LightGBM和XGBoost的区别?
首先声明,LightGBM是针对大规模数据(样本量多,特征多)时,对XGBoost算法进行了一些优化,使得速度有大幅度提高,但由于优化方法得当,而精度没有减少很多或者变化不大,理论上还是一个以精度换速度的目的。如果数据量不大,那就对XGBoost没有什么优势了。
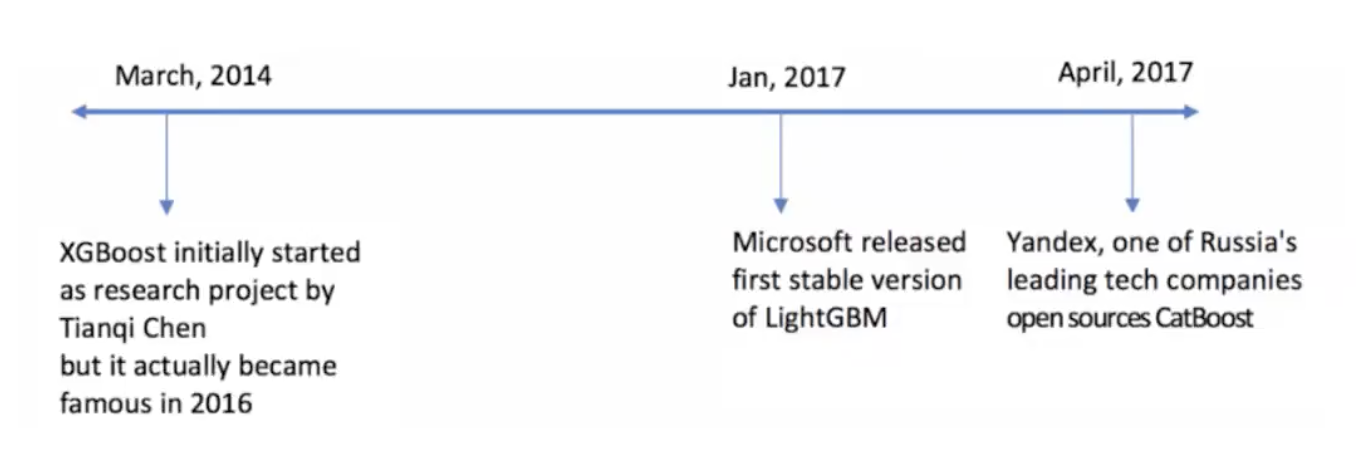
我认为有这几点:
1.GOSS(Gradient-based One-Side Sampling),基于梯度的单侧采样,对训练样本的采样。
如原始训练数据100w,高梯度数据有1w,那么会计算 1w+随机选择b%*余下的99w数据,然后把后部分数据进行加倍(*(1-a)/b),基于这些数据来得到特征的切分点。
2.EFB(Exclusive Feature Bundling),排斥特征整合,通过对某些特征整合来降低特征数量。
上面两点是在原论文中多次提到的,主要的不同。
参考原论文:https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
其它的我认为还有两点:
3.查找连续变量 切分点 的方法
XGBoost默认使用的是pre-sorted algorithm,即先将连续变量排序,然后从前向后计算每个切分点后的信息增益,这样算法复杂度是#data*#feature。好像也可以支持使用histogram。
LightGBM使用的是histogram-based algorithms,即将连续值先bin成k箱,然后再求切分点,每次计算切分点的复杂度是#k*#feature,但这样会有一些精度损失。但由于,a粗精度可以相当于正则化的效果,防止过拟合。b单棵树的精度可能会差一些,但在gbdt框架下,总体的效果不一定差。c在gbdt中决策树是弱模型,精度不高影响也不大。
4.树的生长方式
XGBoost是level(depdh)-wise,即左右子树都是一样深的,要生长一块生长,要停一块停。
LightGBM是leaf-wise,即可能左右子树是不一样深的,即使左子树已经比右子树深很多,但只要左子树的梯度划分仍然比右子树占优,就继续在左子树进行划分。

5、对类别特征的支持
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1 特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM 优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1 展开。并在决策树算法上增加了类别特征的决策规则。在 Expo 数据集上的实验,相比0/1 展开的方法,训练速度可以加速 8 倍,并且精度一致。据我们所知,LightGBM 是第一个直接支持类别特征的 GBDT 工具。
参考:https://blog.csdn.net/friyal/article/details/82756777
LightGBM和XGBoost的区别?的更多相关文章
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
- LightGBM大战XGBoost,谁将夺得桂冠?
引 言 如果你是一个机器学习社区的活跃成员,你一定知道 提升机器(Boosting Machine)以及它们的能力.提升机器从AdaBoost发展到目前最流行的XGBoost.XGBoost实际上已经 ...
- GBDT XGBOOST的区别与联系
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear). 传统GBDT以CART作为基分类器,xgboost还支持线性分 ...
- 机器学习算法中GBDT和XGBOOST的区别有哪些
首先xgboost是Gradient Boosting的一种高效系统实现,并不是一种单一算法.xgboost里面的基学习器除了用tree(gbtree),也可用线性分类器(gblinear).而GBD ...
- RF,GBDT,XGBoost,lightGBM的对比
转载地址:https://blog.csdn.net/u014248127/article/details/79015803 RF,GBDT,XGBoost,lightGBM都属于集成学习(Ensem ...
- XGBoost、LightGBM、Catboost总结
sklearn集成方法 bagging 常见变体(按照样本采样方式的不同划分) Pasting:直接从样本集里随机抽取的到训练样本子集 Bagging:自助采样(有放回的抽样)得到训练子集 Rando ...
- 机器学习-树模型理论(GDBT,xgboost,lightBoost,随机森林)
tree based ensemble algorithms 主要介绍以下几种ensemble的分类器(tree based algorithms) xgboost lightGBM: 基于决策树算法 ...
- xgboost gbdt特征点分烈点
lightGBM与XGBoost的区别:(来源于:http://baijiahao.baidu.com/s?id=1588002707760744935&wfr=spider&for= ...
- L2R 三:常用工具包介绍之 XGBoost与LightGBM
L2R最常用的包就是XGBoost 和LightGBM,xgboost因为其性能及快速处理能力,在机器学习比赛中成为常用的开源工具包, 2016年微软开源了旗下的lightgbm(插句题外话:微软的人 ...
随机推荐
- id就是方法名,如何调用;批量input怎么获取他们的key值作为参数
1.很多Dom的时候,一个个写会比较麻烦,我用ID记载他的方法名: 2.很多input,在数据交互的时候一个个获取会比较繁琐,给一个方法,批量获取. <div id="searchSt ...
- Html 常见标签,css基础样式,css的浮动和清流,浏览器的兼容
1.html模板<!DOCTYPE html><html><head> <meta charset="UTF-8"> <tit ...
- .NET CORE 热更新,否则提示DLL文件在使用中
1.创建空目录,取名updatesite,里面放置app_ffline.htm文件,网站更新中访问使用,内容随意 2.updatesite目录下面创建Release目录,用于放置更新的dll文件 3. ...
- nodejs(8) 使用ejs渲染动态页面
使用ejs渲染动态页面 步骤: 安装 ejs 模板引擎npm i ejs -S 使用 app.set() 配置默认的模板引擎 app.set('view engine', 'ejs') 使用 app. ...
- 吴裕雄--天生自然TensorFlow2教程:前向传播(张量)- 实战
手写数字识别流程 MNIST手写数字集7000*10张图片 60k张图片训练,10k张图片测试 每张图片是28*28,如果是彩色图片是28*28*3-255表示图片的灰度值,0表示纯白,255表示纯黑 ...
- 吴裕雄--天生自然TensorFlow2教程:Broadcasting
Broadcasting可以理解成把维度分成大维度和小维度,小维度较为具体,大维度更加抽象.也就是小维度针对某个示例,然后让这个示例通用语大维度. import tensorflow as tf x ...
- Python-查找并保存特定字符串后面的字符串
-- -- 本算法用于查找并存储“特定字符串”后面的字符串. -- 举例: strli = "kaka is li is da is wei !" #用于查找的字符串 sep_li ...
- Linux--计划任务未执行
参考:http://blog.csdn.net/shangdiyisi/article/details/9477521 日志 /var/log/cron
- 2019牛客网暑假多校训练第四场 K —number
链接:https://ac.nowcoder.com/acm/contest/884/K来源:牛客网 题目描述 300iq loves numbers who are multiple of 300. ...
- 12 Spring Data JPA:springDataJpa的运行原理以及基本操作(下)
spring data jpaday1:orm思想和hibernate以及jpa的概述和jpa的基本操作 day2:springdatajpa的运行原理 day2:springdatajpa的基本操作 ...