ysql常用sql语句(12)- group by 分组查询
测试必备的Mysql常用sql语句系列
https://www.cnblogs.com/poloyy/category/1683347.html
前言
- group by 关键字可以根据一个或多个字段对查询结果进行分组
- group by 一般都会结合Mysql聚合函数来使用
- 如果需要指定条件来过滤分组后的结果集,需要结合 having 关键字;原因:where不能与聚合函数联合使用
group by 的语法格式
GROUP BY <字段名>[,<字段名>,<字段名>]
确认测试表里有什么数据,方便后面的栗子做对比
group by 单字段分组的栗子
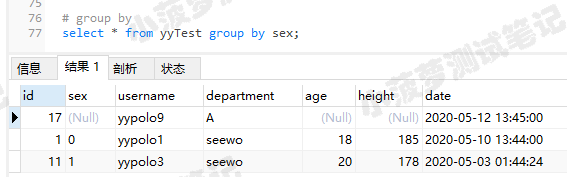
对sex单个字段进行分组查询
select * from yyTest group by sex;
知识点
分组之后,只会返回组内第一条数据;具体原理可以看看下图

group by 多字段分组的栗子
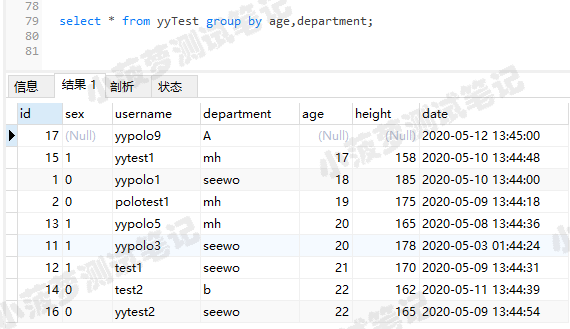
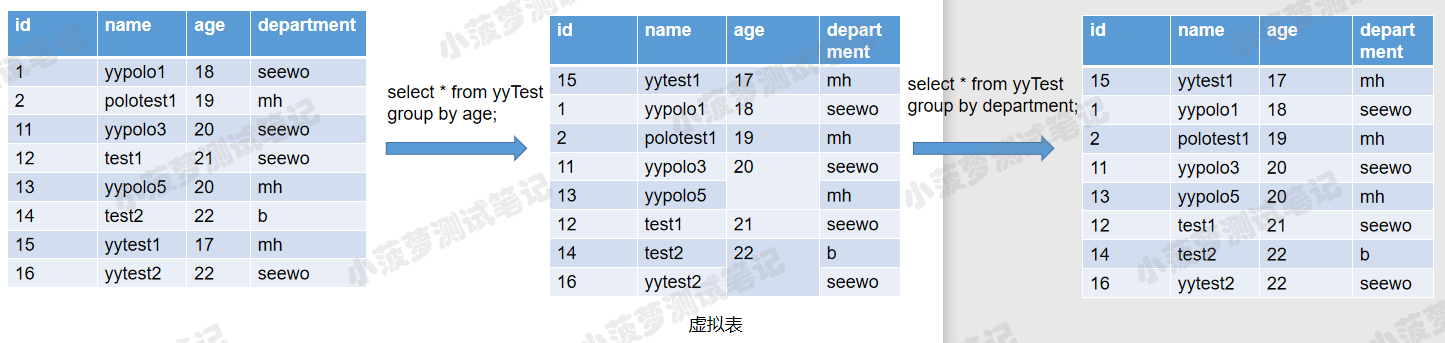
先按照age进行分组,然后再在每个组内按department分组
select * from yyTest group by age,department;
知识点
- 多个字段分组查询时,先按照第一个字段分组,如果第一个字段有相同值,则把分组结果再按第二个字段进行分组,以此类推
- 如果第一个字段每个值都是唯一的,则不会按照第二个字段再进行分组了,具体原理可看下图
group by + group_concat()的栗子
group_concat()可以将分组后每个组内的值都显示出来
select department,group_concat(username) as "部门员工名字" from yyTest group by department;
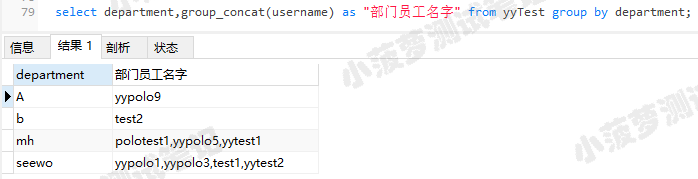
可以看到,按department部门分组 ,然后查看每个部门都有哪些员工的名字;还是很便捷的
group by +聚合函数的栗子
有什么聚合函数?
- count():统计记录的条数
- sum():字段值的总和
- max():字段值的最大值
- min():字段值的最小值
- avg():字段值的平均值
具体的栗子
# count统计条数
select count(*) from yyTest group by department; # sum总和
select sum(age) from yyTest group by department; # max最大值
select max(age) from yyTest group by department; # min最小值
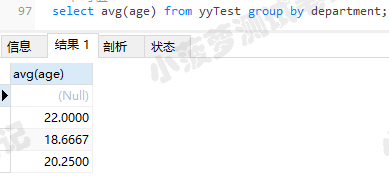
select min(age) from yyTest group by department; # 平均值
select avg(age) from yyTest group by department;
group by + with rollup的栗子
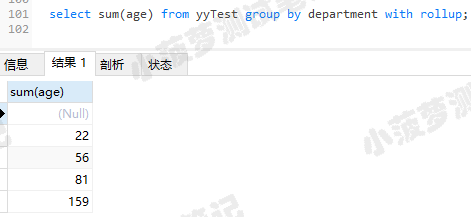
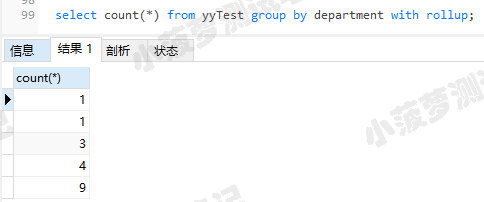
with rollup用来在所有记录的最后加上一条记录,显示上面所有记录每个字段的总和(不懂的直接看栗子)
select GROUP_CONCAT(username) from yyTest group by department with rollup;

select sum(age) from yyTest group by department with rollup;
select count(*) from yyTest group by department with rollup ;
ysql常用sql语句(12)- group by 分组查询的更多相关文章
- Mysql常用sql语句(3)- select 查询语句基础使用
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 针对数据表里面的每条记录,select查询语句叫 ...
- Mysql常用sql语句(20)- 子查询重点知识
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 子查询语句可以嵌套在 sql 语句中任何表达式出现的位 ...
- Oracle常用sql语句(三)之子查询
子查询 子查询要解决的问题,不能一步求解 分为: 单行子查询 多行子查询 语法: SELECT select_list FROM table WHERE expr operator (SELECT s ...
- Mysql常用sql语句(13)- having 过滤分组结果集
测试必备的Mysql常用sql语句,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1683347.html 前言 ...
- oracle常用SQL语句(汇总版)
Oracle数据库常用sql语句 ORACLE 常用的SQL语法和数据对象一.数据控制语句 (DML) 部分 1.INSERT (往数据表里插入记录的语句) INSERT INTO 表名(字段名1, ...
- oracle 常用sql语句
oracle 常用sql语句 1.查看表空间的名称及大小 select t.tablespace_name, round(sum(bytes/(1024*1024)),0) ts_sizefrom d ...
- Oracle数据库常用Sql语句大全
一,数据控制语句 (DML) 部分 1.INSERT (往数据表里插入记录的语句) INSERT INTO 表名(字段名1, 字段名2, ……) VALUES ( 值1, 值2, ……); INSE ...
- 一些常用SQL语句大全
一.基础 1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- ...
- 常用SQL语句大全
一些常用SQL语句大全 一.基础1.说明:创建数据库CREATE DATABASE database-name2.说明:删除数据库drop database dbname3.说明:备份sql se ...
随机推荐
- linux 文件的查找和压缩
1.使用 locate 命令 需要安装:yum install mlocate -y 创建或更新 slocate/locate 命令所必需的数据库文件:updatedb 作用:搜索不经常改变的文件如配 ...
- (一)微信小程序:实现引导页
基本目录结构 index目录下文件操作步骤 1.针对index.wxml <!--index.wxml--> <view class="index-container&qu ...
- redis: 事务管理(九)
redis的事务 不保证原子性 三个步骤:开启事务.命令入队.执行事务 开启事务:multi 执行事务:exec 127.0.0.1:6379> multi #开启事务 OK 127.0.0.1 ...
- 使用JAVA API编程实现简易Habse操作
使用JAVA API编程实现下面内容: 1.创建<王者荣耀>游戏玩家信息表gamer,包含列族personalInfo(个人信息).recordInfo(战绩信息).assetsInfo( ...
- 消息中间件metaq
消息中间件metaq安装并注册到zookper集群 项目地址 https://github.com/killme2008/Metamorphosis Memorphosis是一个消息中间件,它是lin ...
- Win10 及 Google 浏览器显示界面异常
win10 和 google 界面显示异常 win10 个别 ui 组件花屏,google 界面直接黑屏 解决方式 更新集成显卡或者重装显卡驱动,最好使用 驱动人生 !!!
- 在java 8 stream表达式中实现if/else逻辑
目录 简介 传统写法 使用filter 总结 简介 在Stream处理中,我们通常会遇到if/else的判断情况,对于这样的问题我们怎么处理呢? 还记得我们在上一篇文章lambda最佳实践中提到,la ...
- includes与indexOf
indexOf(a,b)是在es6之前常用的判断数组/字符串内元素是否存在的api,接收两个参数,第一个a代表要被查找的元素,必填.第二个代表从数组的某个坐标开始查找,可选 在数组中 通过indexO ...
- 开发AI+诊疗生发系统,「先锋汇美」借力人工智能辅助诊疗实现头皮医学检测...
困扰年轻人的脱发问题萌生了新兴的产业链.36氪先前曾剖析过近来火热的植发市场,更多人则选择"防范于未然","头皮检测"服务备受关注.此前,人们对"头皮 ...
- 已有项目接入git远程仓库
1.项目根目录初始化git仓库 git init 2.将本地项目与远程仓库关联(首先得在远程创建一个代码仓库) git remote add origin 远程仓库地址 诺,仓库地址就是这个玩意 3. ...