字典嵌套列表 与 列表嵌套字典 导出为csv 的方法
字典嵌套列表 导出csv
{'rank': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30'], 'school_name': ['清华大学', '北京大学', '浙江大学', '上海交通大学', '复旦大学', '南京大学', '中国科学技术大学', '华中科技大学', '武汉大学', '西安交通大学', '四川大学', '中山大学', '哈尔滨工业大学', '同济大学', '北京航空航天大学', '东南大学', '北京师范大学', '北京理工大学', '中国人民大学', '南开大学', '天津大学', '山东大学', '中南大学', '西北工业大学', '华南理工大学', '厦门大学', '吉林大学', '华东师范大学', '中国农业大学', '电子科技大学'], 'school_position': ['北京', '北京', '浙江', '上海', '上海', '江苏', '安徽', '湖北', '湖北', '陕西', '四川', '广东', '黑龙江', '上海', '北京', '江苏', '北京', '北京', '北京', '天津', '天津', '山东', '湖南', '陕西', '广东', '福建', '吉林', '上海', '北京', '四川'], 'school_sum': ['999.4', '912.5', '825.3', '783.3', '697.8', '683.4', '609.9', '609.3', '607.1', '570.2', '561.7', '559.4', '549.8', '548.4', '546.7', '538.5', '534.7', '530.9', '514.7', '497.4', '490.8', '484.3', '475.8', '467.9', '466.7', '458.8', '450.3', '440.7', '433.7', '432.0'], 'school_level': ['37.6', '34.4', '34.1', '35.5', '35.9', '37.7', '40.0', '32.3', '32.8', '34.2', '32.0', '31.4', '32.7', '32.8', '33.2', '34.9', '34.6', '33.1', '34.2', '31.3', '33.0', '29.2', '30.7', '32.7', '30.8', '33.7', '31.2', '32.6', '31.9', '32.3']}
import csv
date={ 'rank':['1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23','24','25','26','27','28','29','30'],'school_position':['北京','北京','浙江','上海','上海','江苏','安徽','湖北','湖北','陕西','四川','广东','黑龙江','上海','北京','江苏','北京','北京','北京','天津','天津','山东','湖南','陕西','广东','福建','吉林','上海','北京','四川'],'school_sum':['999.4','912.5','825.3','783.3','697.8','683.4','609.9','609.3','607.1','570.2','561.7','559.4','549.8','548.4','546.7','538.5','534.7','530.9','514.7','497.4','490.8','484.3','475.8','467.9','466.7','458.8','450.3','440.7','433.7','432.0'] }
with open('F:/zly1.csv','w',encoding='utf8', newline='') as f:
w = csv.writer(f)
fieldnames=['排名', '学校名称', '学校地点', '办学总分', '办学层级']
# fieldnames=data.keys() 以字典原有键作为表头
w.writerow(fieldnames)
for x,y,z,m,n in zip(data['rank'],data['school_name'],data['school_sum'],data['school_position'],data['school_level']):
# w.writerow([x, y,z,m,n])
for x in zip(*date.values()):
print(x)
w.writerow([*x]) # 可改为 w.writerows([x])第二种方法 with open 同上
fieldnames=['排名','学校名称','学校地点','办学总分','办学层级']
# fieldnames=data.keys() #以字典原有键作为表头
if fieldnames is not None:
item = [str(i) for i in fieldnames]
f.write(','.join(item) + "\n")
for item in zip(*data.values()):
item = [str(i) for i in item]
f.write(','.join(item) + "\n")第三种:pandas库
a=pandas.DataFrame(data)
lables=['排名','学校名称','学校地点','办学总分','办学层级']
a.to_csv('F:/zly.csv',header=lables,sep=',',index=False,encoding='utf8')在与zip(…)结合使用时,writerow是单行写入,将一个列表全部写入csv的同一行,
而writerows则可多行写入,将一个二维列表的每一个列表写为一行
列表嵌套字典导出csv
# coding:utf-8
date=[{'大学排名': '1', '大学名称': '清华大学 ', '省市': '北京', '类型': '综合', '总分': '852.5'}, {'大学排名': '2', '大学名称': '北京大学 ', '省市': '北京', '类型': '综合', '总分': '746.7'}, {'大学排名': '3', '大学名称': '浙江大学 ', '省市': '浙江', '类型': '综合', '总分': '649.2'}, {'大学排名': '4', '大学名称': '上海交通大学 ', '省市': '上海', '类型': '综合', '总分': '625.9'}, {'大学排名': '5', '大学名称': '南京大学 ', '省市': '江苏', '类型': '综合', '总分': '566.1'}, {'大学排名': '6', '大学名称': '复旦大学 ', '省市': '上海', '类型': '综合', '总分': '556.7'}, {'大学排名': '7', '大学名称': '中国科学技术大学 ', '省市': '安徽', '类型': '理工', '总分': '526.4'}, {'大学排名': '8', '大学名称': '华中科技大学 ', '省市': '湖北', '类型': '综合', '总分': '497.7'}, {'大学排名': '9', '大学名称': '武汉大学 ', '省市': '湖北', '类型': '综合', '总分': '488.0'}, {'大学排名': '10', '大学名称': '中山大学 ', '省市': '广东', '类型': '综合', '总分': '457.2'}, {'大学排名': '11', '大学名称': '西安交通大学 ', '省市': '陕西', '类型': '综合', '总分': '452.5'}, {'大学排名': '12', '大学名称': '哈尔滨工业大学 ', '省市': '黑龙江', '类型': '理工', '总分': '450.2'}, {'大学排名': '13', '大学名称': '北京航空航天大学 ', '省市': '北京', '类型': '理工', '总分': '445.1'}, {'大学排名': '14', '大学名称': '北京师范大学 ', '省市': '北京', '类型': '师范', '总分': '440.9'}, {'大学排名': '15', '大学名称': '同济大学 ', '省市': '上海', '类型': '理工', '总分': '439.0'}, {'大学排名': '16', '大学名称': '四川大学 ', '省市': '四川', '类型': '综合', '总分': '435.7'}, {'大学排名': '17', '大学名称': '东南大学 ', '省市': '江苏', '类型': '综合', '总分': '432.7'}, {'大学排名': '18', '大学名称': '中国人民大学 ', '省市': '北京', '类型': '综合', '总分': '409.7'}, {'大学排名': '19', '大学名称': '南开大学 ', '省市': '天津', '类型': '综合', '总分': '402.1'}, {'大学排名': '20', '大学名称': '北京理工大学 ', '省市': '北京', '类型': '理工', '总分': '395.6'}, {'大学排名': '21', '大学名称': '天津大学 ', '省市': '天津', '类型': '理工', '总分': '390.3'}, {'大学排名': '22', '大学名称': '山东大学 ', '省市': '山东', '类型': '综合', '总分': '387.9'}, {'大学排名': '23', '大学名称': '厦门大学 ', '省市': '福建', '类型': '综合', '总分': '383.3'}, {'大学排名': '24', '大学名称': '吉林大学 ', '省市': '吉林', '类型': '综合', '总分': '379.5'}, {'大学排名': '25', '大学名称': '华南理工大学 ', '省市': '广东', '类型': '理工', '总分': '379.4'}, {'大学排名': '26', '大学名称': '中南大学 ', '省市': '湖南', '类型': '综合', '总分': '378.6'}, {'大学排名': '27', '大学名称': '大连理工大学 ', '省市': '辽宁', '类型': '理工', '总分': '365.1'}, {'大学排名': '28', '大学名称': '西北工业大学 ', '省市': '陕西', '类型': '理工', '总分': '359.6'}]
with open('F:/zly1.csv','w',encoding='utf8', newline='') as f:
w = csv.writer(f)
# for x, y,z,m,n in zip(data['rank'],data['school_name'],data['school_sum'],data['school_position'],data['school_level']):
# w.writerow([x, y,z,m,n])
w.writerow(date[0].keys())
for x in date:
w.writerow(x.values())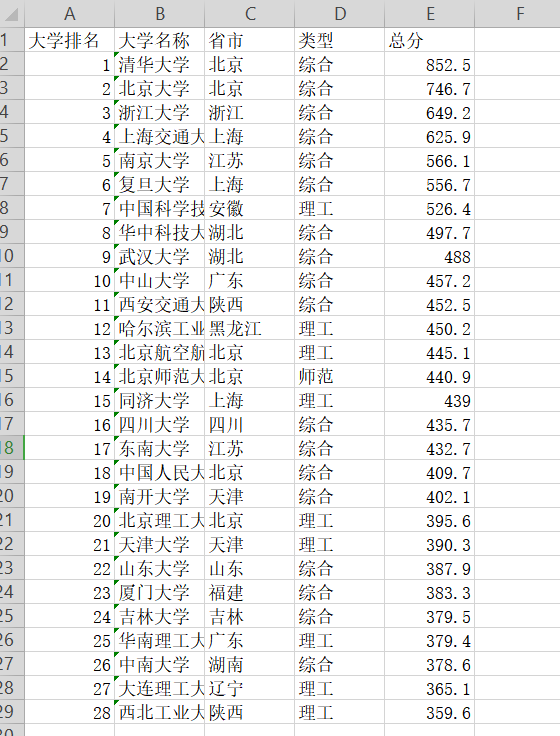
^(* ̄(oo) ̄)^注:
如有导出csv有间隔性空行,可在with open中加入newline 参数
如有编解码 错误,可尝试在代码首行添加 # coding:utf-8
字典嵌套列表 与 列表嵌套字典 导出为csv 的方法的更多相关文章
- 原创 Datareader 导出为csv文件方法
DataReader 是游标只读数据, 如果是大数据导出,用Datatable 将耗费巨大内存资源.因为Datatable 其实就是内存中的一个数据表 代码如下 /// <summary> ...
- python---基础之模块,列表,元组,字典
1. 模块 写模块的时候尽量不要和系统自带的模块的名字相同 调用模块的时候,会先在当前目录下查找是否有这个模块,然后再会如python的环境变量中查找 a.模块1:sys 代码如下: import ...
- python基础知识3——基本的数据类型2——列表,元组,字典,集合
磨人的小妖精们啊!终于可以归置下自己的大脑啦,在这里我要把--整型,长整型,浮点型,字符串,列表,元组,字典,集合,这几个知识点特别多的东西,统一的捯饬捯饬,不然一直脑袋里面乱乱的. 一.列表 1.列 ...
- 基本数据类型-列表_元组_字典_day4
一.列表(list)书写格式:[] #通过list类创建的 li = [1, 12, 9, ", 10, ],"庞麦郎"], "ales", True ...
- Python自动化 【第二篇】:Python基础-列表、元组、字典
本节内容 模块初识 .pyc简介 数据类型初识 数据运算 列表.元组操作 字符串操作 字典操作 集合操作 字符编码与转码 一.模块初识 Python的强大之处在于他有非常丰富和强大的标准库和第三方库, ...
- Python变量类型(l整型,长整形,浮点型,复数,列表,元组,字典)学习
#coding=utf-8 __author__ = 'Administrator' #Python变量类型 #Python数字,python支持四种不同的数据类型 int整型 long长整型 flo ...
- !!Python字典增删操作技巧简述+Python字典嵌套字典与排序
http://developer.51cto.com/art/201003/186006.htm Python编程语言是一款比较容易学习的计算机通用型语言.对于初学者来说,首先需要掌握的就是其中的一些 ...
- python【第二篇】列表、元组、字典及文件操作
本节内容 列表 元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1.列表 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作:列表有序.可变.元素 ...
- python 基础,包括列表,元组,字典,字符串,set集合,while循环,for循环,运算符。
1.continue 的作用:跳出一次循环,进行下一次循环 2.break 跳出不再循环 3.常量 (全是大写)NAME = cjk 一般改了会出错 4.py ...
- 第三章 Python 的容器: 列表、元组、字典与集合
列表是Python的6种内建序列(列表,元组,字符串,Unicode字符串,buffer对象,xrange对象)之一, 列表内的值可以进行更改,操作灵活,在Python脚本中应用非常广泛 列表的语法格 ...
随机推荐
- 开源IM项目OpenIM 客户端SDK架构剖析-确保消息的有序性,以及消息百分百可达
开源IM项目OpenIM第二版对于客户端架构进行了局部重构,解决了消息触发时序等bug,也梳理了内部模块.目前已经接近尾声,本文重点讲解SDK架构,以便大家深入了解OpenIM,并希望大家能深度参与开 ...
- 深入探索OCR技术:前沿算法与工业级部署方案揭秘
深入探索OCR技术:前沿算法与工业级部署方案揭秘 注:以上图片来自网络 1. OCR技术背景 1.1 OCR技术的应用场景 OCR是什么 OCR(Optical Character Recogniti ...
- paddle之visualDL工具使用,可视化利器。
相关链接: [一]AI Studio 项目详解[(一)VisualDL工具.环境使用说明.脚本任务.图形化任务.在线部署及预测]PARL_汀.的博客-CSDN博客 isualDL 是一个面向深度学习任 ...
- 2.6 PE结构:导出表详细解析
导出表(Export Table)是Windows可执行文件中的一个结构,记录了可执行文件中某些函数或变量的名称和地址,这些名称和地址可以供其他程序调用或使用.当PE文件执行时Windows装载器将文 ...
- 4.8 x64dbg 学会扫描应用堆栈
堆栈是计算机中的两种重要数据结构 堆(Heap)和栈(Stack)它们在计算机程序中起着关键作用,在内存中堆区(用于动态内存分配)和栈区(用于存储函数调用.局部变量等临时数据),进程在运行时会使用堆栈 ...
- 由刷题学习 heapq
今日一题是 面试题 17.14. 最小K个数 https://leetcode-cn.com/problems/smallest-k-lcci/ 还好 提示 0 <= len(arr) < ...
- 【Matlab】蒙特卡罗法模拟圆周率+对应解析的GIF生成【超详细的注释和解释】
文章目录 前言 模拟思路 GIF模拟动图的生成 GIF动图生成的基本思路 单张静态图的生成 GIF的生成 尾声 前言 因为博主最近要准备数学建模大赛了,在学习matlab和python之余,博主也会继 ...
- Linux输出转换命令 xargs
一.基本用法 xargs命令的作用,是将标准输入转为命令行参数. 原因:大多数命令都不接受标准输入作为参数,只能直接在命令行输入参数,这导致无法用管道命令传递参数 如下面 echo 不接受标准输出做参 ...
- ListView改变行高的技巧
改变 ListView 的行高 (Line Height) (cjc,2009.6.2) 改变 ListView 的行高 (Line Height) (cjc,2009.6.2) ListView在R ...
- JS leetcode 实现strStr()函数 题解分析
壹 ❀ 引 前几天心情比较浮躁,烦心事太多,偷懒了3天,还是继续刷leetcode.那么今天做的题目为实现 strStr() 函数.,原题如下: 给定一个 haystack 字符串和一个 needle ...