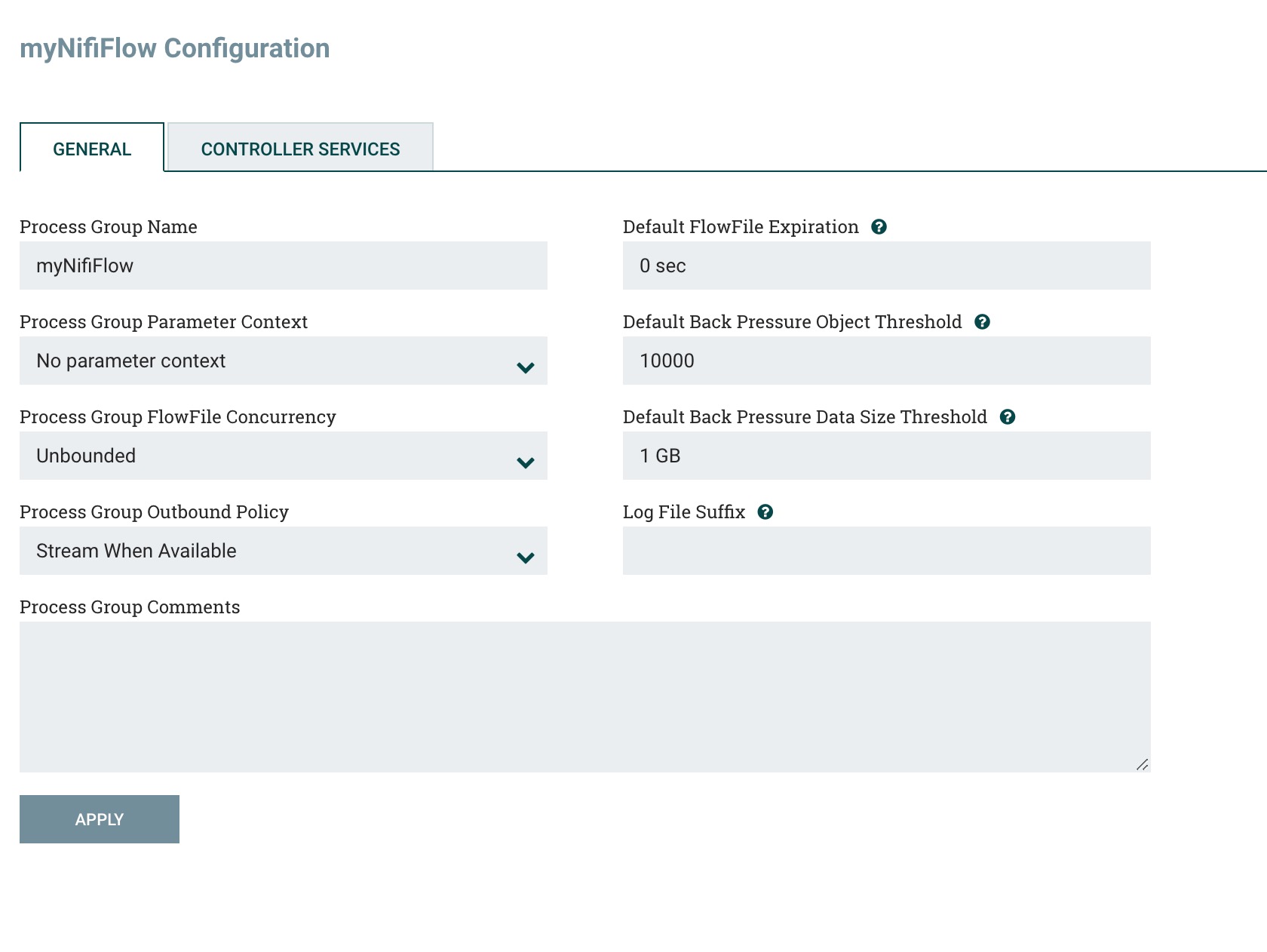
5)Process Group Name:自定义处理组名称
6)Process Group Parameter Context:它用于为流程中的组件提供参数。从这个下拉菜单中,用户可以选择应该绑定到此流程组的参数上下文,并可选择创建一个新的参数上下文以绑定到该流程组。后续参数和参数上下文设置单独讲解,这里先做了解。
7) Process Group FlowFile Concurrency:
FlowFile Concurrency 用于控制数据如何进入流程组。有三种可用选项:
1. 无限制(默认值)
2. 单个节点每次一个流文件
3. 单个节点每次一个批次
当FlowFile并发性设置为“无限制”时,流程组中的输入端口将尽可能快地摄取数据,前提是背压不会阻止它们这样做。
当FlowFile并发性配置为“单个节点每次一个流文件”时,输入端口将只允许一个流文件通过。一旦该流文件进入流程组,直到所有流文件离开流程组(通过从系统中移除/自动终止,或通过输出端口退出)之前,将不会再带入任何其他流文件。这通常会导致性能较慢,因为它减少了NiFi用于处理数据的并行性。然而,用户可能希望使用这种方法的原因有几个。一个常见的用例是每个传入的FlowFile包含对其他几个数据项的引用,比如目录中的文件列表。用户可能希望在允许任何其他数据进入流程组之前处理整个列表。
当FlowFile并发性配置为“单个节点每次一个批次”时,输入端口的行为方式与“单个节点每次一个流文件”模式类似,但是当摄取一个流文件时,输入端口将继续摄取所有数据,直到所有馈送输入端口的队列已被清空。在那时,它们将不会将任何更多的数据带入流程组,直到所有数据已完成处理并离开流程组。
8)Process Group Outbound Policy:出站策略控制了数据从流程组中流出的方式。有两个可用选项:
1. 当可用时流式传输(默认值)
2. 批量输出
当出站策略配置为“当可用时流式传输”时,到达输出端口的数据将立即从流程组中转移出去,假设没有施加任何背压。
当出站策略配置为“批量输出”时,输出端口将不会将数据从流程组中传输出去,直到所有数据都在输出端口排队(即,在所有数据完成处理之前,没有数据离开流程组)。无论数据是否全部排队到同一个输出端口,还是一些数据排队到输出端口A,而另一些数据排队到输出端口B,这些条件在流文件处理完成方面都被视为相同。
将出站策略设置为“批量输出”,并结合使用“单个节点每次一个流文件”的FlowFile并发性,允许用户轻松摄取单个流文件(该流文件本身可能代表一批数据),然后等待直到该流文件的所有处理完成后再继续数据流的下一步(即流程组之外的下一个组件)。此外,在使用此模式时,从流程组传输出的每个流文件都将被赋予一系列属性,属性名称为“batch.output.<Port Name>”,每个流程组中的输出端口都有一个。该值将等于被路由到该输出端口的流文件数量。例如,考虑一个情况,其中一个单个流文件被拆分为5个流文件:两个流文件送到输出端口A,一个送到输出端口B,两个送到输出端口C,而没有流文件送到输出端口D。在这种情况下,每个流文件将具有属性 batch.output.A = 2, batch.output.B = 1, batch.output.C = 2, batch.output.D = 0。
当与“无限制”的FlowFile并发性结合使用时,“批量输出”出站策略不提供任何好处。因此,如果FlowFile并发性设置为“无限制”,则会忽略出站策略。

ETL工具-nifi干货系列 第十六讲 nifi Process Group实战教程,一文轻松搞定的更多相关文章
- 数据可视化之powerBI基础(十九)学会使用Power BI的参数,轻松搞定动态分析
https://zhuanlan.zhihu.com/p/55295072 静态的分析经常不能满足实际分析的需要,还需要引入动态分析,通过调节某个维度的增减变化来观察对分析结果的影响.在PowerBI ...
- Web 前端开发人员和设计师必读精华文章【系列二十六】
<Web 前端开发精华文章推荐>2014年第5期(总第26期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML5 ...
- 以太坊系列之十六: 使用golang与智能合约进行交互
以太坊系列之十六: 使用golang与智能合约进行交互 以太坊系列之十六: 使用golang与智能合约进行交互 此例子的目录结构 token contract 智能合约的golang wrapper ...
- 以太坊系列之十六:golang进行智能合约开发
以太坊系列之十六: 使用golang与智能合约进行交互 以太坊系列之十六: 使用golang与智能合约进行交互 此例子的目录结构 token contract 智能合约的golang wrapper ...
- OSGi 系列(十六)之 JDBC Service
OSGi 系列(十六)之 JDBC Service compendium 规范提供了 org.osgi.service.jdbc.DataSourceFactory 服务 1. 快速入门 1.1 环境 ...
- Spring Boot干货系列:(六)静态资源和拦截器处理
Spring Boot干货系列:(六)静态资源和拦截器处理 原创 2017-04-05 嘟嘟MD 嘟爷java超神学堂 前言 本章我们来介绍下SpringBoot对静态资源的支持以及很重要的一个类We ...
- 【微服务】之二:从零开始,轻松搞定SpringCloud微服务系列--注册中心(一)
微服务体系,有效解决项目庞大.互相依赖的问题.目前SpringCloud体系有强大的一整套针对微服务的解决方案.本文中,重点对微服务体系中的服务发现注册中心进行详细说明.本篇中的注册中心,采用Netf ...
- 从零开始,轻松搞定SpringCloud微服务系列
本系列博文目录 [微服务]之一:从零开始,轻松搞定SpringCloud微服务系列–开山篇(spring boot 小demo) [微服务]之二:从零开始,轻松搞定SpringCloud微服务系列–注 ...
- 轻松搞定RabbitMQ(六)——主题
转自 http://blog.csdn.net/xiaoxian8023/article/details/48806871 翻译地址:http://www.rabbitmq.com/tutorials ...
- 分分钟轻松搞定IBM系列 RAID5搭建
分分钟轻松搞定IBM系列 RAID5搭建 按照 以下图片步骤一步步可轻松完成IBM服务器RAID1.5.10等的搭建. 此例是以RAID5为例,RAID1和10可举一反三.
随机推荐
- 力扣1132(MySQL)-报告的记录Ⅱ(中等)
题目: 编写一段 SQL 来查找:在被报告为垃圾广告的帖子中,被移除的帖子的每日平均占比,四舍五入到小数点后 2 位. Actions 表: Removals 表: Result 表: 2019-07 ...
- 成本节省 50%,9人团队使用函数计算开发 wolai 在线文档应用
简介: 通过使用函数计算,wolai 的前端工程师们就可以把从前到后的一整套开发流程负责起来,我们的研发迭代速度非常快. 作者| 马锐拉(wolai.com 创始人) 我们的日常工作场景几乎离 ...
- 大数据时代下,App数据隐私安全你真的了解么?
简介:你是否有过这样的经历:你和朋友聊天表达你近期想要购买某件商品,第二天当你打开某购物软件时,平台向你推送的商品正是你想要购买的:或者,你是否接到过陌生来电,他们准确的报出了你的名字和年龄.... ...
- HBase读链路分析
简介:HBase的存储引擎是基于LSM-Like树实现的,更新操作不会直接去更新数据,而是使用各种type字段(put,delete)来标记一个新的多版本数据,采用定期compaction的形式来归 ...
- 函数计算 GB 镜像秒级启动:下一代软硬件架构协同优化揭秘
简介:本文将介绍借助函数计算下一代 IaaS 底座神龙裸金属和安全容器,进一步降低绝对延迟且能够大幅降低冷启动频率. 作者:修踪 背景 函数计算在 2020 年 8 月创新地提供了容器镜像的函数部署 ...
- [GPT] 序列模型分类及其模型方案选择
序列模型可以分为两大类:线性序列模型和非线性序列模型. 线性序列模型:这类模型基于线性关系对时间序列进行建模和预测.常见的线性序列模型包括自回归模型(AR).移动平均模型(MA)和自回归移动平均模 ...
- 使用 SizeBench 分析 Exe 文件体积
本文将介绍微软开源免费的 SizeBench 工具,使用 SizeBench 工具可以用来分析 Exe 二进制文件的体积,分析 Exe 文件大小里面有哪些是可以优化的 下载安装方式: 请前往应用商店安 ...
- dotnet 在析构函数调用 ThreadLocal 也许会抛出对方已释放
我在不自量力做一个数组池,就是为了减少使用 System.Buffers.dll 程序集,然而在数组池里面,所用的 ThreadLocal 类型,在我对象析构函数进行归还数组时,抛出了无法访问已释放对 ...
- dotnet 在 UOS 国产系统上使用 Xamarin Forms 创建 xaml 界面的 GTK 应用
在前面几篇博客告诉大家如何部署 GTK 应用,此时的应用是特别弱的,大概只是到拖控件级.尽管和 WinForms 一样也能写出特别强大的应用,但是为了提升一点开发效率,咱开始使用 xaml 神器写界面 ...
- 十、Doris操作参考手册
1.SQL参考 1.1 用户账户管理 1.2 集群管理 1.3 DDL 1.4 DML 2.函数参考 2.1 日期函数 2.2 字符串函数 2.3 聚合函数 2.4 Cast转换函数 ...