8种ETL算法汇总大全!看完你就全明白了
摘要:ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中。目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
1 ETL算法概览
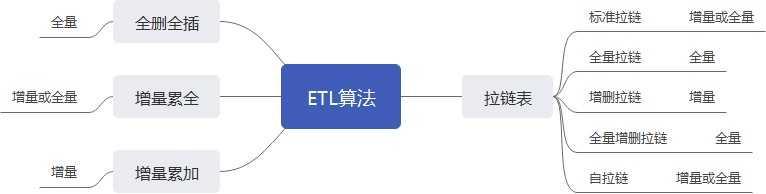
> 算法应用场景概览
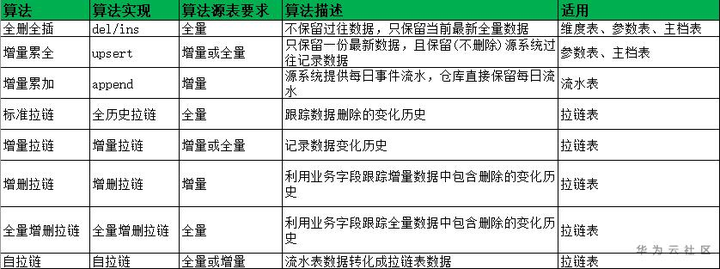
以上共计累积了8种ETL算法,其中主要分成4大类,增量累加、拉链算法是更符合数据仓库历史数据追踪的算法,但现实中基于业务及性能考虑,往往存在全删全插、增量累全算法的数据表应用。
2 全删全插模型
即Delete/Insert实现逻辑;
> 应用场景
主要应用在维表、参数表、主档表加载上,即适合源表是全量数据表,该数据表业务逻辑只需保存当前最新全量数据,不需跟踪过往历史信息。
> 算法实现逻辑
1.清空目标表;
2.源表全量插入;
> ETL代码原型 -- 1. 清理目标表
TRUNCATE TABLE <目标表>; -- 2. 全量插入
INSERT INTO <目标表> (字段***)
SELECT 字段***
FROM <源表>
***JOIN <关联数据>
WHERE ***;
3 增量累全模型
即Upsert实现逻辑;
> 应用场景
主要应用在参数表、主档表加载上,即源表可以是增量或全量数据表,目标表始终最新最全记录。
> 算法实现逻辑
1.利用PK主键比对;
2.目标表和源表PK一致的变化记录,更新目标表;
3.源表存在但目标表不存在,直接插入;
> ETL代码原型
-- 1. 生成加工源表
Create temp Table <临时表> ***;
INSERT INTO <临时表> (字段***)
SELECT 字段***
FROM <源表>
***JOIN <关联数据>
WHERE ***
; -- 2. 可利用Merge Into实现累全能力,当前也可以采用分步Delete/Insert或Update/Insert操作
Merge INTO <目标表> As T1 (字段***)
Using <临时表> as S1
on (***PK***)
when Matched then
update set Colx = S1.Colx ***
when Not Matched then
INSERT (字段***) values (字段*** )
;
4 增量累加模型
即Append实现逻辑;
> 应用场景
主要应用在流水表加载上,即每日产生的流水、事件数据,追加到目标表中保留全历史数据。流水表、快照表、统计分析表等均是通过该逻辑实现。
> 算法实现逻辑
1.源表直接插入目标表;
> ETL代码原型
-- 1.插入目标表
INSERT INTO <目标表> (字段***)
SELECT 字段***
FROM <源表>
***JOIN <关联数据>
WHERE ***;
5 全历史拉链模型
> 拉链表背景知识
概念
拉链表是一张至少存在PK字段、跟踪变化的字段、开链日期、闭链日期组成的数据仓库ETL数据表;
益处
根据开链、闭链日期可以快速提取对应日期有效数据;
对于跟踪源系统非事件流水类表数据,拉链算法发挥越大作用,源业务系统通常每日变化数据有限,通过拉链加工可以大大降低每日打快照带来的空间开销,且不损失数据变化历史;
示例,提取指定日期有效数据
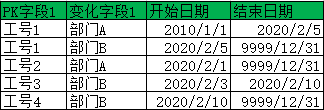
提取2020年2月5日当日有效数据
Select *
From <目标表>
Where 开始日期<=date'2020-02-05'
And 结束日期 >date'2020-02-05';
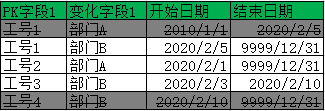
最终提取到数据:
> 应用场景
全历史拉链,跟踪源表全量变化历史,若源表记录不存在,则说明数据闭链;根据PK新拉一条有效记录。
> 算法实现逻辑
1.提取当前有效记录;
2.提取当日源系统最新数据;
3.根据PK字段比对当前有效记录与最新源表,更新目标表当前有效记录,进行闭链操作;
4.根据全字段比对最新源表与当前有效记录,插入目标表;
> ETL代码原型
-- 1. 提取当前有效记录
Insert into <临时表-开链-pre> (不含开闭链字段***)
Select 不含开闭链字段***
From <目标表>
Where 结束日期 =date'<最大日期>';
;
-- 2. 提取当日源系统最新数据
<源表临时表-cur>
-- 3 今天全部开链的数据,即包含今天全新插入、数据发生变化的记录
Insert Into <临时表-增量-ins>
Select 不含开闭链字段***
From <源表临时表-cur>
where (不含开闭链字段***) not in
(Select 不含开闭链字段***
From <临时表-开链-pre>
);
-- 4 今天需要闭链的数据,即今天发生变化的记录
Insert into <临时表-增量-upd>
Select 不含开闭链字段***,开始时间
From <临时表-开链-pre>
where (不含开闭链字段***) not in
(Select 不含开闭链字段***
From <临时表-开链-cur>
);
-- 5 更新闭链数据,即历史记录闭链(删除-插入替代更新)
DELETE FROM <目标表>
WHERE (PK***) IN
(Select PK*** From <临时表-增量-upd>)
AND 结束日期=date'<最大日期>';
INSERT INTO <目标表>
(不含开闭链字段***,开始时间,结束日期)
Select 不含开闭链字段***,开始时间,date'<数据日期>'
From <临时表-增量-upd>;
-- 6 插入开链数据,即当日新增记录
INSERT INTO <目标表> .
(不含开闭链字段***,开始时间,结束日期)
Select 不含开闭链字段***,date'<数据日期>',date'<最大日期>'
From <临时表-增量-ins>;
6 增量拉链模型
> 应用场景
增量拉链,目的是追踪数据增量变化历史,根据PK比对新拉一条开链数据;
> 算法实现逻辑
1.提取上日开链数据;
2.PK相同变化记录,关闭旧记录链,开启新记录链;
3.PK不同,源表存在,新增开链记录
> ETL代码原型
-- 1. 提取当前有效记录
Insert into <临时表-开链-pre> (不含开闭链字段***)
Select 不含开闭链字段***
From <目标表>
Where 结束日期 =date'<最大日期>';
-- 2. 提取当日源系统增量记录
<源表临时表-cur>
-- 3. 提取当日源系统新增记录
Insert into <临时表-增量-ins>
Select 不含开闭链字段***
From <临时表-开链-cur>
where (***PK***) not in
(select ***PK*** from <临时表-开链-pre>);
-- 4. 提取当日源系统历史变化记录
Insert into <临时表-增量-upd>
Select 不含开闭链字段***
From <临时表-开链-cur>
inner join <临时表-开链-pre>
on (***PK 等值***)
where (***变化字段 非等值***);
-- 5. 更新历史变化记录,关闭历史旧链,开启新链
update <目标表> AS T1
SET <***变化字段 S1赋值***>,结束日期 = date'<数据日期>'
FROM <临时表-增量-upd> AS S1
WHERE ( <***PK 等值***> )
AND T1.结束日期 =date'<最大日期>'
;
INSERT INTO <目标表>
(不含开闭链字段***,开始时间,结束日期)
SELECT 不含开闭链字段***,date'<数据日期>',date'<最大日期>'
FROM <临时表-增量-upd>;
-- 6. 插入全新开链数据
INSERT INTO <目标表>
(不含开闭链字段***,开始时间,结束日期)
SELECT 不含开闭链字段***,date'<数据日期>',date'<最大日期>'
FROM <临时表-增量-ins>;
7 增删拉链模型
> 应用场景
主要是利用业务字段跟踪增量数据中包含删除的变化历史。
> 算法实现逻辑
1.提取上日开链数据;
2.提取源表非删除记录;
3.PK相同变化记录,关闭旧记录链,开启新记录链;
4.PK比对,源表存在,新增开链记录;
5.提取源表删除记录;
6.PK比对,旧开链记录存在,关闭旧记录链;
> ETL代码原型
-- 1. 清理目标表《待续...》
TRUNCATE TABLE <目标表>; -- 2. 全量插入
INSERT INTO <目标表> (字段***)
SELECT 字段***
FROM <源表>
***JOIN <关联数据>
WHERE ***;
8 全量增删拉链模型
> 应用场景
主要是利用业务字段跟踪全量数据中包含删除的变化历史。
> 算法实现逻辑
1.提取上日开链数据;
2.提取源表非删除记录;
3.PK相同变化记录,关闭旧记录链,开启新记录链;
4.PK比对,源表存在,新增开链记录;
5.提取源表删除记录;
6.PK比对,旧开链记录存在,关闭旧记录链;
7.PK比对,提取旧开链存在但源表不存在记录,关闭旧记录链;
> ETL代码原型
-- 1. 清理目标表,《待续...》
TRUNCATE TABLE <目标表>; -- 2. 全量插入
INSERT INTO <目标表> (字段***)
SELECT 字段***
FROM <源表>
***JOIN <关联数据>
WHERE ***;
9 自拉链模型
> 应用场景
主要将流水表数据转化成拉链表数据。
> 算法实现逻辑
借助源表业务日期字段,和目标表开链、闭链日期比对,首尾相接,拉出全历史拉链;
> ETL代码原型
-- 1. 清理目标表,《待续...》
TRUNCATE TABLE <目标表>; -- 2. 全量插入
INSERT INTO <目标表> (字段***)
SELECT 字段***
FROM <源表>
***JOIN <关联数据>
WHERE ***;
10 其它说明
1.根据数据仓库最佳实践,所有数据表通常还会包含一些控制字段,即插入日期、更新日期、更新源头字段,这样对于数据变化敏感的数据仓库,可以进一步追踪数据变化历史;
2.ETL算法本身是为了更好服务于数据加工过程,实际业务实现过程中,并不局限于传统算法,即涉及到更多适应业务的自定义的ETL算法。
8种ETL算法汇总大全!看完你就全明白了的更多相关文章
- Linux中find命令用法全汇总,看完就没有不会用的!
Linux中find命令用法全汇总,看完就没有不会用的! 中琦2513 马哥Linux运维 2017-04-10 糖豆贴心提醒,本文阅读时间7分钟 Linux 查找命令是Linux系统中最重要和最 ...
- ETL拉链算法汇总大全
拉链算法总结大全: 一.0610算法(追加) 1.删除仓库表的载入日期是本次载入日期的数据,以支持重跑 delete from xxx where start_dt >=$tx_date; 2. ...
- 还不懂Redis?看完这个故事就明白了!
我是Redis 你好,我是Redis,一个叫Antirez的男人把我带到了这个世界上. 说起我的诞生,跟关系数据库MySQL还挺有渊源的. 在我还没来到这个世界上的时候,MySQL过的很辛苦,互联网发 ...
- BIOS设置图解教程-看完就没有不明白的了
BIOS(基本输入/输出系统)是被固化在计算机CMOS RAM芯片中的一组程序,为计算机提供最初的.最直接的硬件控制.BIOS主要有两类∶AWARD BIOS和AMI BIOS.正确设置BIOS可大大 ...
- 【CSS】271- RGB、HSL、Hex网页色彩,看完这篇全懂了
作者:CSS可乐 http://csscoke.com/2015/01/01/rgb-hsl-hex/ 网页使用到的色彩标示方法中,从古早时期大家都在用的16进位码(#000000).RGB色值标示. ...
- 面试总被问到HTTP缓存机制及原理?看完你就彻底明白了
前言 Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系库中的一个基础环节,同时对于有志成为前端架构师的同学来说是必备的知识技能. 但是对于很多前端 ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- 史上最全单链表的增删改查反转等操作汇总以及5种排序算法(C语言)
目录 1.准备工作 2.创建链表 3.打印链表 4.在元素后面插入元素 5.在元素前面增加元素 6.删除链表元素,要注意删除链表尾还是链表头 7.根据传入的数值查询链表 8.修改链表元素 9.求链表长 ...
- JavaScript 数据结构与算法之美 - 十大经典排序算法汇总(图文并茂)
1. 前言 算法为王. 想学好前端,先练好内功,内功不行,就算招式练的再花哨,终究成不了高手:只有内功深厚者,前端之路才会走得更远. 笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 ...
- 看完这篇,保证让你真正明白:分布式系统的CAP理论、CAP如何三选二
引言 CAP 理论,相信很多人都听过,它是指: 一个分布式系统最多只能同时满足一致性(Consistency).可用性(Availability)和分区容错性(Partition tolerance) ...
随机推荐
- IEDA-Maven项目开发步骤
1. 打开IDEA 界面,选择"New Project" 2. 输入项目名称和基本信息 输入项目名称.选择存放路径.JDK版本.以及GroupId.ArtifactId. Grou ...
- 【KMP】border 题解
题目描述 输入 输出 样例输入 abaabaa 样例输出 17 样例解释: f[2][a] = 1 f[3][a] = 1 f[4][a] = 1 f[4][b] = 2 f[5][a] = 1 f[ ...
- html5学习内容-6(flex)
弹性布局–flex (一)视口单位主要包括以下4个: vw:1vw等于视口宽度的1% vh:1vh等于视口高度的1% vmin:选取vm和vh中最小的那个 vmax:选取vm和vh中最大的那个 常用于 ...
- Apache Hudi Timeline:支持 ACID 事务的基础
Apache Hudi 维护在给定表上执行的所有操作的Timeline(时间线),以支持以符合 ACID 的方式高效检索读取查询的数据. 在写入和表服务期间也会不断查阅时间线,这是表正常运行的关键. ...
- influxdb 连续查询使用总结
转载请注明出处: 1.定义: InfluxDB 连续查询(Continuous Query)是一种自动化查询类型,该查询会根据定义的时间间隔定期运行,并将结果存储在新的目标测量中.这样的查询通常用于处 ...
- idea的mybatis插件free mybatis plugin(或 Free MyBatis Tool),很好用
为大家推荐一个idea的mybatis插件----free mybatis plugin(或 Free MyBatis Tool),很好用(个人觉得free mybatis plugin更好用一点,可 ...
- 文心一言 VS 讯飞星火 VS chatgpt (133)-- 算法导论11.2 5题
五.用go语言,假设将一个具有n个关键字的集合存储到一个大小为 m 的散列表中.试说明如果这些关键字均源于全域U,且|U|>nm,则U 中还有一个大小为n 的子集,其由散列到同一槽位中的所有关键 ...
- 如何优雅使用 vuex
大纲 本文内容更多的是讲讲使用 vuex 的一些心得想法,所以大概会讲述下面这些点: Q1:我为什么会想使用 vuex 来管理数据状态交互? Q2:使用 vuex 框架有哪些缺点或者说副作用? Q3: ...
- The 2021 ICPC Asia Regionals Online Contest (II) L Euler Function
思路来源:Zed222 如果一个区间里的数都有这个质数,那么我们就直接利用性质\(\phi(n * p) = \phi(n) * p\),如果没有这个区间中有没有这个质数的,那么就退化到了单点修改,当 ...
- [AI]人工智能早就可以拥有有大量的初级意识
引子 意识是人类最基本而神秘的经验之一.在探索意识的本质时,我们需要建立清晰的概念分类体系,以免将它混同于其他概念而无法深入研究. 本文旨在阐述人类意识可能包含的两个层面:初级意识和高级意识,并明确区 ...