MemArts :高效解决存算分离架构中数据访问的组件
摘要:计算侧需要一个高速的缓存层来消除计算集群和OBS之间的数据访问鸿沟。为了解决这个问题,提出MemArts CC分布式客户端缓存。
本文分享自华为云社区《华为云全新缓存生态组件MemArts》,作者: MichaelYun。
公有云的基础设施都是基于存算分离的架构,即计算任务运行在计算集群的虚拟机(Virtual Machine, VM)上,而数据存储在远端的对象存储(Object Storage Service, OBS)集群中。但是,由于远端OBS的数据访问速度限制,VM上的计算任务经常需要等待数据而拖慢任务的执行。
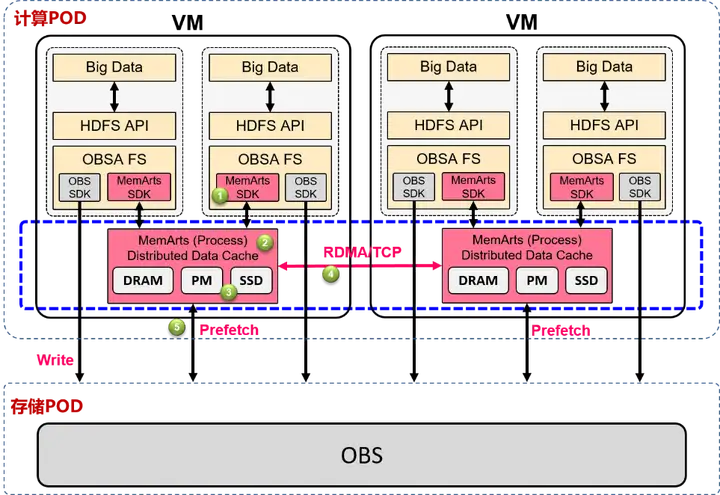
计算侧需要一个高速的缓存层来消除计算集群和OBS之间的数据访问鸿沟。为了解决这个问题,提出MemArts CC分布式客户端缓存。
设计简单性:在满足需求的前提下,尽量选择简单的设计实现方案。
解耦清晰:系统采用分层架构,层间划分清晰边界,保持整体架构稳定,同时整体架构能够解耦。各层之内的服务也需要清晰、明确、合理地解耦。
组件化原则:遵循内聚原则,划分组件,做到并行设计、独立开发、独立测试。
合理利用成熟部件:为加快开发速度和保持系统稳定,可能的情况下合理利用现有的成熟部件或加以改造,避免重复性“制造轮子”。
DevOps为导向:使用Microservices设计,并提高测试、运维自动化能力,保障可监控性,可调式性,以及快速定位问题的能力。
高可用性:分布式子系统必须能够处理网络、节点、进程故障挂起、超时场景,系统设计应当避免出现单点失效。
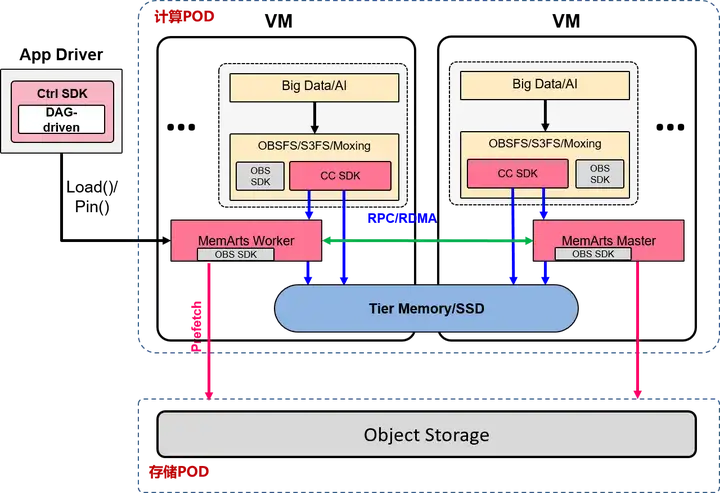
- 无NameNode去中心化架构
- 应用解耦,可对接ModelArts、 MRS、LakeHouse等多种应用
- 基于Tier Memory的高速缓存层
- 基于数据分片的多节点并发预取
- 极轻量的缓存数据一致性校验
- DAG-driven,提前加载数据
- Locality-aware任务调度
- RDMA网络和内存计算的未来扩展
MemArts :高效解决存算分离架构中数据访问的组件的更多相关文章
- ClickHouse 存算分离架构探索
背景 ClickHouse 作为开源 OLAP 引擎,因其出色的性能表现在大数据生态中得到了广泛的应用.区别于 Hadoop 生态组件通常依赖 HDFS 作为底层的数据存储,ClickHouse 使用 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- 存算分离实践:JuiceFS 在中国电信日均 PB 级数据场景的应用
01- 大数据运营的挑战 & 升级思考 大数据运营面临的挑战 中国电信大数据集群每日数据量庞大,单个业务单日量级可达到 PB 级别,且存在大量过期数据(冷数据).冗余数据,存储压力大:每个省公 ...
- 存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言 随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择.相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此 ...
- 腾讯云 CHDFS — 云端大数据存算分离的基石
随着网络性能提升,云端计算架构逐步向存算分离转变,AWS Aurora 率先在数据库领域实现了这个转变,大数据计算领域也迅速朝此方向演化. 存算分离在云端有明显优势,不但可以充分发挥弹性计算的灵活,同 ...
- 一文读懂GaussDB(for Mongo)的计算存储分离架构
摘要:IDC认为,目前阶段来看,企业亟待解决的是数字化能力提升,包括:与业务的深入结合能力:数据处理和挖掘能力:以及IT技术运营和管理能力.特别是数据处理和挖掘能力,因为数字化转型推进企业从以流程为核 ...
- 突破冯·诺依曼架构瓶颈!全球首款存算一体AI芯片诞生
过去70年,计算机一直遵循冯·诺依曼架构设计,运行时数据需要在处理器和内存之间来回传输. 随着时代发展,这一工作模式面临较大挑战:在人工智能等高并发计算场景中,数据来回传输会产生巨大的功耗:目前内存系 ...
- Flink不止于计算,存算一体才是未来
"伴随着实时化浪潮的发展和深化,Flink 已逐步演进为实时流处理的领军技术和事实标准.Flink 一方面持续优化其流计算核心能力,不断提高整个行业的流计算处理标准,另一方面沿着流批一体 ...
- 前后端分离架构:Web实现前后端分离,前后端解耦
一.前言 ”前后端分离“已经成为互联网项目开发的业界标杆,通过Tomcat+Ngnix(也可以中间有个Node.js),有效地进行解耦.并且前后端分离会为以后的大型分布式架构.弹性计算架构.微服务架构 ...
- 【转】前后端分离架构:web实现前后端分离,前后端解耦
一.前言 ”前后端分离“已经成为互联网项目开发的业界标杆,通过Tomcat+Ngnix(也可以中间有个Node.js),有效地进行解耦.并且前后端分离会为以后的大型分布式架构.弹性计算架构.微服务架构 ...
随机推荐
- 外层div随内层div高度自适应
首先说一下textarea的高度随文字的内容自适应,用div模拟textarea.直接看代码.其中 contenteditable="true"表示div可以编辑..主要是设置 o ...
- mapState、mapGetters、mapMutations、mapActions学习
https://next.vuex.vuejs.org/zh/guide/state.html#mapstate-%E8%BE%85%E5%8A%A9%E5%87%BD%E6%95%B0 https: ...
- 采药(lgP1048)
emmm 01 背包模板... 设 f[i] 表示背包容积为 i 时所得的最大价值. 则状态转移方程为 f[j] = f[j - w[i]] + c[i] . #include<bits/std ...
- kubeadm 添加master及node
1.添加master 新master服务器初始化 添加k8s源 $ cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] ...
- 标子查询优化和改写SQL案例
京华开发一哥们找我优化条报表SQL,反馈执行时间很慢需要 18s 才能出结果,安排. -- 原SQL SELECT 2 AS TYPE, to_char(a."create_time&quo ...
- STL set容器
set 使用 set 容器存储的各个键值对,要求键 key 和值 value 必须相等. 举个例子,如下有 2 组键值对数据: {<'a', 1>, <'b', 2>, < ...
- AtCoder F - Parenthesis Checking
原题链接:AtCoder F - Parenthesis Checking 一个全由\('('\)和\(')'\)构成的字符串,由以下两个操作: 1 l r交换字符串第\(l\)个和第\(r\)个字符 ...
- Vue3设计思想及响应式源码剖析
一.Vue3结构分析 1.Vue2与Vue3的对比 对TypeScript支持不友好(所有属性都放在了this对象上,难以推倒组件的数据类型) 大量的API挂载在Vue对象的原型上,难以实现TreeS ...
- 开源推荐,灵活多变功能强大的CMDB
一个完善的基础资源数据库是我们构建运维自动化上层应用的基础,所以构建CMDB系统成了有想法在DevOps运维自动化领域有所发展的企业离不开的重要一环,但受制于每家企业不同的内外部环境.资源配置以及管理 ...
- C#/.NET/.NET Core推荐学习书籍(已分类)
前言 古人云:"书中自有黄金屋,书中自有颜如玉",说明了书籍的重要性.作为程序员,我们需要不断学习以提升自己的核心竞争力.以下是一些优秀的C#/.NET/.NET Core相关学习 ...