论文解读丨LayoutLM: 面向文档理解的文本与版面预训练
摘要:LayoutLM模型利用大规模无标注文档数据集进行文本与版面的联合预训练,在多个下游的文档理解任务上取得了领先的结果。
本文分享自华为云社区《论文解读系列二十五:LayoutLM: 面向文档理解的文本与版面预训练》,作者: 松轩。

1. 引言
文档理解或文档智能在当今社会有着广泛的用途。如图1所示的商业文档中记录有丰富、具体的信息,同时也呈现着复杂多变的版式结构,因此如何准确地理解这些文档是一个极具挑战性的任务。在本文之前,基于模型的文档理解有着如下两点不足: (1) 针对具体场景,采用人工标注数据进行端到端的有监督训练,没有利用大规模的无标注数据,且模型难以泛化至其他版式或场景;(2)利用CV或NLP领域的预训练模型进行特征提取,没有考虑文本与版面信息的联合训练。

图1. 不同版面与格式的商业文档扫描图像
针对上述不足,微软亚研院的研究者们提出了如图2所示的LayoutLM模型 [1],利用大规模无标注文档数据集进行文本与版面的联合预训练,在多个下游的文档理解任务上取得了领先的结果。具体地,LayoutLM模型很大程度上借鉴了BERT模型 [2]。在模型输入层面,LayoutLM在BERT采用的文本与位置特征基础上,新增了两个特征:(1)2-D位置特征,也就是文档版面特征;(2)文档图像全局特征与单词级别特征,采用了Faster R-CNN [3] 的ROI特征。在学习目标层面,采用了掩码视觉语言模型(Masked Visual-Language Model, MVLM)损失与多标签文档分类(Multi-label Document Classification,MDC)损失进行多任务学习。在训练数据层面,LayoutLM在IIT-CDIP Test Collection 1.0 [4] 数据集的约一千一百万张的扫描文档图像上进行预训练,该数据集包含信件、备忘录、电子邮件、表格、票据等各式各样的文档类型。文档图像的文本内容与位置信息通过开源的Tesseract [5] 引擎进行获取。
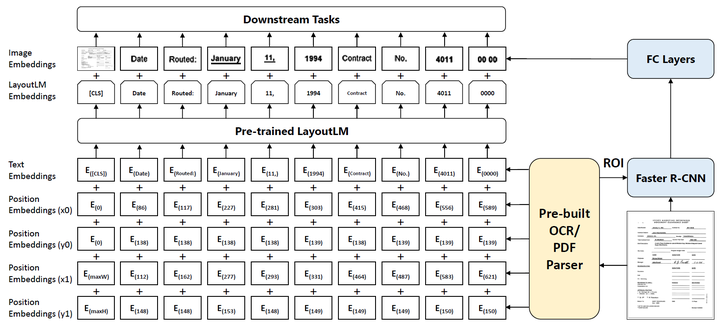
图2. LayoutLM模型结构示意图
2. LayoutLM
2.1 模型结构
LayoutLM在BERT模型结构基础上,新增了两个输入特征:2-D位置特征与图像特征。
2-D位置特征:2-D位置特征的目的在于编码文档中的相对空间位置关系。一个文档可视为一个坐标系统,其左上角即为坐标原点(0,0)(0,0)。对于一个单词,其包围盒能够以坐标(x_0,y_0,x_1,y_1)(x0,y0,x1,y1)进行表示,其中 (x_0,y_0)(x0,y0) 表示左上角坐标,(x_1,y_1)(x1,y1)表示右下角坐标。x_0x0与x_1x1共享嵌入层参数XX,y_0y0与y_1y1共享嵌入层参数YY。特别地,整个文档图像的包围盒为(0,0,W,H)(0,0,W,H),WW与HH分别表示文档图像的宽与高。
图像特征:根据单词的包围盒,LayoutLM利用ROI操作从Faster R-CNN的输出特征图中生成图像区域特征,与单词一一对应。对于特殊的[CLS]标记([CLS]标记的输出接分类层,用于文档分类任务,详情可见BERT模型),则采用整图的平均特征作为该标记的图像特征。应该注意的是,LayoutLM在预训练阶段并没有采用图像特征;图像特征仅在下游任务阶段可以选择性地加入,而生成图像特征的Faster R-CNN模型权重来自于预训练模型且不作调整。
2.2 LayoutLM预训练
预训练任务#1:掩码视觉语言模型MVLM。在预训练阶段,随机掩盖掉一些单词的文本信息,但仍保留其位置信息,然后训练模型根据语境去预测被掩盖掉的单词。通过该任务,模型能够学会理解上下文语境并利用2-D位置信息,从而连接视觉与语言这两个模态。
预训练任务#2:多标签文档分类MDC。文档理解的许多任务需要文档级别的表征。由于IIT-CDIP数据中的每个文档图像都包含多个标签,LayoutLM利用这些标签进行有监督的文档分类任务,以令[CLS]标记输出更为有效的文档级别的表征。但是,对于更大规模的数据集,这些标签并非总可获取,因此该任务仅为可选项,并且实际上在后续的LayoutLMv2中被舍弃。
2.3 LayoutLM模型微调
在该论文中,预训练的LayoutLM模型在三个文档理解任务上进行模型微调,包括表格理解、票据理解以及文档分类,分别采用了FUNSD、SROIE以及RVL-CDIP数据集。对于表格与票据理解任务,模型为每个输入位置进行{B, I, E, S, O}序列标记预测,从而检测每个类别的实体。对于文档分类任务,模型利用[CLS]标记的输出特征进行类别预测。
3. 实验
LayoutLM模型与BERT模型具有一致的Transformer [6] 网络结构,因此采用BERT模型的权重进行初始化。具体地,BASE模型为12层的Transformer,每层包含768个隐含单元与12个注意力头,共有113M参数;LARGE模型为24层的Transformer,每层包含1024个隐含单元与16个注意力头,共有343M参数。具体的训练细节与参数设定请参见论文。
表格理解。表格1与表格2展示了LayoutLM在表格理解数据集FUNSD上的实验结果,包含不同模型、不同训练数据量、不同训练时长、不同预训练任务等多种设定。首先,可以看到,引入了视觉信息的LayoutLM模型在精度上取得了大幅度的提升。其次,更多的训练数据、更长的训练时间、更大的模型能够有效地提升模型精度。最后,MDC预训练任务在数据量为1M与11M时具有相反效果,大数据量情况下仅用MVLM效果更优。
此外,原论文作者还对比了LayoutLM模型不同初始化方式对于下游任务的影响,如表格3所示。可以看到,利用RoBERTa(A Robustly Optimized BERT)模型参数进行初始化,相比于利用原始BERT模型参数进行初始化,能够一定程度提升LayoutLM模型在下游任务上的精度。
表1. FUNSD数据集上的准确率
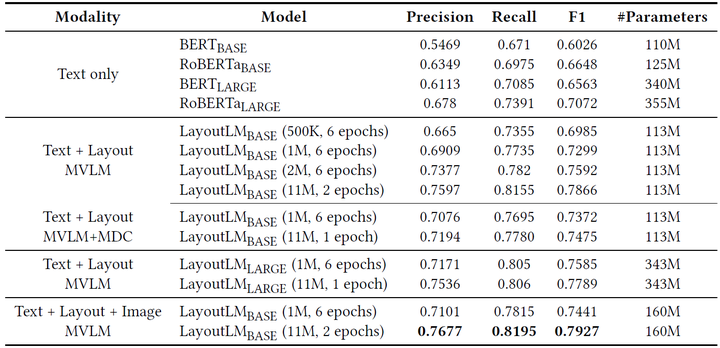
表2. 不同训练数据量与训练时长的LayoutLM BASE模型(Text + Layout, MVLM)在FUNSD数据集上的准确率
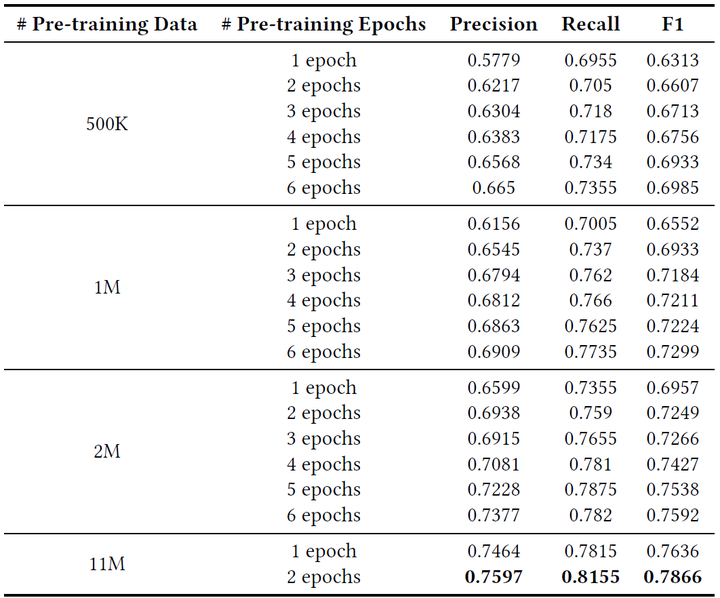
表3. 不同初始化方式的LayoutLM模型(Text + Layout, MVLM)在FUNSD数据集上的准确率
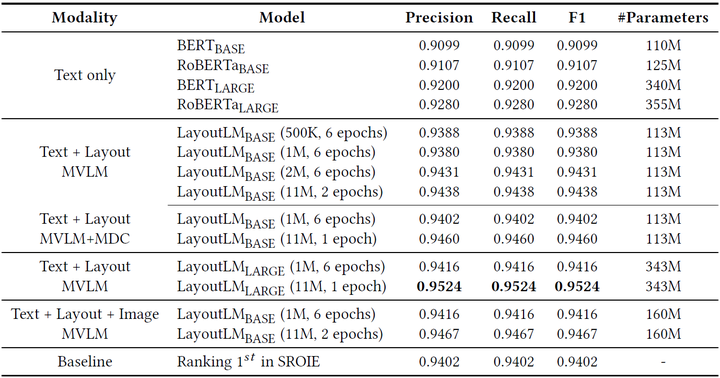
票据理解。表格4展示了LayoutLM在票据理解数据集SROIE上的实验结果。可以看到,LayoutLM LARGE模型的结果优于当时SROIE竞赛榜单第一名的结果。
表4. SROIE数据集上的准确率
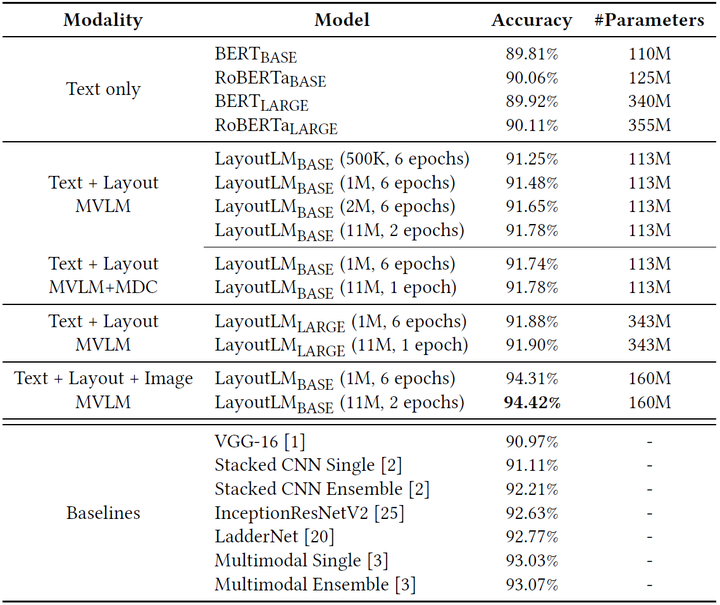
文档图像分类。表格5展示了LayoutLM在文档图像分类数据集RVL-CDIP上的实验结果。同样地,可以看到,LayoutLM取得了领先的结果。
表5. RVL-CDIP数据集上的分类准确率
4. 小结
本文介绍的LayoutLM模型利用大规模无标注文档数据集进行文本与版面的联合预训练,在多个下游的文档理解任务上取得了领先的结果。论文作者指出,更大规模的数据集与模型、在预训练阶段考虑图像特征是下一步的研究方向。
[1] Xu Y, Li M, Cui L, et al. LayoutLM: Pre-training of text and layout for document image understanding. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.
[2] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding. Proceedings of NAACL-HLT. 2019: 4171-4186.
[3] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 2015, 28: 91-99.
[4] Lewis D, Agam G, Argamon S, et al. Building a test collection for complex document information processing. Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. 2006: 665-666.
[5] https://github.com/tesseract-ocr/tesseract
[6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in neural information processing systems. 2017: 5998-6008.
想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习
论文解读丨LayoutLM: 面向文档理解的文本与版面预训练的更多相关文章
- 百度大脑UNIT3.0解读之对话式文档问答——上传文档获取对话能力
在日常生活中,用户会经常碰到很多复杂的规章制度.规则条款.比如:乘坐飞机时,能不能带宠物上飞机,3岁小朋友是否需要买票等.在工作中,也会面对公司多样的规定制度和报销政策.比如:商业保险理赔需要什么材料 ...
- 007-elasticsearch5.4.3【一】概述、Elasticsearch 访问方式、Elasticsearch 面向文档、常用概念
一.概述 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Elasticsearch 也是使用 Java 编写的,它的内部使用 L ...
- RethinkDB是什么?—— 面向文档的NOSQL数据库,MVCC+Btree索引,pushes JSON to your apps in realtime采用push思路,优化的ssd存储
RethinkDB是什么? RethinkDB是新一代的面向文档的数据库存储管理系统,原本是MySQL中针对SSD优化的一个存储引擎,后来脱离了MySQL成为了独立的系统. 数据如何存储在磁盘上? 数 ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- JSP实现word文档的上传,在线预览,下载
前两天帮同学实现在线预览word文档中的内容,而且需要提供可以下载的链接!在网上找了好久,都没有什么可行的方法,只得用最笨的方法来实现了.希望得到各位大神的指教.下面我就具体谈谈自己的实现过程,总结一 ...
- 如何使用免费PDF控件从PDF文档中提取文本和图片
如何使用免费PDF控件从PDF文档中提取文本和图片 概要 现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PD ...
- 利用java从docx文档中提取文本内容
利用java从docx文档中提取文本内容 使用Apache的第三方jar包,地址为https://poi.apache.org/ docx文档内容如图: 目录结构: 每个文件夹的名称为日期加上来源,例 ...
- MongoDB实战读书笔记(二):面向文档的数据
1 schema设计原则 1.1 关系型数据库的三大设计范式 第一范式(1NF)无重复的列 第二范式(2NF)属性完全依赖于主键 [ 消除部分子函数依赖 ] 第三范式(3NF)属性不依赖于其它非主属性 ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- 论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别.文字检测.文字识别.单元格和文字框对齐.其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识 ...
随机推荐
- 将.View.dll文件反编译出来的*Views*.cs文件转换成.cshtml
先使用反编译工具将.View.dll文件反编译放入文件夹,然后将文件夹整体复制进\src\viewcs2cshtml\viewcs2cshtml\bin\Debug\net6.0\viewcs 复制完 ...
- 【.NET】多线程:自动重置事件与手动重置事件的区别
在多线程编程中,如果每个线程的运行不是完全独立的.那么,一个线程执行到某个时刻需要知道其他线程发生了什么.嗯,这就是所谓线程同步.同步事件对象(XXXEvent)有两种行为: 1.等待.线程在此时会暂 ...
- React同构与极致的性能优化
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- .NET6中的await原理浅析
前言 看过不少关于 await 的原理的文章,也知道背后是编译器给转成了状态机实现的,但是具体是怎么完成的,回调又是如何衔接的,一直都没有搞清楚,这次下定决心把源码自己跑了下,终于豁然开朗了 本文的演 ...
- 28. 干货系列从零用Rust编写正反向代理,项目日志的源码实现
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,内网穿透,后续将实现websocket代理等,会将实现 ...
- CF1559D1. Mocha and Diana (Easy Version)
原题链接:1559D1. Mocha and Diana (Easy Version) 题意: 小明和小红各有一个具有\(n\)个结点的森林,现执行操作: 加一条边,使得两人的森林还是森林 小明加一条 ...
- 基于OpenAi通用特定领域的智能语音小助手
无穷尽的Q&A 钉钉...钉钉... 双双同学刚到工位,报销答疑群的消息就万马纷沓而来.她只能咧嘴无奈的摇摇头.水都还没有喝一口就开始"人工智能"的去回复.原本很阳光心情开 ...
- com.alibaba.nacos.api.exception.NacosException
具体异常如下: com.alibaba.nacos.api.exception.NacosException: <html><body><h1>Whitelabel ...
- [USACO2007NOVS] Cow Hurdles S
题目描述 Farmer John wants the cows to prepare for the county jumping competition, so Bessie and the gan ...
- 算法与数据结构——kpm算法