吴裕雄--python学习笔记:爬虫基础
一、什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
二、Python爬虫架构
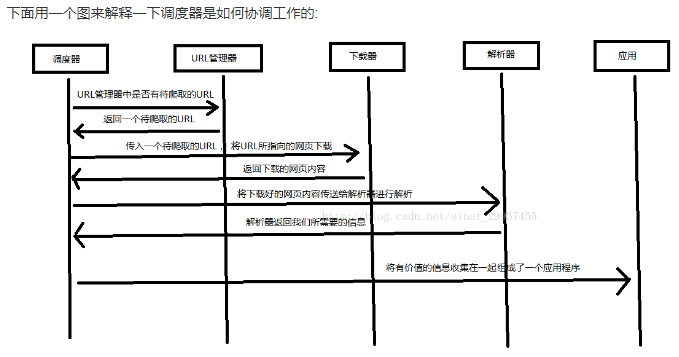
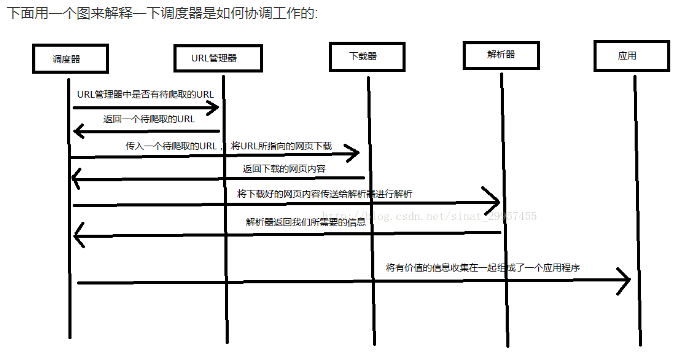
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
import urllib.request
import http.cookiejar url = "http://www.baidu.com"
response1 = urllib.request.urlopen(url)
print("第一种方法")
#获取状态码,200表示成功
print(response1.getcode())
#获取网页内容的长度
print(len(response1.read()))
第一种方法
200
156265
print("第二种方法")
request = urllib.request.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib.request.urlopen(request)
print(response2.getcode())
print(len(response2.read()))
第二种方法
200
156328
print("第三种方法")
cookie = http.cookiejar.CookieJar()
#加入urllib.request处理cookie的能力
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
urllib.request.install_opener(opener)
response3 = urllib.request.urlopen(url)
print(response3.getcode())
print(len(response3.read()))
print(cookie)
第三种方法
200
156488
<CookieJar[<Cookie BAIDUID=CA8C47A224EE898DC34E66D0182C70C3:FG=1 for .baidu.com/>, <Cookie BIDUPSID=CA8C47A224EE898D968EF5993499742B for .baidu.com/>, <Cookie H_PS_PSSID=1446_21123 for .baidu.com/>, <Cookie PSTM=1575029972 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=0 for www.baidu.com/>, <Cookie BD_HOME=0 for www.baidu.com/>]>
四、第三方库 Beautiful Soup 的安装
Beautiful Soup: Python 的第三方插件用来提取 xml 和 HTML 中的数据,官网地址 https://www.crummy.com/software/BeautifulSoup/ 1、安装 Beautiful Soup
pip install bs4
2、测试是否安装成功 编写一个 Python 文件,输入:
import bs4
print(bs4)
<module 'bs4' from 'e:\\python\\lib\\site-packages\\bs4\\__init__.py'>
五、使用 Beautiful Soup 解析 html 文件
import re
from bs4 import BeautifulSoup html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
#获取所有的链接
links = soup.find_all('a')
print("所有的链接")
for link in links:
print(link.name,link['href'],link.get_text())
所有的链接
a http://example.com/elsie Elsie
a http://example.com/lacie Lacie
a http://example.com/tillie Tillie
print("获取特定的URL地址")
link_node = soup.find('a',href="http://example.com/elsie")
print(link_node.name,link_node['href'],link_node['class'],link_node.get_text())
print("正则表达式匹配")
link_node = soup.find('a',href=re.compile(r"ti"))
print(link_node.name,link_node['href'],link_node['class'],link_node.get_text())
print("获取P段落的文字")
p_node = soup.find('p',class_='story')
print(p_node.name,p_node['class'],p_node.get_text())
获取特定的URL地址
a http://example.com/elsie ['sister'] Elsie
正则表达式匹配
a http://example.com/tillie ['sister'] Tillie
获取P段落的文字
p ['story'] Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
吴裕雄--python学习笔记:爬虫基础的更多相关文章
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄--python学习笔记:sqlite3 模块
1 sqlite3.connect(database [,timeout ,other optional arguments]) 该 API 打开一个到 SQLite 数据库文件 database 的 ...
- 吴裕雄--python学习笔记:os模块函数
os.sep:取代操作系统特定的路径分隔符 os.name:指示你正在使用的工作平台.比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'. os.getcwd:得 ...
- 吴裕雄--python学习笔记:os模块的使用
在自动化测试中,经常需要查找操作文件,比如说查找配置文件(从而读取配置文件的信息),查找测试报告(从而发送测试报告邮件),经常要对大量文件和大量路径进行操作,这就依赖于os模块. 1.当前路径及路径下 ...
- 吴裕雄--python学习笔记:BeautifulSoup模块
import re import requests from bs4 import BeautifulSoup req_obj = requests.get('https://www.baidu.co ...
- 吴裕雄--python学习笔记:通过sqlite3 进行文字界面学生管理
import sqlite3 conn = sqlite3.connect('E:\\student.db') print("Opened database successfully&quo ...
- 吴裕雄--python学习笔记:sqlite3 模块的使用与学生信息管理系统
import sqlite3 cx = sqlite3.connect('E:\\student3.db') cx.execute( '''CREATE TABLE StudentTable( ID ...
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
随机推荐
- UVA 10801 多线程最短路
题意:一栋摩天大楼从0层到K层,有N部电梯,每个电梯都有自己的运行速度,此外,对于某个电梯来说,并不是每一层都会停,允许在某一层进行电梯换乘,每次换乘固定消耗60秒,最终求从0层去K层的最短时间,如果 ...
- Linux 下载安装
安装教程:https://www.runoob.com/linux/linux-install.html Linux图形界面与命令行界面切换https://blog.csdn.net/ab522628 ...
- IDEA中使用Lombok时候,getter,setter注解不生效/每次重启后才生效
Relevance.java代码如下: import lombok.AllArgsConstructor; import lombok.Builder; import lombok.Data; imp ...
- C# 使用 HttpPost 请求调用 WebService (转)
转自 https://www.cnblogs.com/Brambling/p/7266482.html 之前调用 WebService 都是直接添加服务引用,然后调用 WebService 方法的,最 ...
- Java注解基础
0.背景 Java注解--Annotation产生于JDK5.作为code的特殊“标记”,注解可以在编译.类加载.运行时被读取,并执行处理. 开发利用注解在源码中嵌入补充信息,工具(代码分析.开发.部 ...
- MonkeyScript常用命令及Uiautomatorview问题解决
一.MonkeyScript执行脚本的命令 adb shell monkey -f <scriptfile><event-count> 1.Dispatch Trackball ...
- LGOJ2568 GCD
Description link 给定整数\(n\),\(1 \leq x,y \leq n\)且\(gcd(x,y)\)为质数的\((x,y)\)的对数 \[1\leq n\leq 10^7\] S ...
- 必应翻译:让Windows上的翻译不再是难事
文章译自:Translations Made Easy on Windows 比方说今年夏天你想出国旅行,计划去一趟德国.你的行程很丰富:参观慕尼黑和柏林,乘坐游船沿莱茵河而下,再品尝几串摩泽尔的葡萄 ...
- Linux修改主机名称方法
碰到这个问题的时候,是在安装Zookeeper集群的时候,碰到如下问题 java.net.UnknownHostException: XXXX Name or service not knownjav ...
- maven中指定build一个project中几个特定的子modules
问题由来: 一个项目可能会有多个子module,在特定情况下可能只需要build其中几个module. 例如我的项目的目录结构如下 myproject |------------module_one ...