[转帖]OceanBase实验4:迁移MySQL数据到OceanBase集群
服务器环境
1)12核48G,操作系统为centos 7.9系统,单节点三副本1-1-1集群。
2)源MySQL数据库:与OceanBase同一台服务器,版本为MySQL 5.7。
1、使用 mysqldump 迁移数据
1)mysql源数据库信息

2)导出表结构
mysqldump -h 127.0.0.1 -u root -p -d lianghe_db > lianghe_db.sql(如在/etc/my.conf中已配置mysqldump登录信息则使用mysqldump -d lianghe_db > lianghe_db.sql即可。)
3)导出一张表数据
mysqldump –h 127.0.0.1 –u root –p –t lianghe_db –tables area > area.sql(如在/etc/my.conf中已配置mysqldump登录信息则使用mysqldump -t lianghe_db --tables area > area.sql即可。)

4)使用obclient连接oceanbase数据库
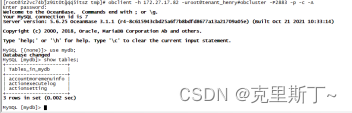
5)导入表结构
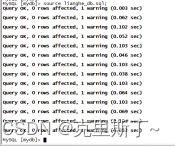
6)导入表数据

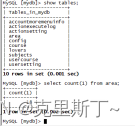
导入后的表及数据
2、使用 Datax 配置数据迁移
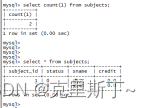
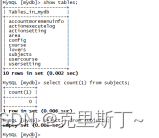
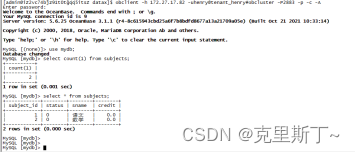
1)迁移前mysql和oceanbase数据
mysql
oceanbase
2)安装datax
下载 DataX 工具
https://github.com/alibaba/DataX
或http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
直接解压并删除隐藏文件:
tar -xf datax.tar.gz
find ./datax/plugin -name ".*" | xargs rm -f
3)检查java环境

4)生成配置文件
python ./datax/bin/datax.py -r mysqlreader -w oceanbasev10writer > ./datax/job/MySQL2OeanBase.json

5)修改配置文件
vi ./datax/job/MySQL2OeanBase.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/lianghe_db?useUnicode=true&characterEncoding=utf8"],
"table": ["subjects"]
}
],
"password": "P@ssw0rd123",
"username": "root",
"where": ""
}
},
"writer": {
"name": "oceanbasev10writer",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "||_dsc_ob10_dsc_||obcluster:tenant_henry||_dsc_ob10_dsc_||jdbc:mysql://127.0.0.1:2883/mydb?useUnicode=true&characterEncoding=utf8",
"table": ["subjects"]
}
],
"obWriteMode": "",
"password": "mydb",
"username": "henry"
}
}
}
],
"setting": {
"speed": {
"channel": "8"
}
}
}
}
在oceanbasewriter的配置里注意jdbcUrl的第二参数“obcluster:tenant_henry”是“集群名:租户名”。另外,各个配置项注意用引号包起来。
6)执行迁移
python bin/datax.py job/MySQL2OeanBase.json
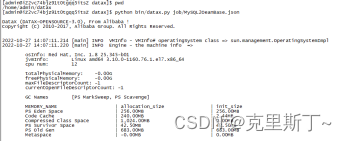
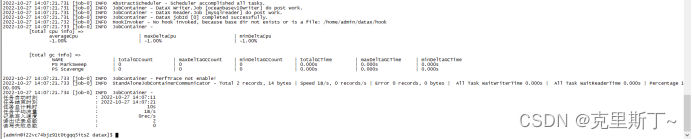
7)查看结果
迁移成功。
3、问题
1)因在/etc/my.conf中已配置有mysqldump登录信息(root和password),使用mysqldump导出数据时,若有登录参数(如:mysqldump -uroot -p ...)会报错,此时mysqldump命令不用附加登录参数,直接加数据库名作参数即可。
2)第一节执行source xxx.sql时,
You have an error in your SQL syntax; check the manual that corresponds to your OceanBase version for the right syntax to use near ‘--’ at line 1
数据文件中有--注释信息,导入到OceanBase会报错,可以忽略,并不影响数据导入。我对源文件作了编辑,删除了这些内容。
其它类似如‘ENABLE KEYS */’、‘DISABLE KEYS */’等报错,可以忽略,并不影响数据导入。我对源文件作了编辑,删除了这些内容。
变量 SQL_NOTES,DEFINER 语句等 OceanBase MYSQL 会不支持,但是不影响,需要替换掉其中部分。
[转帖]OceanBase实验4:迁移MySQL数据到OceanBase集群的更多相关文章
- 迁移mysql数据到oracle上
转自:http://www.cnblogs.com/Warmsunshine/p/4651283.html 我是生成的文件里面的master.sql里面的sql,一个一个拷出来的. 迁移mysql数据 ...
- Linux Centos 迁移Mysql 数据位置
Linux Centos 迁移Mysql 数据位置 由于业务量增加导致安装在系统盘(20G)磁盘空间被占满了, 现在进行数据库的迁移. Mysql 是通过 yum 安装的. Centos6.5Mysq ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- 1 构建Mysql+heartbeat+DRBD+LVS集群应用系统系列之DRBD的搭建
preface 近来公司利润上升,购买了10几台服务器,趁此机会,把mysql的主从同步的架构进一步扩展,为了适应日益增长的流量.针对mysql架构的扩展,先是咨询前辈,后和同事探讨,准备采用Mysq ...
- 【原】基于 HAproxy 1.6.3 Keeplived 在 Centos 7 中实现mysql mariadb galera cluster 集群分发读写 —— 上篇
前言 有一段时间没有写blogs,乘着周末开始整理下haproxy + keeplived 实现 mysql mariadb galera cluster 集群访问环境的搭建工作. 本文集中讲hapr ...
- (转)基于keepalived搭建MySQL的高可用集群
基于keepalived搭建MySQL的高可用集群 原文:http://www.cnblogs.com/ivictor/p/5522383.html MySQL的高可用方案一般有如下几种: keep ...
- 从零开始:Mysql基于Amoeba的集群搭建
从零开始:Mysql基于Amoeba的集群搭建 准备环境 1.mysql-5.7.24-linux-glibc2.12-x86_64.tar.gz 2.amoeba-mysql-binary-2.0. ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
随机推荐
- Go 语言为什么很少使用数组?
大家好,我是 frank,「Golang 语言开发栈」公众号作者. 01 介绍 在 Go 语言中,数组是一块连续的内存,数组不可以扩容,数组在作为参数传递时,属于值传递. 数组的长度和类型共同决定数组 ...
- 首次引入大模型!Bert-vits2-Extra中文特化版40秒素材复刻巫师3叶奈法
Bert-vits2项目又更新了,更新了一个新的分支:中文特化,所谓中文特化,即针对中文音色的特殊优化版本,纯中文底模效果百尺竿头更进一步,同时首次引入了大模型,使用国产IDEA-CCNL/Erlan ...
- 交换机SNMP配置
配置参考v2c为例 1.华为 snmp-agent protocol source-interface vlanif 1 ##S573x以上型号交换机需要snmp-agentsnmp-agent sy ...
- Tpon 1.0 一键查询网站存在过的路径
Tpon 1.0 寻找网站存在过的路径 该工具能够让你发现意料之外的路径 工具描述 编写该工具旨在寻找网站存在过的网站路径,这个地址可能是机器爬下来的也可能是某些人访问过的,在表面你可能看不到它的入口 ...
- LiteAI 四大杀手锏,解锁物联网智能设备AI开发难关
[摘要] IoT设备中嵌入AI能力实现产品的智能升级,已经是AIoT行业发展的重要通道,那怎样才能实现AIoT = AI + IoT呢?如何将AI模型塞到小小的IoT设备里,让它可以轻松运行起来呢?成 ...
- 三步实现BERT模型迁移部署到昇腾
本文分享自华为云社区 <bert模型昇腾迁移部署案例>,作者:AI印象. 镜像构建 1. 基础镜像(由工具链小组统一给出D310P的基础镜像) From xxx 2. 安装mindspor ...
- 干货时间:聊聊DevOps下的技术系列之契约测试
摘要:本期和大家简单聊聊在服务交互场景下使用服务契约的重要性,以及契约管理的必要性,最后简单介绍了下契约测试. 1.服务交互带来的问题 在上一篇文章中,我们系统的列举了DevOps各个流程中常用的测试 ...
- 云小课 | 华为云KYON之ELB混合负载均衡
摘要:本文介绍在华为云KYON(Keep Your Own Network)企业级云网络解决方案中,弹性负载均衡服务提供混合负载均衡功能,支持使用公有云的负载均衡绑定华为云上和IDC,实现云上云下业务 ...
- 云图说|云数据库RDS跨区域备份
摘要:云数据库RDS支持将备份文件存放到另一个区域存储,某一区域的实例故障后,可以在异地区域使用备份文件在异地恢复到新的RDS实例,用来恢复业务. 本文分享自华为云社区<云图说_云数据库RDS- ...
- 基于Serverless的端边云一体化媒体网络
摘要:视频在边缘的创新方向在哪?下一代视频云平台什么样? 本文分享自华为云社区<探讨视频云与边缘云平台的竞争力--基于Serverless的端边云一体化媒体网络>,作者/卢志航,整理 / ...