聊聊ChatGLM-6B的源码分析
基于ChatGLM-6B第一版,要注意还有ChatGLM2-6B以及ChatGLM3-6B
PrefixEncoder
作用:在微调时(以P-Tuning V2为例),方法训练时冻结模型的全部参数,只激活PrefixEncoder的参数。
其源码如下,整体来看是比较简单的。
class PrefixEncoder(torch.nn.Module):
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# 使用一个两层(线性层)的MLP编码prefix
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.hidden_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(config.hidden_size, config.hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.hidden_size, config.num_layers * config.hidden_size * 2)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.num_layers * config.hidden_size * 2)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
为什么源码注释中会说到MLP?定位追溯:
self.mlp = GLU(
hidden_size,
inner_hidden_size=inner_hidden_size,
bias=use_bias,
layer_id=layer_id,
params_dtype=params_dtype,
empty_init=empty_init
)
def default_init(cls, *args, **kwargs):
return cls(*args, **kwargs)
class GLU(torch.nn.Module):
def __init__(self, hidden_size, inner_hidden_size=None,
layer_id=None, bias=True, activation_func=gelu, params_dtype=torch.float, empty_init=True):
super(GLU, self).__init__()
if empty_init:
init_method = skip_init
else:
init_method = default_init
self.layer_id = layer_id
self.activation_func = activation_func
# Project to 4h.
self.hidden_size = hidden_size
if inner_hidden_size is None:
inner_hidden_size = 4 * hidden_size
self.inner_hidden_size = inner_hidden_size
self.dense_h_to_4h = init_method(
torch.nn.Linear,
self.hidden_size,
self.inner_hidden_size,
bias=bias,
dtype=params_dtype,
)
# Project back to h.
self.dense_4h_to_h = init_method(
torch.nn.Linear,
self.inner_hidden_size,
self.hidden_size,
bias=bias,
dtype=params_dtype,
)
def forward(self, hidden_states):
"""
hidden_states: [seq_len, batch, hidden_size]
"""
# [seq_len, batch, inner_hidden_size]
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = self.activation_func(intermediate_parallel)
output = self.dense_4h_to_h(intermediate_parallel)
return output
# 转载请备注出处:https://www.cnblogs.com/zhiyong-ITNote/
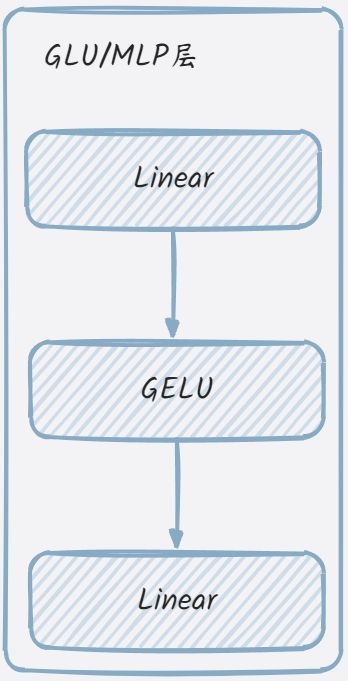
init_method对应到default_init,这个函数的作用与直接调用类构造函数相同,但它提供了一种更灵活的方式来创建类的实例,因为它可以接受任意数量的位置参数和关键字参数。在Pytorch中,用于模块化的构造函数。从源码分析来看,GLU/MLP类就是构造了两个线性层与gelu激活函数,其结构可简化如下:
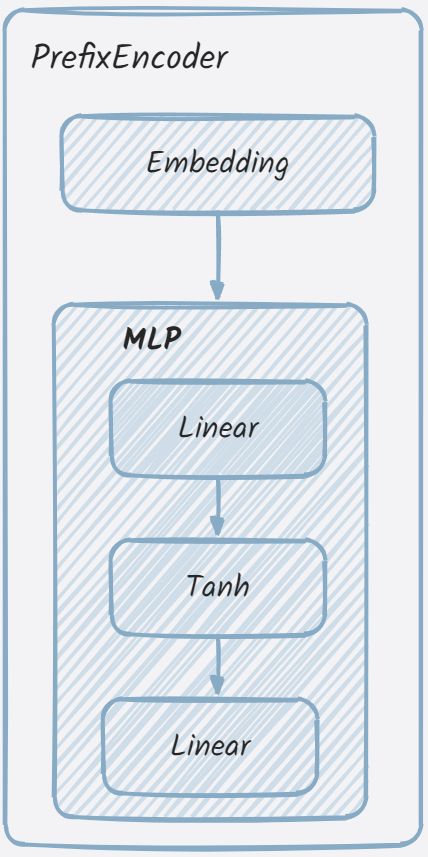
从PrefixEncoder类的初始化方法来看,其就是embedding层与MLP的组合。其结构可简化如下:
详细解读可参考 ChatGLM的模型架构
Q:在这里还有一个问题,从哪里可以定位溯源到微调时禁用了全部的参数,只激活PrefixEncoder的参数并调用了该类?
激活函数与位置编码
代码简单明了,RoPE的理论知识可以多了解。
attention_fn
伪代码表示为:
def attention_fn(
self,
query_layer,
key_layer,
value_layer,
attention_mask,
hidden_size_per_partition,
layer_id,
layer_past=None,
scaling_attention_score=True,
use_cache=False,
):
xxxx
标准的注意力机制计算公式如下:




多头注意力就是将多个单头注意力的结果拼接起来,再点乘一个新的权重参数。


attention_fn函数实现了注意力的核心计算过程(即上述数学表达式),包括计算注意力分数、注意力概率和上下文层。这些计算对于实现许多自然语言处理任务,如语言建模、命名实体识别等,都是非常重要的。
SelfAttention
伪代码表示为:
class SelfAttention(torch.nn.Module):
xxxx
attention_mask_func将注意力掩码应用于Transformer模型中的注意力得分中。
@staticmethod
def attention_mask_func(attention_scores, attention_mask):
attention_scores.masked_fill_(attention_mask, -10000.0)
return attention_scores
apply_rotary_pos_emb_index函数为 注入了RoPE位置信息,然后调用
注入了RoPE位置信息,然后调用attention_fn计算注意力概率、上下文层表示,并得到返回值。这些都是在forward函数中调用处理的。

最后还调用了dense对上下文表示做线性计算,返回输出。
GLU
GLU也可以理解为是MLP,在后面版本的ChatGLM中,去掉了GLU类的定义声明,直接换成了MLP。在上面已经写过不再赘述。
GLMBlock
一般都会把GLMBlock对应为transformer结构的实现。从其构造函数来看,主要是拼接各个层到一起。
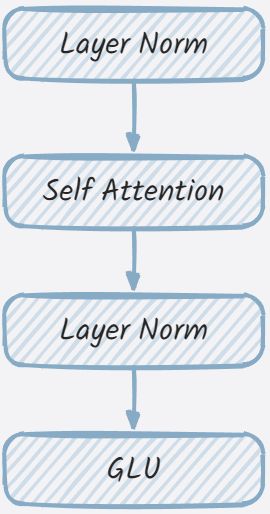
从代码来看,中间有两次的残差连接,如下所示
# Residual connection.
alpha = (2 * self.num_layers) ** 0.5
hidden_states = attention_input * alpha + attention_output
mlp_input = self.post_attention_layernorm(hidden_states)
# MLP.
mlp_output = self.mlp(mlp_input)
# Second residual connection.
output = mlp_input * alpha + mlp_output
ChatGLMPreTrainedModel
TODO....
ChatGLMModel
TODO....
聊聊ChatGLM-6B的源码分析的更多相关文章
- 【小家Spring】聊聊Spring中的数据绑定 --- DataBinder本尊(源码分析)
每篇一句 唯有热爱和坚持,才能让你在程序人生中屹立不倒,切忌跟风什么语言或就学什么去~ 相关阅读 [小家Spring]聊聊Spring中的数据绑定 --- 属性访问器PropertyAccessor和 ...
- HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- TextView 的新特性,Autosizing 到底是如何实现的? | 源码分析
一.前言 Hi,大家好,我是承香墨影! 前两天聊了一下 Autosizing 的使用,反映还不错.毕竟是这种能解决实际问题的新 Api,确实在需要的时候,用起来会很顺手. 简单回顾一下,Autosiz ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- HashMap实现原理及源码分析(JDK1.7)
转载:https://www.cnblogs.com/chengxiao/p/6059914.html 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技 ...
- Dubbo 源码分析 - SPI 机制
1.简介 SPI 全称为 Service Provider Interface,是 Java 提供的一种服务发现机制.SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加 ...
- 转载-HashMap1.7源码分析
原文地址-https://www.cnblogs.com/chengxiao/p/6059914.html HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重 ...
- MyBatis 源码分析系列文章导读
1.本文速览 本篇文章是我为接下来的 MyBatis 源码分析系列文章写的一个导读文章.本篇文章从 MyBatis 是什么(what),为什么要使用(why),以及如何使用(how)等三个角度进行了说 ...
- EasyUI学习总结(三)——easyloader源码分析(转载)
声明:这一篇文章是转载过来的,转载地址忘记了,原作者如果看到了,希望能够告知一声,我好加上去! easyloader模块是用来加载jquery easyui的js和css文件的,而且它可以分析模块的依 ...
- HashMap实现原理及源码分析之JDK7
攻克集合第一关!! 转载 http://www.cnblogs.com/chengxiao/ 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如m ...
随机推荐
- Azure Data Factory(九)基础知识回顾
一,引言 在本文中,我们将继续了解什么是 Azure Data Factory,Azure Data Factory 的工作原理,Azure Data Factory 数据工程中的数据管道,并了解继承 ...
- 关于Word转PDF的几种实现方案
在.NET中,你可以使用Microsoft.Office.Interop.Word库来进行Word到PDF的转换.这是一个示例代码,但请注意这需要在你的系统上安装Microsoft Office. 在 ...
- Go接口 - 构建可扩展Go应用
本文深入探讨了Go语言中接口的概念和实际应用场景.从基础知识如接口的定义和实现,到更复杂的实战应用如解耦与抽象.多态.错误处理.插件架构以及资源管理,文章通过丰富的代码示例和详细的解释,展示了Go接口 ...
- CSP初赛错题集
初赛错题集 洛谷有题 NOIP 2018 T9 给定一个含N 个不相同数字的数组,在最坏情况下,找出其中最大或最小的数,至少需要N - 1 次比较操作.则最坏情况下,在该数组中同时找最大与最小的数至少 ...
- vscode提取扩展时出错XHR failed
问题分析 使用cmd的ping工具尝试ping域名 marketplace.visualstudio.com 无法ping通 解决方案 1. 打开本地配置文件 C:\Windows\System32 ...
- JAVA类的加载(2) ——按需加载(延迟加载)
1.例1: 1 /* 2 按需加载:当你不去实例化Cat时,Cat相关类都不会被加载,即按需加载(需要时加载) 3 1.先加载父类 4 2.初始化类 5 3.类只加载一次(暂且这么认为)--缓存 6 ...
- idea的mybatis插件free mybatis plugin(或 Free MyBatis Tool),很好用
为大家推荐一个idea的mybatis插件----free mybatis plugin(或 Free MyBatis Tool),很好用(个人觉得free mybatis plugin更好用一点,可 ...
- Util应用框架基础(六) - 日志记录(三) - 写入 Seq
本文是Util应用框架日志记录的第三篇,介绍安装和写入 Seq 日志系统的配置方法. 安装 Seq Seq是一个日志管理系统,对结构化日志数据拥有强大的模糊搜索能力. Util应用框架目前主要使用 S ...
- this.$router 与this.$route的区别
this.$router是Vue-Router的实例,需要导航到不同路由则用this.$router.push方法 this.$route为当前路由的跳转对象,包含当前路由的name.path.que ...
- SpringBoot 项目优雅实现读写分离
一.读写分离介绍 当使用Spring Boot开发数据库应用时,读写分离是一种常见的优化策略.读写分离将读操作和写操作分别分配给不同的数据库实例,以提高系统的吞吐量和性能. 读写分离实现主要是通过动态 ...