coco2017 Dataset EDA
Github仓库:gy-7/coco_EDA (github.com)
对coco数据集的分析,近期忙着写论文,空余时间很少能写博文了。
EDA的代码放在结尾了,Github仓库里也有。仓库里还有其他的一些EDA分析,不定时更新。
训练集所有类别的数量分布情况:
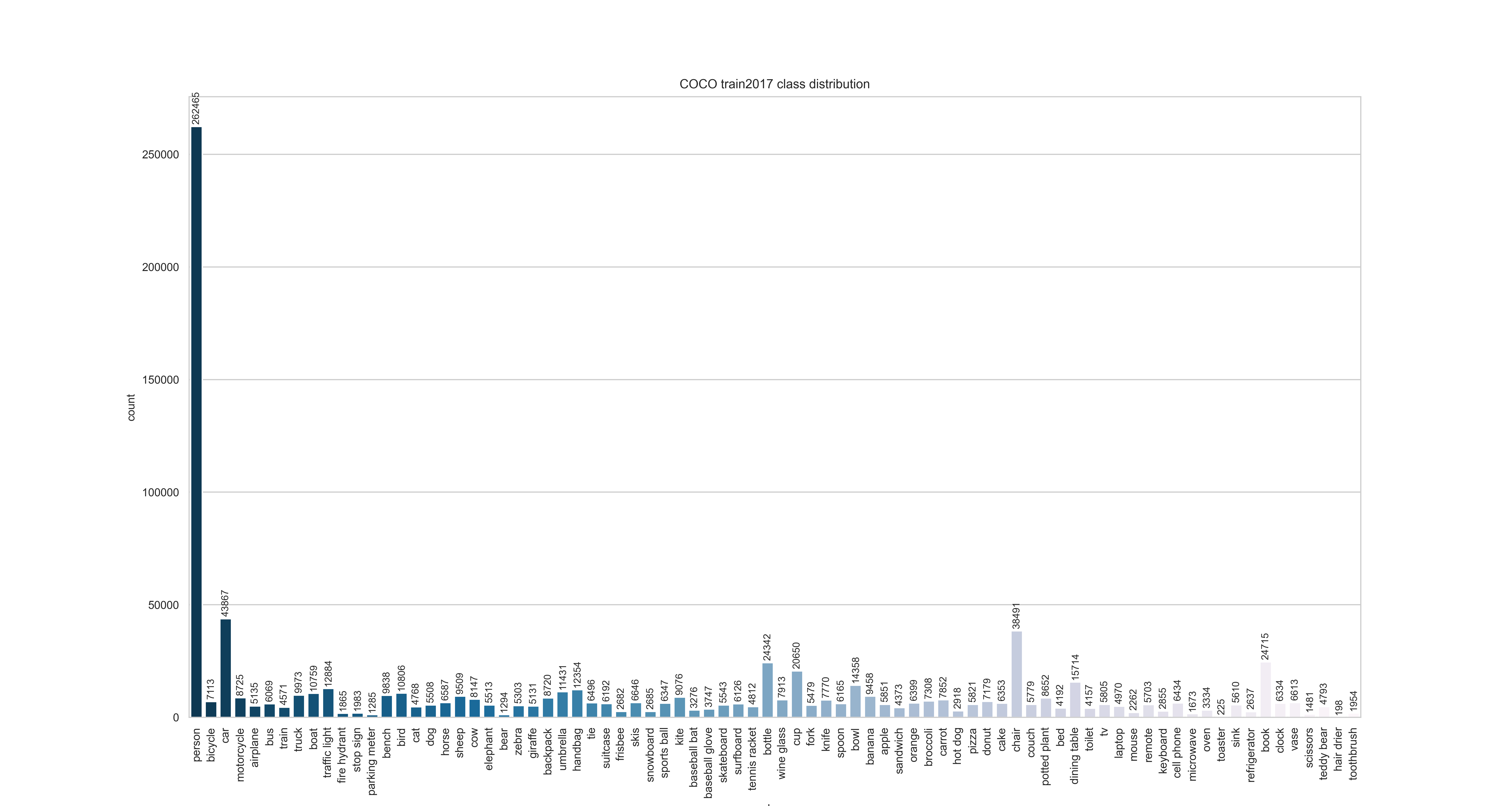
训练集所有类别的尺寸分布情况:

验证集所有类别的数量分布情况:
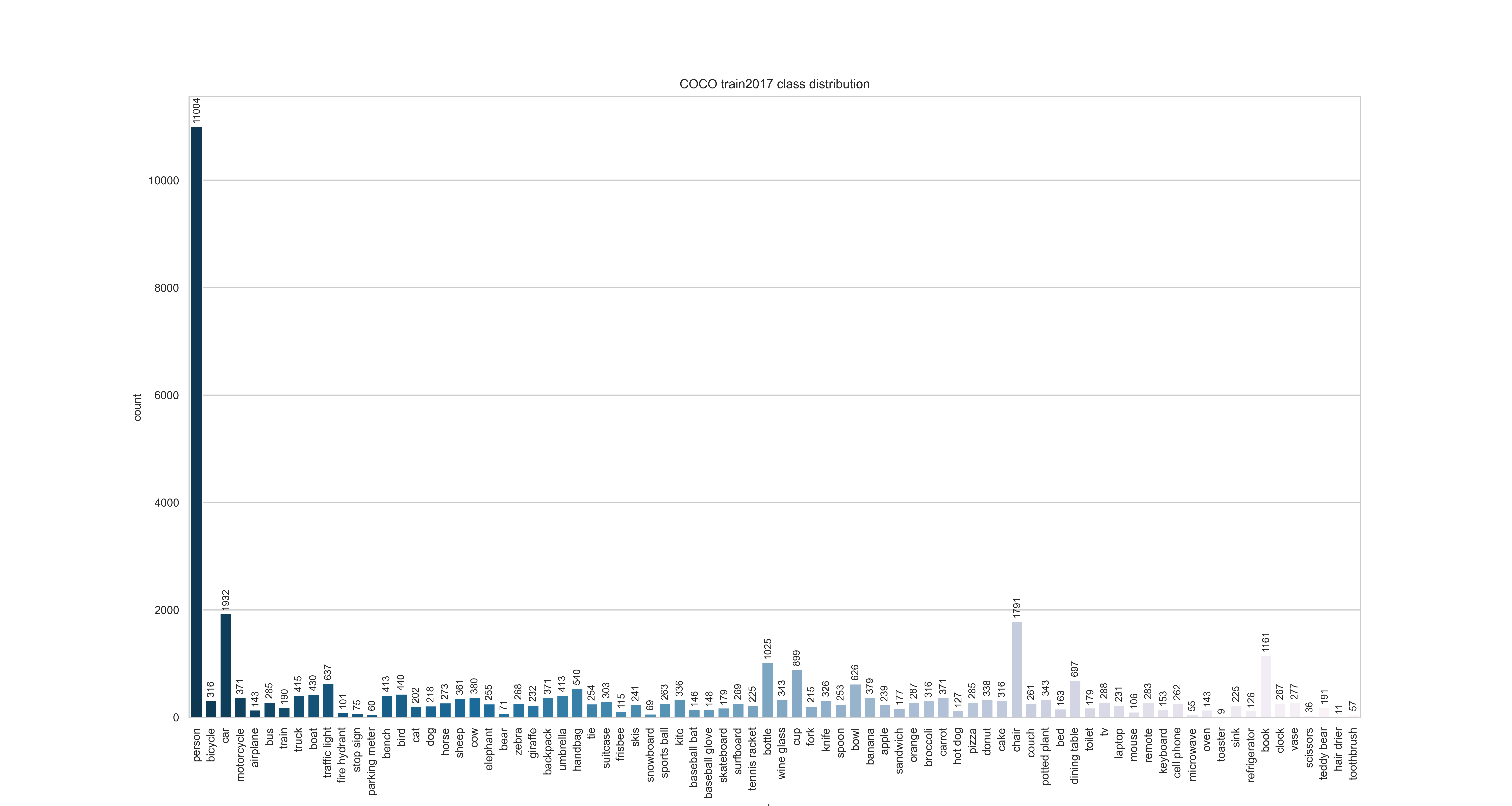
验证集所有类别的尺寸分布情况:

EDA代码:
import os
import seaborn as sns
import pycocotools.coco
import matplotlib.pyplot as plt
root_dir = os.getcwd()
train_ann_fp = os.path.join(root_dir, 'annotations', 'instances_train2017.json')
val_ann_fp = os.path.join(root_dir, 'annotations', 'instances_val2017.json')
class COCO_EDA:
def __init__(self, json_file, type='train'):
self.COCO_SMALL_SCALE = 32
self.COCO_MEDIUM_SCALE = 96
self.json_file = json_file
coco = pycocotools.coco.COCO(json_file)
self.type = type
self.imgs = coco.dataset['images']
self.anns = coco.dataset['annotations']
self.cats = coco.dataset['categories']
self.img_ids = coco.getImgIds()
self.ann_ids = coco.getAnnIds()
self.cat_ids = coco.getCatIds()
self.cat2imgs = coco.catToImgs
self.img2anns = coco.imgToAnns
self.imgs_num = len(self.imgs)
self.objs_num = len(self.anns)
# data to be collected
self.small_objs_num = 0
self.medium_objss_num = 0
self.large_objss_num = 0
self.small_objs = []
self.medium_objs = []
self.large_objs = []
self.cat2objs = {}
self.small_cat2objs = {} # small objects classes distribution
self.medium_cat2objs = {} # medium objects classes distribution
self.large_cat2objs = {} # large objects classes distribution
self.cat2objs_num = {} # objects classes distribution
self.small_cat2objs_num = {} # small objects classes distribution
self.medium_cat2objs_num = {} # medium objects classes distribution
self.large_cat2objs_num = {} # large objects classes distribution
# plot use data
self.catid2name = {} # 用于绘图中显示类别名字
self.cats_plot = [] # coco 所有尺寸目标的类别分布
self.small_cats_plot = [] # 小目标中每个类的分布情况
self.medium_cats_plot = [] # 中目标中每个类的分布情况
self.large_cats_plot = [] # 大目标中每个类的分布情况
# 每个类的小,中,大目标的数量
self.size_distribution = {}
def collect_data(coco):
# collect small, medium, large objects
for ann in coco.anns:
if ann['area'] < coco.COCO_SMALL_SCALE ** 2:
coco.small_objs_num += 1
coco.small_objs.append(ann)
elif ann['area'] < coco.COCO_MEDIUM_SCALE ** 2:
coco.medium_objs.append(ann)
coco.medium_objss_num += 1
else:
coco.large_objs.append(ann)
coco.large_objss_num += 1
for i in coco.cat_ids:
coco.cat2objs[i] = []
coco.small_cat2objs[i] = []
coco.medium_cat2objs[i] = []
coco.large_cat2objs[i] = []
coco.cat2objs_num[i] = 0
coco.small_cat2objs_num[i] = 0
coco.medium_cat2objs_num[i] = 0
coco.large_cat2objs_num[i] = 0
coco.size_distribution[i] = []
for i in coco.cats:
coco.catid2name[i['id']] = i['name']
# collect small, medium, large class distribution
for i in coco.anns:
coco.cat2objs[i['category_id']].append(i)
coco.cat2objs_num[i['category_id']] += 1
coco.cats_plot.append(coco.catid2name[i['category_id']])
if i['area'] < coco.COCO_SMALL_SCALE ** 2:
coco.small_cat2objs[i['category_id']].append(i)
coco.small_cat2objs_num[i['category_id']] += 1
coco.small_cats_plot.append(coco.catid2name[i['category_id']])
coco.size_distribution[i['category_id']].append('s')
elif i['area'] < coco.COCO_MEDIUM_SCALE ** 2:
coco.medium_cat2objs[i['category_id']].append(i)
coco.medium_cat2objs_num[i['category_id']] += 1
coco.medium_cats_plot.append(coco.catid2name[i['category_id']])
coco.size_distribution[i['category_id']].append('m')
else:
coco.large_cat2objs[i['category_id']].append(i)
coco.large_cat2objs_num[i['category_id']] += 1
coco.large_cats_plot.append(coco.catid2name[i['category_id']])
coco.size_distribution[i['category_id']].append('l')
assert len(coco.small_objs) == coco.small_objs_num == sum(coco.small_cat2objs_num.values())
assert len(coco.medium_objs) == coco.medium_objss_num == sum(coco.medium_cat2objs_num.values())
assert len(coco.large_objs) == coco.large_objss_num == sum(coco.large_cat2objs_num.values())
assert len(coco.anns) == coco.objs_num == sum(coco.cat2objs_num.values())
def plot_coco_class_distribution(plot_data, plot_order, save_fp, plot_title, plot_y_heigh,
plot_y_heigh_residual=[1800, 100]):
# 绘制coco数据集的类别分布
sns.set_style("whitegrid")
plt.figure(figsize=(15, 8)) # 图片的宽和高,单位为inch
plt.title(plot_title, fontsize=9) # 标题
plt.xlabel('class', fontsize=8) # x轴名称
plt.ylabel('counts', fontsize=8) # y轴名称
plt.xticks(rotation=90, fontsize=8) # x轴标签竖着显示
plt.yticks(fontsize=8)
for x, y in enumerate(plot_y_heigh):
if 'train' in save_fp:
plt.text(x, y + plot_y_heigh_residual[0], '%s' % y, ha='center', fontsize=7, rotation=90)
else:
plt.text(x, y + plot_y_heigh_residual[1], '%s' % y, ha='center', fontsize=7, rotation=90)
ax = sns.countplot(x=plot_data, palette="PuBu_r", order=plot_order) # 绘制直方图,palette调色板,蓝色由浅到深渐变。
# palette样式:https://blog.csdn.net/panlb1990/article/details/103851983
plt.savefig(os.path.join(save_fp), dpi=500)
plt.show()
def plot_size_distribution(plot_data, save_fp, plot_title, plot_order=['s', 'm', 'l']):
sns.set_style("whitegrid")
plt.figure(figsize=(21, 35)) # 图片的宽和高,单位为inch
plt.subplots_adjust(left=0.1, bottom=0.1, right=0.9, top=0.9, wspace=1, hspace=1.5) # 调整子图间距
for idx, size_data in enumerate(plot_data.values()):
plt.subplot(10, 8, idx + 1)
plt.xticks(rotation=0, fontsize=18) # x轴标签竖着显示
plt.yticks(fontsize=18)
plt.xlabel('size', fontsize=20) # x轴名称
plt.ylabel('count', fontsize=20) # y轴名称
plt.title(plot_title[idx], fontsize=24) # 标题
sns.countplot(x=size_data, palette="PuBu_r", order=plot_order) # 绘制直方图,palette调色板,蓝色由浅到深渐变。
plt.savefig(save_fp, dpi=500, pad_inches=0)
plt.show()
def run_plot_coco_class_distribution(coco, save_dir):
# # 绘制coco数据集的类别分布
plot_order = [i for i in coco.catid2name.values()]
plot_heigh = [i for i in coco.cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_class_distribution.png')
plot_coco_class_distribution(coco.cats_plot, plot_order, save_fp, 'COCO train2017 class distribution', plot_heigh,
plot_y_heigh_residual=[1800, 100])
plot_heigh = [i for i in coco.small_cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_small_class_distribution.png')
plot_coco_class_distribution(coco.small_cats_plot, plot_order, save_fp, 'COCO train2017 small class distribution',
plot_heigh,
plot_y_heigh_residual=[900, 50])
plot_heigh = [i for i in coco.medium_cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_medium_class_distribution.png')
plot_coco_class_distribution(coco.medium_cats_plot, plot_order, save_fp, 'COCO train2017 medium class distribution',
plot_heigh, plot_y_heigh_residual=[900, 50])
plot_heigh = [i for i in coco.large_cat2objs_num.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_large_class_distribution.png')
plot_coco_class_distribution(coco.large_cats_plot, plot_order, save_fp, 'COCO train2017 large class distribution',
plot_heigh,
plot_y_heigh_residual=[900, 50])
def run_plot_coco_size_distribution(coco, save_dir):
# 绘制coco数据集各类别的尺寸分布
plot_order = [i for i in coco.catid2name.values()]
save_fp = os.path.join(save_dir, f'coco_{coco.type}_size_distribution.png')
plot_size_distribution(coco.size_distribution, save_fp, plot_order)
if __name__ == '__main__':
print("analyze coco train dataset...")
print("-" * 50)
coco_train = COCO_EDA(train_ann_fp, type='train')
collect_data(coco_train)
print("coco train images num:", coco_train.imgs_num)
print("coco train objects num:", coco_train.objs_num)
print("coco small objects num:", coco_train.small_objs_num)
print("coco medium objects num:", coco_train.medium_objss_num)
print("coco large objects num:", coco_train.large_objss_num)
print("coco small objects percent:", coco_train.small_objs_num / coco_train.objs_num)
print("coco medium objects percent:", coco_train.medium_objss_num / coco_train.objs_num)
print("coco large objects percent:", coco_train.large_objss_num / coco_train.objs_num)
run_plot_coco_class_distribution(coco_train, ".\\EDA")
run_plot_coco_size_distribution(coco_train, ".\\EDA")
print("-" * 50)
print()
print("analyze coco val dataset...")
print("-" * 50)
coco_val = COCO_EDA(val_ann_fp, type='val')
collect_data(coco_val)
print("coco val images num:", coco_val.imgs_num)
print("coco val objects num:", coco_val.objs_num)
print("coco small objects num:", coco_val.small_objs_num)
print("coco medium objects num:", coco_val.medium_objss_num)
print("coco large objects num:", coco_val.large_objss_num)
print("coco small objects percent:", coco_val.small_objs_num / coco_val.objs_num)
print("coco medium objects percent:", coco_val.medium_objss_num / coco_val.objs_num)
print("coco large objects percent:", coco_val.large_objss_num / coco_val.objs_num)
run_plot_coco_class_distribution(coco_val, ".\\EDA")
run_plot_coco_size_distribution(coco_val, ".\\EDA")
print("-" * 50)
coco2017 Dataset EDA的更多相关文章
- 斯坦福【概率与统计】课程笔记(二):从EDA开始
探索性数据分析(Exploratory Data Analysis) 本节课程先从统计分析四步骤中的第二步:EDA开始. 课程定义了若干个术语,如果学习过机器学习的同学,应该很容易类比理解: popu ...
- 【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)
[机器学习入门与实践]数据挖掘-二手车价格交易预测(含EDA探索.特征工程.特征优化.模型融合等) note:项目链接以及码源见文末 1.赛题简介 了解赛题 赛题概况 数据概况 预测指标 分析赛题 数 ...
- HTML5 数据集属性dataset
有时候在HTML元素上绑定一些额外信息,特别是JS选取操作这些元素时特别有帮助.通常我们会使用getAttribute()和setAttribute()来读和写非标题属性的值.但为此付出的代价是文档将 ...
- C#读取Excel,或者多个excel表,返回dataset
把excel 表作为一个数据源进行读取 /// <summary> /// 读取Excel单个Sheet /// </summary> /// <param name=& ...
- DataTable DataRow DataColumn DataSet
1.DataTable 数据表(内存) 2.DataRow DataTable 的行 3.DataColumn DataTable 的列 4.DataSet 内存中的缓存
- C# DataSet装换为泛型集合
1.DataSet装换为泛型集合(注意T实体的属性其字段类型与dataset字段类型一一对应) #region DataSet装换为泛型集合 /// <summary> /// 利用反射和 ...
- 读取Simulink中Dataset类型的数据
http://files.cnblogs.com/files/pursuiting/%E5%80%92%E7%AB%8B%E6%91%86%E6%8E%A7%E5%88%B6%E7%B3%BB%E7% ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
- asp.net dataset 判断是否为空 ?
1,if(ds == null) 这是判断内存中的数据集是否为空,说明DATASET为空,行和列都不存在!! 2,if(ds.Tables.Count == 0) 这应该是在内存中存在一个DATASE ...
- C#遍历DataSet中数据的几种方法总结
//多表多行多列的情况foreach (DataTable dt in YourDataset.Tables) //遍历所有的datatable{foreach (DataRow dr in dt.R ...
随机推荐
- .NET开源的两款第三方登录整合库
前言 我相信做开发的同学应该都对接过各种各样的第三方平台的登录授权,来获取用户信息(如:微信登录.支付宝登录.QQ登录.GitHub登录等等).今天大姚分享两款.NET开源的第三方登录整合库. MrH ...
- TimeLine 时间轴 网站 分享 time.graphics - nodejs 10年图
话说20年 弹指一挥间 https://time.graphics/line/682014 nodejs 10年图 https://time.graphics/line/598790 资料 2022, ...
- 计算引擎-Presto
概述 参考 高质量: B站:https://mp.weixin.qq.com/s/9_lSIFSw5o8sFC8foEtA7w https://mp.weixin.qq.com/s/NmTaJjE0U ...
- 【预训练语言模型】使用Transformers库进行GPT2预训练
基于 HuggingFace的Transformer库,在Colab或Kaggle进行预训练. 本教程提供:英文数据集wikitext-2和代码数据集的预训练. 注:可以自行上传数据集进行训练 目的: ...
- 基于python的指定时段执行实例解析
一 概念: python中库很多,这里熟悉下time和interval的用法 二 实例解析 切记这里的interval,输出的是目前的时间是一个数组. import time from interva ...
- gcc makefile 模板
一 基本概况 在做基本的c代码测试的时候,经常会遇到gcc做编译,作为一个工程师,不存点模板,每次都是自己写的话,那不是非常的浪费体力,程序员本来就累了.在这上面浪费不少时间,吃力不讨好啊. 保存一些 ...
- C++B树的实现
B树的实现 今天我们就来实现以下B树,B树有什么特点那?我们来列举一下 每个非叶子节点中存放若干关键字数据,并且有若干指向儿子节点的指针.指针数目=关键字数目+1 根节点有最少1个,最多m-1个关键字 ...
- day03-2-应用线程02
JavaGUI-坦克大战03-2 7.线程的应用02 7.3.坦克大战4.0版 坦克大战4.0版 增加功能: 功能1.让敌人的坦克也能够发射子弹(可以有多个子弹) 功能2.当我方坦克集中敌人坦克时,敌 ...
- 投屏Sink端音频底层解码并用OpenSLES进行播放
一.代码分析 在公司项目中,音频解码及播放是把数据传到Java层进行解码播放的,其实这个步骤没有必要,完全可以在底层进行处理. 通过代码发现其实也做了在底层进行解码,那么为啥不直接使用底层解码播放呢, ...
- TTS 擂台: 文本转语音模型的自由搏击场
对文本转语音 (text-to-speech, TTS) 模型的质量进行自动度量非常困难.虽然评估声音的自然度和语调变化对人类来说是一项微不足道的任务,但对人工智能来说要困难得多.为了推进这一领域的发 ...