Digix2019华为算法精英挑战赛代码
Digix2019华为算法精英挑战赛代码
最终成绩: 决赛第九
问题
根据手机型号,颜色,用户偏好,手机APP等信息预测用户年龄.
解决方案
这次比赛我们主要选择神经网络和lightgbm两种模型
神经网络
我们主要搭建了两种神经网络,一种是全连接神经网络,另外一种是密集连接神经网络(Dense connected block+ Fully connected block),我们在神经网络的搭建中,结合回归和分类两方面的损失,对模型进行优化。
全连接神经网络
神经网络主要使用全连接, 使用了两种结构, 第一种是将数据整合为一个数据表, 输入一个几层全连接网络,使用了Dropout, 结构、参数和使用的数据如表1-1,详细模型参数和模型搭建,见程序(main.py文件)
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(two_train.shape[1],)))
model.add(Dropout(0.6))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(6, activation='softmax'))
model.summary()
adam = optimizers.Adam(lr=0.00009, beta_1=0.9, beta_2=0.999)
model.compile(loss='categorical_crossentropy',optimizer=adam,metrics=['accuracy'])
Dense connected block+ Fully connected block
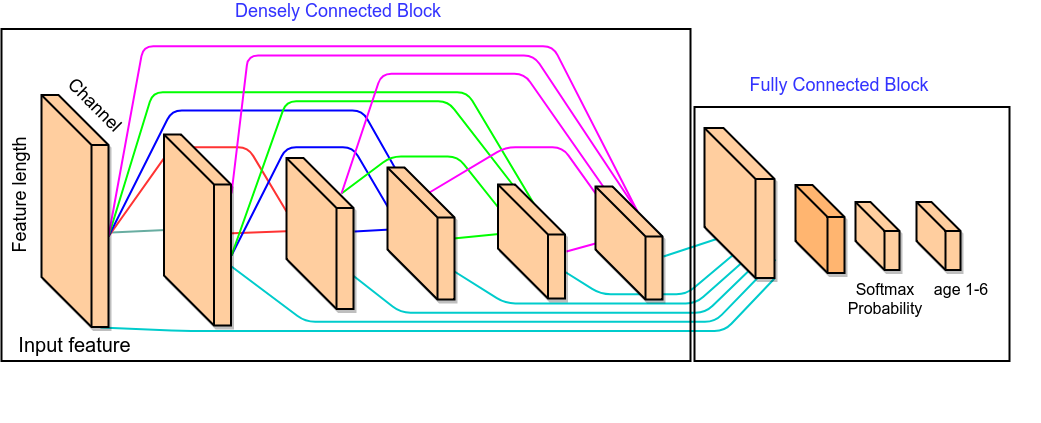
为减少参数,加速训练时间,我们使用了另外一种神经网络结构,底层先对各个分开的数据表分开输入,并使用densely connected的网络结构, 使用了正则化, Batch normalization, 初始化权重等。网络结构详见图1-6 ,同时为了提升网络的泛化性能,我们使用了mean_squared_error 和 cross entropy两种loss来训练整个网络,并设置权重,使得模型在验证集当中,达到最优的结果。在学习率方面,我们采用逐epoch衰减和随batch衰减的学习率。
为了减少网络参数和加快训练速度,我们对不同数据输入用Dense block单独处理,将不同Dense block的输出合并后,输入两层全连接网络得到64维向量,分别接入6维全连接层和1维全连接层,分别得到最小均方回归值和分类Softmax概率.
这种网络相比一般全连接网络和其它模型缩短了训练时间,只需要两个epoch就可以在验证集达到0.645以上的精准率,同时线上可以达到0.648的准确率;除此之外,这种网络在数据量增加后可以通过调整网络结构参数直接得到表达力更强的网络和更好的效果。(代码详见 runtrain.py)
Dense block的实现代码
参数:
Learning rate: 采用了逐epoch衰减和随batch衰减,具体参数见程序(runtrain.py文件);
Regularize: Dense block采用了l1正则化,Fully connected部分采用了l2正则化;
Batch Normalization: 网络的每一层均使用了batch normalization;
Architecture:每个数据表的处理特征部分使用了不同的网络结构和层数;
Loss:为了提高模型的泛化性能,我们使用了mean_squared_error和categorical_crossentropy两种loss来训练整个网络, 但考虑到最终任务是分类, 我们对两者设置了不同的权重,即交叉熵的权重远大于最小均方差;
regularizer_para_2 = regularizers.l2(0.01)
learning_rate = 0.003
dim_bhv = 8
dim_bsc1 = 7
dim_bsc2 = 739 # 'city prodName color ct carrier'
dim_act = 9401
dim_time = 9401
dim_duration = 9401
dim_time_new = 9402
dim_duration_new = 9402
dim_tfidf = 9401
dim_app = 56340
dim_app1 = 40
dropout_rate = 0.01
Initializer = initializers.he_uniform()#initializers.TruncatedNormal()
input_app, encode_app = dense_add(dim_app, [1024, 256, 128, 64], 64)
input_bhv, encode_bhv = dense_add(dim_bhv, [32, 16], 16)
input_bsc1, encode_bsc1 = dense_add(dim_bsc1, [32, 16], 16)
input_app1, encode_app2 = dense_add(dim_app1, [32, 16], 32)
input_bsc2, encode_bsc2 = dense_add(dim_bsc2, [256, 128, 64], 64)
input_act, encode_act = dense_add(dim_act, [512, 256, 128, 64], 64)
input_time, encode_time = dense_add(dim_time, [512, 256, 128, 64], 64)
input_duration, encode_duration = dense_add(dim_duration, [512, 256, 128, 64], 64)
input_time_new, encode_time_new = dense_add(dim_time_new, [256, 128, 64], 64)
input_duration_new, encode_duration_new = dense_add(dim_duration_new, [256, 128, 64], 64)
input_tfidf, encode_tfidf = dense_add(dim_tfidf, [256, 128, 64], 64)
dim_constant = 886
input_constant, encode_constant = dense_add(dim_constant, [256, 128, 64], 32)
dim_cv_max = 5000
input_cv_max, encode_cv_max = dense_add(dim_cv_max, [256, 128, 64], 64)
lightgbm
Lightgbm模型所选的数据为前面用户的基本属性、加上所选5000个APP的用户激活信息和用户的usage使用日志信息,总共为15795维(代码详情见 lgb.py)
不断的通过模型的测试结果和特征选择,最后选取15795维的特征。模型参数
"boosting_type": "gbdt",
"objective": "multiclass",
"metric": "multi_error",
"num_class": 6,
"num_leaves": 256,
"lambda_l2": 20,
"lambda_l1":0.0,
"bagging_fraction": 0.9,
"feature_fraction": 0.6,
"bagging_freq": 10,
"learning_rate": 0.05,
"bagging_seed": 2019,
"feature_fraction_seed": 2019,
"num_threads": 48
更好的解决方案
https://github.com/luoda888/HUAWEI-DIGIX-AgeGroup
Digix2019华为算法精英挑战赛代码的更多相关文章
- 2021华为软件精英挑战赛(C/C++实现)-苦行僧的实现过程
下面给出2021华为软件精英挑战赛参与的整个过程,虽然成绩不是很好,但是也是花了一些时间的,希望后面多多学习,多多进步. 代码已经上传到了Github上:https://github.com/myFr ...
- <路径算法>哈密顿路径变种问题(2016华为软件精英挑战赛初赛)
原创博客,转载请联系博主! 前言:几天前华为的这个软件精英(算法外包)挑战赛初赛刚刚落幕,其实这次是我第二次参加,只不过去年只入围到了64强(32强是复赛线),最后搞到了一个华为的一顶帽子(感谢交大l ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一道算法题目, 二行代码, Binary Tree
June 8, 2015 我最喜欢的一道算法题目, 二行代码. 编程序需要很强的逻辑思维, 多问几个为什么, 可不可以简化.想一想, 二行代码, 五分钟就可以搞定; 2015年网上大家热议的 Home ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- AC-BM算法原理与代码实现(模式匹配)
AC-BM算法原理与代码实现(模式匹配) AC-BM算法将待匹配的字符串集合转换为一个类似于Aho-Corasick算法的树状有限状态自动机,但构建时不是基于字符串的后缀而是前缀.匹配 时,采取自后向 ...
- 利用朴素贝叶斯算法进行分类-Java代码实现
http://www.crocro.cn/post/286.html 利用朴素贝叶斯算法进行分类-Java代码实现 鳄鱼 3个月前 (12-14) 分类:机器学习 阅读(44) 评论(0) ...
- 如何将Android Studio与华为软件开发云代码仓库无缝对接(二)
上篇文章:如何将Android Studio与华为软件开发云代码仓库无缝对接(一) 上一章讲了,如何用Android Studio以软件开发云代码仓库为基础,新建一个项目.接下来,这一章继续讲建好项目 ...
- 对一致性Hash算法,Java代码实现的深入研究(转)
转载:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读 ...
随机推荐
- Chisel3-Intellij IDEA中使用sbt构建Chisel项目
https://mp.weixin.qq.com/s/gssjiiPW6zUzKwCFZdNduw 1. 使用Intellij IDEA创建Scala项目 Chisel项目,就是构建Scala ...
- SpringBoot 及其 基本原理、配置文件(二)
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.SpringBoot 的版本与启动过程 1.SpringBoot都是jar工程 2.Spring ...
- Vue中导出Excel表格方法
本文记录一下在Vue中实现导出Excel表格的做法.参考度娘上各篇博客,最后实现功能 Excel表格,我的后端返回的是数据流,然后文件名是放进了content-disposition中,前端进行获取. ...
- ASP.NET的Web网页如何进行分页操作(Demo举例)
大概说一下思路,可以利用sql的 Offset/Fetch Next分页,点击这里 这里的Demo利用LINQ的写好的方法 //这里是某个表的列表 skip是跳过前面的多少条数据 take这是跳过前面 ...
- Java实现 洛谷 P6183 [USACO10MAR]The Rock Game S(DFS)
P6183 [USACO10MAR]The Rock Game S 输入输出样例 输入 3 输出 OOO OXO OXX OOX XOX XXX XXO XOO OOO PS: 因为每一位只有两种可能 ...
- Java实现 蓝桥杯VIP 算法提高 密码锁
算法提高 题目 2 密码锁 时间限制:1.0s 内存限制:1.0GB 问题描述 你获得了一个据说是古代玛雅人制作的箱子.你非常想打开箱子看看里面有什么东西,但是不幸的是,正如所有故事里一样,神秘的箱子 ...
- Java实现 LeetCode 45 跳跃游戏 II(二)
45. 跳跃游戏 II 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 你的目标是使用最少的跳跃次数到达数组的最后一个位置. 示例: 输入: [ ...
- Java实现LeetCode_0035_SearchInsertPosition
package javaLeetCode.primary; public class SearchInsertPosition_35 { public static void main(String[ ...
- Python学习之温度转换实例分析篇
#TempConvert.py Tempstr=input('请输入要转换的温度值:') if Tempstr[-1] in ['C','c']: F=1.8*eval(Tempstr[0:-1])+ ...
- 用斗地主的实例学会使用java Collections工具类
目录 一.背景 二.概念 1.定义 2.方法 2.1.排序方法 2.2.查找/替换方法 三.斗地主实例 3.1.代码结构 3.2.常量定义 3.3.单只牌类 3.4.玩家类 3.5.主程序 四.深入理 ...