【flask】flask-sqlalchemy使用 flask-migrate使用 flask项目演示
昨日回顾
类装饰器可能有两种含义:
- 使用类作为装饰器
- 装饰类的装饰器
基本增删查改:单表
# 0 sqlalchemy创建表:Base = declarative_base()
-只能创建和删除
-不能创建数据库
-不能修改表
# 1 快速插入数据
-借助于session对象
from sqlalchemy.orm import sessionmaker
Session=sessionmaker(bind=engine)
session=Session() #会话,连接
session.add(表模型的对象)
session.add_all([对象,对象])
session.commit()
session.close()
-session.close没有将连接断开,而是将链接放入连接池中。
# 2 多线程情况下,并发安全问题
-全局就用一个session
-scoped_session可以保证并发情况下,session的安全
-scoped_session类,内部有个local对象,把session放到了local中
-全局就使用一个session,会有并发安全的问题。
-每个session就使用当前线程的,如果当前线程没有session就新建一个,放在local对象中。
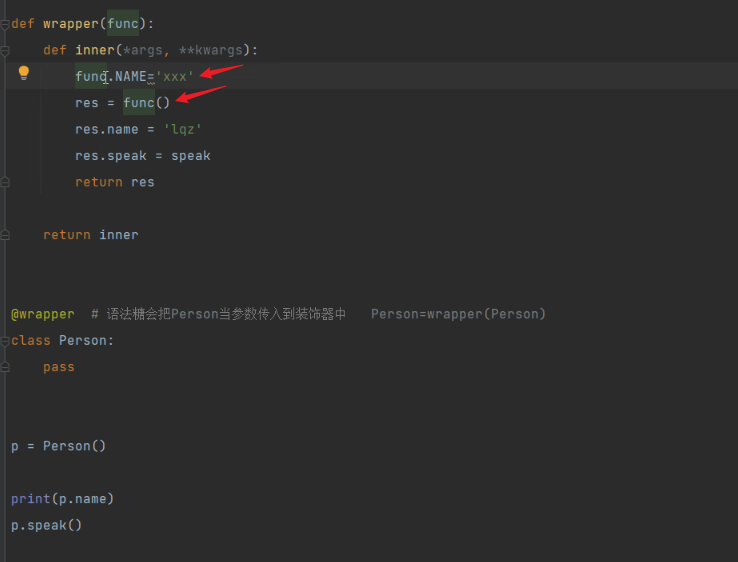
# 3 类装饰器
-装饰类的装饰器:加在类上的装饰器,昨天讲过了
-类作为装饰器用:
# 类作为装饰器来用
class Wrapper():
def __init__(self, func):
self.func = func
def __call__(self, *args, **kwargs):
# 前面加代码
print('我在你前面')
res = self.func(*args, **kwargs)
# 后面加代码
print('我在你后面')
return res
@Wrapper # add=Wrapper(add)--->触发Wrapper的__init__---->现在add是Wrapper类的对象
def add():
print('add')
# 4 基本增删查改:单表
-增:add add_all
-查:filter:表达式,filter_by:具体值
-删:查出来.delete()
-改:
查出来.update({'name':"lqz"})
查出来.update({User.name:"lqz"})
对象.name='lqz'
add(对象)
# 5 高级查询
-in
-between
-like
-排序
-分页
-原生sql
-分组。。。
# 6 一对多关系的建立
Person :hobby_id,hobby
Hobby
-新增,基于对象的新增
-基于对象的跨表正向反向
# 7 多对多
GIrl
Boy
Boy2Girl
-新增
-基于对象的跨表查询
# 8 连表查询
res = session.query(Person, Hobby).filter(Person.hobby_id == Hobby.id).all()
session.query(Person).join(Hobby).all()
今日内容
1 flask-sqlalchemy使用
# 集成到flask中,直接使用sqlalchemy,看代码
# 有个第三方flask-sqlalchemy,帮助咱们快速的集成到flask中
# flask-sqlalchemy实际上是将sqlalchemy那一套再封装在了一个对象里。
# engine链接的部分放在配置文件拿,就不需要每次都写engine连接部分的代码了。
# sqlalchemy中也可以使用序列化类,要安装第三方模块flask-restful。
# 使用flask-sqlalchemy集成
1 导入 from flask_sqlalchemy import SQLAlchemy
2 实例化得到对象
db = SQLAlchemy()
3 将db注册到app中
db.init_app(app)
4 视图函数中使用session
全局的db.session # 线程安全的
5 models.py 中继承Model
db.Model
6 写字段
username = db.Column(db.String(80), unique=True, nullable=False)
7 配置文件中加入
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root@127.0.0.1:3306/ddd?charset=utf8"
SQLALCHEMY_POOL_SIZE = 5
SQLALCHEMY_POOL_TIMEOUT = 30
SQLALCHEMY_POOL_RECYCLE = -1
# 追踪对象的修改并且发送信号
SQLALCHEMY_TRACK_MODIFICATIONS = False
2 flask-migrate使用
原生的sqlalchemy,不支持修改表。
如果我们想实现类似于django的功能:表发生变化,都会有记录,自动同步到数据库。需要安装第三方模块flask-migrate。
# 表发生变化,都会有记录,自动同步到数据库中
# 原生的sqlalchemy,不支持修改表的
# flask-migrate可以实现类似于django的
python manage.py makemigrations #记录
python manage.py migrate #真正的同步到数据库
# 使用步骤
0 flask:2.2.2 flask-script:2.0.3
1 第一步:安装,依赖于flask-script
pip3.8 install flask-migrate==2.7.0
2 在app所在的py文件中
from flask_script import Manager
from flask_migrate import Migrate, MigrateCommand
manager = Manager(app)
Migrate(app, db)
manager.add_command('db', MigrateCommand)
manager.run() # 以后使用python manage.py runserver 启动项目
3 以后第一次执行一下
python manage.py db init # 生成一个migrations文件夹,里面以后不要动,记录迁移的编号
4 以后在models.py 写表,加字段,删字段,改参数
5 只需要执行
python manage.py db migrate # 记录
python manage.py db upgrade # 真正的同步进去
3 flask项目演示
# 0 创建数据库 movie
# 1 pycharm打开项目
# 3 在models中,注释,解开注释,右键执行,迁移表
# 4 在models中恢复成原来的
# 5 在命令行中python manage.py runserver运行项目
# 6 访问前台和后台
【flask】flask-sqlalchemy使用 flask-migrate使用 flask项目演示的更多相关文章
- 9、flask之SQLAlchemy
本篇导航: 介绍 使用 SQLAlchemy-Utils 一. 介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之 ...
- flask之SQLAlchemy
本篇导航: 介绍 使用 SQLAlchemy-Utils 一. 介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之 ...
- Flask之SQLAlchemy,flask_session以及蓝图
数据库操作 ORM ORM 全拼 Object-Relation Mapping,中文意为 对象-关系映射.主要实现模型对象到关系数据库数据的映射 优点 : 只需要面向对象编程, 不需要面向数据库编写 ...
- python 全栈开发,Day142(flask标准目录结构, flask使用SQLAlchemy,flask离线脚本,flask多app应用,flask-script,flask-migrate,pipreqs)
昨日内容回顾 1. 简述flask上下文管理 - threading.local - 偏函数 - 栈 2. 原生SQL和ORM有什么优缺点? 开发效率: ORM > 原生SQL 执行效率: 原生 ...
- No module named flask.ext.sqlalchemy.SQLALchemy
在学习<OReilly.Flask.Web.Development>的时候,按照书的例子到了数据库那一章,在运行python hello.py shell的时候出现了“ImportErro ...
- flask 使用 SQLAlchemy 的两种方式
1. 使用 flask-SQLAlchemy 扩展 # flask-ext-sqlalchemy.py from flask import Flask from flask.ext.sqlalchem ...
- flask 与 SQLAlchemy的使用
flask 与 SQLAlchemy的使用 安装模块 pip install flask-sqlalchemy 在单个python中与flask使用 # 文件名:manage.py from flas ...
- 描述怎样通过flask+redis+sqlalchemy等工具,开发restful api
flask开发restful api系列(8)-再谈项目结构 摘要: 进一步介绍flask的项目结构,使整个项目结构一目了然.阅读全文 posted @ 2016-06-06 13:54 月儿弯弯02 ...
- Flask最强攻略 - 跟DragonFire学Flask - 第十四篇 Flask-SQLAlchemy
前不久刚刚认识过了SQLAlchemy,点击这里复习一下 当 Flask 与 SQLAlchemy 发生火花会怎么样呢? Flask-SQLAlchemy就这么诞生了 首先要先安装一下Flask-SQ ...
- Flask最强攻略 - 跟DragonFire学Flask - 第九篇 Flask 中的蓝图(BluePrint)
蓝图,听起来就是一个很宏伟的东西 在Flask中的蓝图 blueprint 也是非常宏伟的 它的作用就是将 功能 与 主服务 分开怎么理解呢? 比如说,你有一个客户管理系统,最开始的时候,只有一个查看 ...
随机推荐
- 文心一言 VS 讯飞星火 VS chatgpt (134)-- 算法导论11.2 6题
六.用go语言,假设将n 个关键字存储到一个大小为 m 且通过链接法解决冲突的散列表中,同时已知每条链的长度,包括其中最长链的长度 L,请描述从散列表的所有关键字中均匀随机地选择某一元素并在 O(L· ...
- js检测数据类型得四种方式
1.typeof:返回一个字符串,表示操作数的类型. 语法: typeof(变量) //or typeof 变量 示例: console.log(typeof 2)//number c ...
- 【Javaweb】Servlet五 | HTTP协议【详解】
什么是HTTP协议 什么是协议? 协议是指双方或多方相互约定好,大家都需要遵守的规则,叫协议. 所谓HTTP协议,就是指,客户端和服务器之间通信时,发送的数据,需要遵守的规则,叫做HTTP协议. HT ...
- mySql中使用命令行建表基本操作
一:打开命令行启动mysql服务 注意事项:应该使用管理员身份打开命令行键入命令:net start mysql (鼠标右键使用管理员身份打开),否则会出现拒绝访问报错. 二:登陆数据库 登陆命令为& ...
- 可视化学习:WebGL的基础使用
引言 继续复习可视化的学习.WebGL和其他Web端的图形系统存在很大的不同,是OpenGL ES规范在浏览器的实现,它最大的不同就在于它更接近底层,可以由开发者直接操作GPU来实现绘图,性能很好,可 ...
- ubuntu 22.04.1安装雷池开源waf应用防火墙
ubuntu 22.04.1安装雷池开源waf应用防火墙 雷池waf是开源应用防火墙,国内首创.业内领先的智能语义分析算法 官方网站:https://waf-ce.chaitin.cn/ 官方文档:h ...
- 基于winform(C#)的飞鸟小游戏
本项目是一款基于C# (winform)版本的飞鸟小游戏,是一款益智类游戏 其效果如下图所示 如上图所示为飞鸟游戏的初始化界面: 可以看到游戏包含了四个功能: 启动 注册 登陆 排行榜 启动:是用于开 ...
- Flask-SQLAlchemy常用新旧查询语法对比
https://docs.sqlalchemy.org/en/20/tutorial/data.html 新旧版语法的说明 在2.x的SQLALchemy中,查询语法为: db.session.exe ...
- Keepalived 高可用详解
Keepalived 详解 1.Keepalived介绍 Keepalived是一个基于VRRP协议来实现LVS服务高可用方案,可以利用其来避免单点故障.一个LVS服务会使用2台服务器运行Keep ...
- 开源MES/免费MES/开源mes 生产管理流程
开源MES/免费MES/开源MES生产流程管理 一.什么是MES生产管理流程 生产管理系统(又称制造执行系统)是一种集成了计划.生产.质量控制.库存管理和材料申请等生产流程的管理系统.工厂生产管理流程 ...