[转帖]记录一则enq: TX - row lock contention的分析过程
https://www.cnblogs.com/jyzhao/p/8628184.html
故障描述:与客户沟通,初步确认故障范围大概是在上午的8:30-10:30之间,反应故障现象是Tomcat的连接数满导致应用无法连接,数据库alert中无明显报错,需要协助排查原因。
1.导入包含故障时刻的数据
为了便于后续分析,我向客户索要了从昨天下午13:00到今天18:00的awrdump,导入到自己的实验环境进行分析。
生产环境导出awrdump:
@?/rdbms/admin/awrextr
测试环境导入awrdump:
SYS@jyzhao1 >select * from dba_directories;
SYS@jyzhao1 >create directory jy as '/home/oracle/awrdump';
SYS@jyzhao1 >select * from dba_directories;
SYS@jyzhao1 >!mkdir -p /home/oracle/awrdump
SYS@jyzhao1 >@?/rdbms/admin/awrload
省略部分输出..
... Dropping AWR_STAGE user
End of AWR Load
2.创建m_ash表,明确故障时刻
创建m_ash表:
--create table
create table m_ash20180322 as select * from dba_hist_active_sess_history where dbid=&dbid;
输入生产库对应的dbid,完成创建分析表。
select to_char(sample_time, 'yyyy-mm-dd hh24:mi'), count(1)
FROM m_ash20180322
group by to_char(sample_time, 'yyyy-mm-dd hh24:mi')
order by 1;
根据生成的数据生成折线图如下: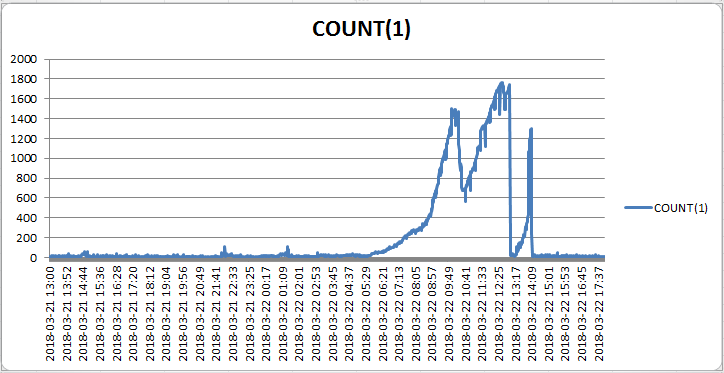
可以从图中明确故障时刻,即在10:00、12:30、14:10这三个时刻会话都明显上升(积压),看来客户的反馈时间点并没有包含所有异常时刻。
另外,引用下maclean的诊断脚本,可以看到核心意思差不多,只是进一步将instance_number区分开细化:
--验证导出的ASH时间范围:
select
t.dbid, t.instance_number, min(sample_time), max(sample_time), count(*) session_count
from m_ash20180322 t
group by t.dbid, t.instance_number
order by dbid, instance_number;
--确认问题发生的精确时间范围:
select
dbid, instance_number, sample_id, sample_time, count(*) session_count
from m_ash20180322 t
group by dbid, instance_number, sample_id, sample_time
order by dbid, instance_number, sample_time;
3.确定异常时刻的top n event
确定每个采样点的top n event,下面也是参考maclean的脚本。 比如我这里以2018-03-22 09:59:00 - 2018-03-22 10:00:00为例:
select t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.event,
t.session_state,
t.c session_count
from (select t.*,
rank() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select /*+ parallel 8 */
t.*,
count(*) over(partition by dbid, instance_number, sample_time, event) c,
row_number() over(partition by dbid, instance_number, sample_time, event order by 1) r1
from dba_hist_active_sess_history t
where sample_time >
to_timestamp('2018-03-22 09:59:00',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('2018-03-22 10:00:00',
'yyyy-mm-dd hh24:mi:ss')
) t
where r1 = 1) t
where r < 3
order by dbid, instance_number, sample_time, r;

其他异常时刻,输入对应的变量值:
select t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.event,
t.session_state,
t.c session_count
from (select t.*,
rank() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select /*+ parallel 8 */
t.*,
count(*) over(partition by dbid, instance_number, sample_time, event) c,
row_number() over(partition by dbid, instance_number, sample_time, event order by 1) r1
from dba_hist_active_sess_history t
where sample_time >
to_timestamp('&begin_sample_time',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('&end_sample_time',
'yyyy-mm-dd hh24:mi:ss')
) t
where r1 = 1) t
where r < 3
order by dbid, instance_number, sample_time, r;
2018-03-22 12:29:00
2018-03-22 12:30:00
2018-03-22 14:09:00
2018-03-22 14:10:00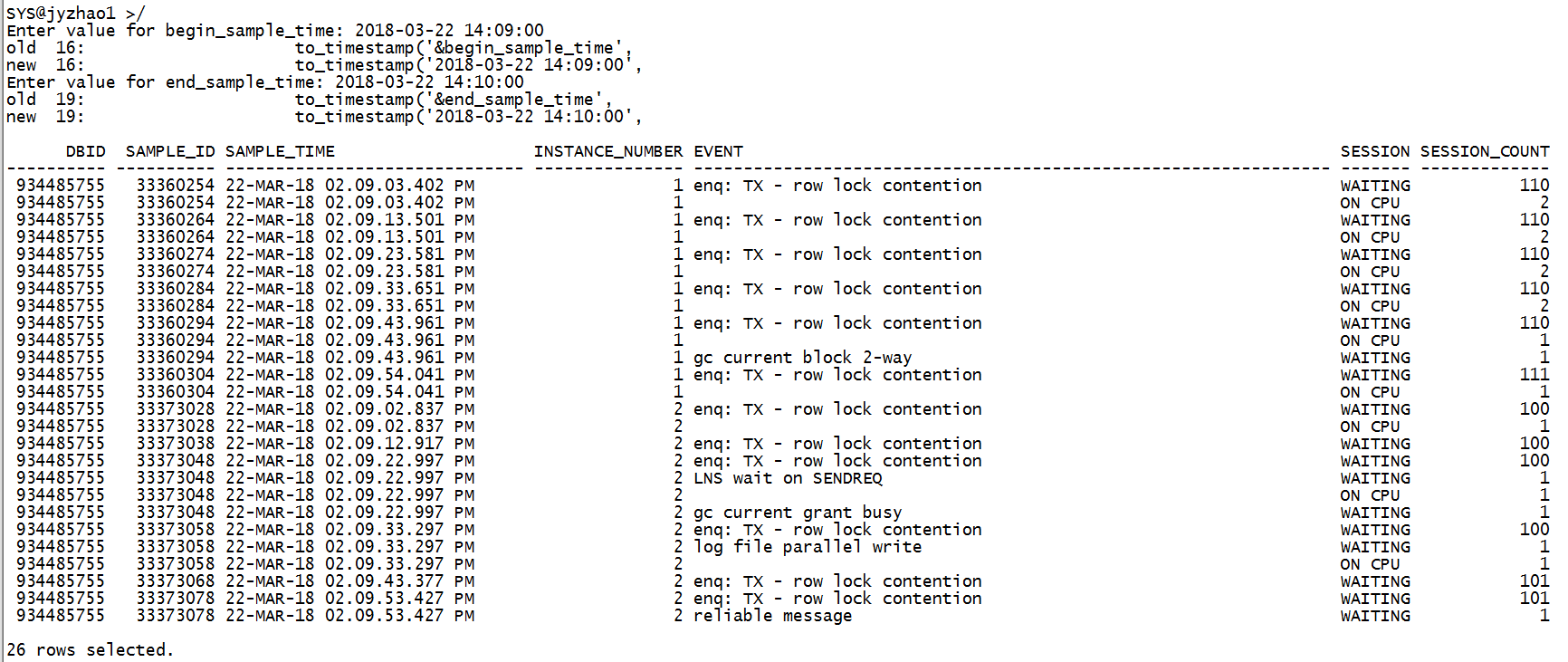
综上,3个连接数堆积的异常时刻TOP event都是 “enq: TX - row lock contention”。
4.确定最终的top holder
使用maclean的脚本,观察每个采样点的等待链:
select
level lv,
connect_by_isleaf isleaf,
connect_by_iscycle iscycle,
t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.session_id,
t.sql_id,
t.session_type,
t.event,
t.session_state,
t.blocking_inst_id,
t.blocking_session,
t.blocking_session_status
from m_ash20180322 t
where sample_time >
to_timestamp('2018-03-22 09:59:00',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('2018-03-22 10:00:00',
'yyyy-mm-dd hh24:mi:ss')
start with blocking_session is not null
connect by nocycle
prior dbid = dbid
and prior sample_time = sample_time
/*and ((prior sample_time) - sample_time between interval '-1'
second and interval '1' second)*/
and prior blocking_inst_id = instance_number
and prior blocking_session = session_id
and prior blocking_session_serial# = session_serial#
order siblings by dbid, sample_time;
结果如下: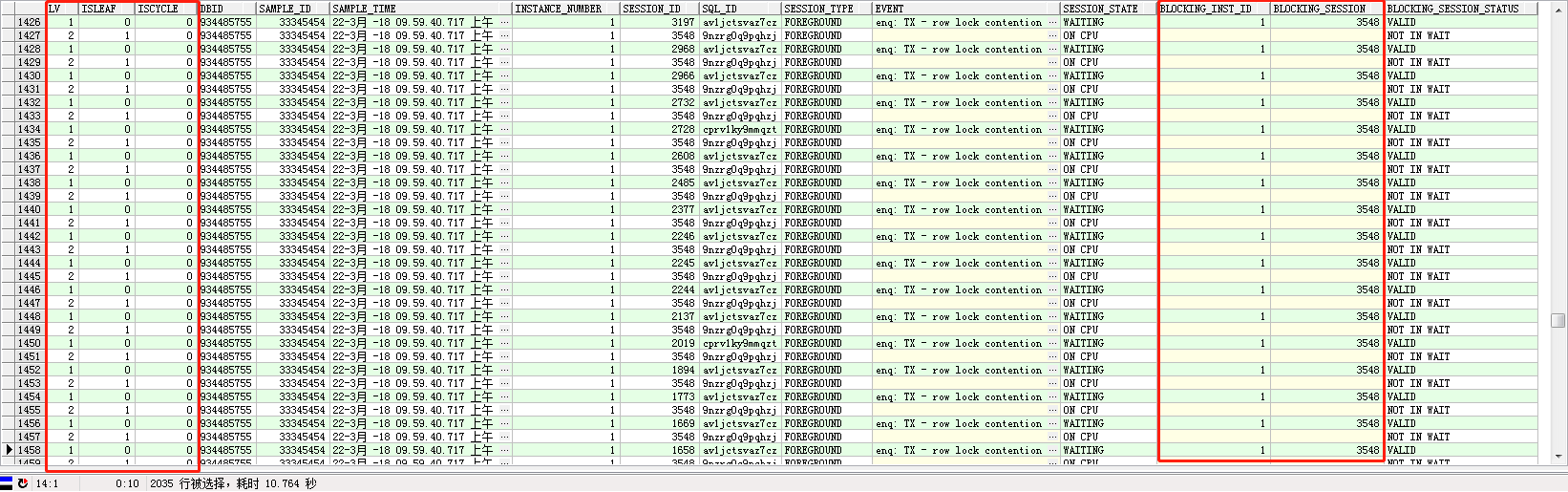
进一步筛选,将isleaf=1的叶(top holder)找出来:
--基于上一步的原理来找出每个采样点的最终top holder:
select t.lv,
t.iscycle,
t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.session_id,
t.sql_id,
t.session_type,
t.event,
t.seq#,
t.session_state,
t.blocking_inst_id,
t.blocking_session,
t.blocking_session_status,
t.c blocking_session_count
from (select t.*,
row_number() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select t.*,
count(*) over(partition by dbid, instance_number, sample_time, session_id) c,
row_number() over(partition by dbid, instance_number, sample_time, session_id order by 1) r1
from (select /*+ parallel 8 */
level lv,
connect_by_isleaf isleaf,
connect_by_iscycle iscycle,
t.*
from m_ash20180322 t
where sample_time >
to_timestamp('2018-03-22 09:59:00',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('2018-03-22 10:00:00',
'yyyy-mm-dd hh24:mi:ss')
start with blocking_session is not null
connect by nocycle
prior dbid = dbid
and prior sample_time = sample_time
/*and ((prior sample_time) - sample_time between interval '-1'
second and interval '1' second)*/
and prior blocking_inst_id = instance_number
and prior blocking_session = session_id
and prior
blocking_session_serial# = session_serial#) t
where t.isleaf = 1) t
where r1 = 1) t
where r < 3
order by dbid, sample_time, r;
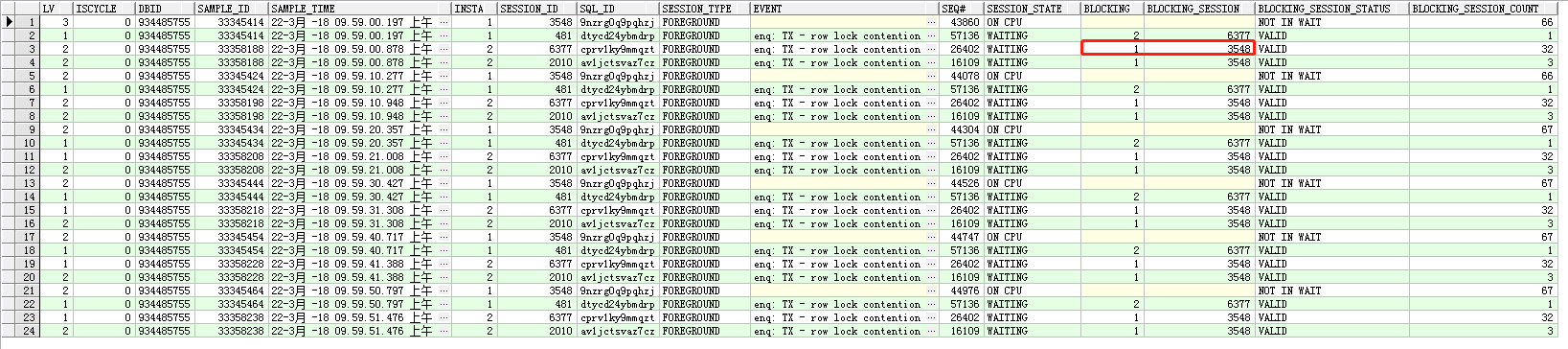
对其他异常时段进行分析:
2018-03-22 12:29:00
2018-03-22 12:30:00
2018-03-22 14:09:00
2018-03-22 14:10:00
-- top holder: DIY sample_time
select t.lv,
t.iscycle,
t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.session_id,
t.sql_id,
t.session_type,
t.event,
t.seq#,
t.session_state,
t.blocking_inst_id,
t.blocking_session,
t.blocking_session_status,
t.c blocking_session_count
from (select t.*,
row_number() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select t.*,
count(*) over(partition by dbid, instance_number, sample_time, session_id) c,
row_number() over(partition by dbid, instance_number, sample_time, session_id order by 1) r1
from (select /*+ parallel 8 */
level lv,
connect_by_isleaf isleaf,
connect_by_iscycle iscycle,
t.*
from m_ash20180322 t
where sample_time >
to_timestamp('&begin_sample_time',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('&end_sample_time',
'yyyy-mm-dd hh24:mi:ss')
start with blocking_session is not null
connect by nocycle
prior dbid = dbid
and prior sample_time = sample_time
/*and ((prior sample_time) - sample_time between interval '-1'
second and interval '1' second)*/
and prior blocking_inst_id = instance_number
and prior blocking_session = session_id
and prior
blocking_session_serial# = session_serial#) t
where t.isleaf = 1) t
where r1 = 1) t
where r < 3
order by dbid, sample_time, r;
发现所有的异常时刻最终阻塞都是实例1的sid为3548的session,不再赘述。
5.总结
从第四步可以看到,top holder都是实例1,会话3548. 比如可以看到实例1的481会话被实例2的6377会话阻塞,然后实例2的6377会话又被实例1的3548会话阻塞。 通过sql_id可以查询到sql文本:
select * from dba_hist_sqltext where sql_id = '&sql_id';
可以看到实例1的3548会话当前正在执行的SQL只是一个查询语句,当前会话状态是ON CPU,所以推测该会话之前有DML的事物未提交导致阻塞。
去查询该会话的DML操作时,也有update和insert操作,但是update操作已经无法找到对应SQL文本。
select t.event, t.*
from m_ash20180322 t
where instance_number = 1
and session_id = 3548
and t.sql_opname <> 'SELECT';
其实从ash也可以看到关于3548阻塞的信息,甚至从addm的建议中也会有类似建议:
Rationale
The session with ID 3548 and serial number 8795 in instance number 1 was
the blocking session responsible for 52% of this recommendation's
benefit.
Rationale
The session with ID 6377 and serial number 30023 in instance number 2
was the blocking session responsible for 47% of this recommendation's
benefit.
只不过我们从底层查询,可以看到6377实际也是被3548阻塞,找到最终阻塞者。
btw,从导入的awrdump中,除了可以取awr外,同样可以支持取awrsqrpi和addmrpti以及ashrpti,非常方便:
SYS@jyzhao1 >@?/rdbms/admin/awrrpti
SYS@jyzhao1 >@?/rdbms/admin/awrsqrpi
SYS@jyzhao1 >@?/rdbms/admin/ashrpti
SYS@jyzhao1 >@?/rdbms/admin/addmrpti
6.reference
- http://feed.askmaclean.com/archives/dba_hist_active_sess_history.html
[转帖]记录一则enq: TX - row lock contention的分析过程的更多相关文章
- 记录一则enq: TX - row lock contention的分析过程
故障描述:与客户沟通,初步确认故障范围大概是在上午的8:30-10:30之间,反应故障现象是Tomcat的连接数满导致应用无法连接,数据库alert中无明显报错,需要协助排查原因. 1.导入包含故障时 ...
- 解决一则enq: TX – row lock contention的性能故障
上周二早上,收到项目组的一封邮件: 早上联代以下时间点用户有反馈EDI导入"假死",我们跟踪了EDI导入服务,服务是正常在跑,可能是处理的慢所以用户感觉是"假死" ...
- ORACLE等待事件:enq: TX - row lock contention
enq: TX - row lock contention等待事件,这个是数据库里面一个比较常见的等待事件.enq是enqueue的缩写,它是一种保护共享资源的锁定机制,一个排队机制,先进先出(FIF ...
- Tuning “enq:TX – row lock contention” events
enq是一种保护共享资源的锁定机制,一个排队机制 排它机制从一个事务的第一次改变直到rollback or commit 结束这个事务, TX等待mode是6,当一个session 在一个表的行级锁定 ...
- AWR之-enq TX - row lock contention的性能故障-转
1 对这一个小时进行AWR的收集和分析,首先,从报告头中看到DB Time达到近500分钟,(DB Time)/Elapsed=8,这个比值偏高: Snap Id Snap Time Sessio ...
- enq: TX - row lock contention故障处理一则
一个非常easy的问题,之所以让我对这个问题进行总结.一是由于没我想象的简单,在处理的过程中遇到了一些磕磕碰碰,甚至绕了一些弯路.二是引发了我对故障处理时的一些思考. 6月19日,下午5点左右.数据库 ...
- 记一则update 发生enq: TX - row lock contention 的处理方法
根据事后在虚拟机中复现客户现场发生的情况,做一次记录(简化部分过程,原理不变) 客户端1执行update语句 SQL> select * from test; ID NAME --------- ...
- ORACLE AWR结合ASH诊断分析enq: TX - row lock contention
公司用户反馈一系统在14:00~15:00(2016-08-16)这个时间段反应比较慢,于是生成了这个时间段的AWR报告, 如上所示,通过Elapsed Time和DB Time对比分析,可以看出在这 ...
- 大表建立索引引发enq: TX - row lock contention等待
今天要给一张日志表(6000w数据)建立索引,导致生产系统行锁部分功能卡住 create index idx_tb_cid on tb_login_log(user_id); 开始执行后大概花费了20 ...
- enq: TX - row lock contention 参数P1,P2,P3说明
enq: TX - row lock contention三个参数,例如,下面的等待事件 * P1 = name|mode <<<<<<< ...
随机推荐
- Elasticsearch对接MinIO存储Snapshot快照
服务器配置 MinIO集群节点(4节点) IP 节点1 miniotest1.ip.tp-link.com 172.29.145.80 生产环境需要增加一个Nginx负载均衡前端用于ELK对接,此处直 ...
- 【OpenVINO 】在 MacOS 上编译 OpenVINO C++ 项目
前言 英特尔公司发行的模型部署工具OpenVINO模型部署套件,可以实现在不同系统环境下运行,且发布的OpenVINO 2023最新版目前已经支持MacOS系统并同时支持在苹果M系列芯片上部署模型.在 ...
- CodeForces 808G Anthem of Berland 前缀函数 KMP DP
原题链接 题意 第一行给我们一串长为s,只包含小写字母与问号的字符串A,第二行给我们一个长为t只有小写字母的字符串B, 同时满足 $ s * t \le 1e7 $ 我们可以把问号变成任意的字母,我们 ...
- Cesium案例解析(七)——Layers在线地图服务
目录 1. 概述 2. 案例 2.1. Blue Marble 2.2. ArcGIS地形 2.3. Cesium地形 2.4. Natural Earth II 2.5. Earth at Nigh ...
- 使用LiteOS Studio图形化查看LiteOS在STM32上运行的奥秘
摘要:本文带来基于LiteOS一站式开发工具LiteOS Studio,通过单步调试,来动态分析LiteOS的启动流程. 编者按:在LiteOS大揭秘系列,我们和读者们分享了<LiteOS是怎么 ...
- 释放千行百业数据价值,华为云DAYU有一套
摘要:结合数字化转型中行业面临的挑战及产品解决方案解读数据使能服务DAYU. 大禹(DAYU)治水是一个有美好寓意的故事,大禹汲取了父亲治水的经验教训,总结出一套行之有效的治水方法,对洪水进行治理疏导 ...
- Jenkins Pipeline 流水线 - 添加节点 使用代理
Jenkins 安装在 Windows 上 Docker 在Linux 上 流程 将 Docker 在 Jenkins 节点中维护 Pipeline 中指定某些阶段使用哪个节点 添加节点 Checki ...
- Winform 嵌入html,数据交互
Winform 嵌入html,数据交互,将JS中的数据等传给winform 点击浏览器中的按钮,触发 Winform 中的方法 https://github.com/cefsharp/CefSharp ...
- Java 网络编程 —— 异步通道和异步运算结果
从 JDK7 开始,引入了表示异步通道的 AsynchronousSockerChannel 类和 AsynchronousServerSocketChannel 类,这两个类的作用与 SocketC ...
- JVM学习-自动内存管理
文章原文:https://gaoyubo.cn/blogs/6997cf1f.html 一.运行时数据区 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域 ...