Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL原理解析前言:
Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说,这个阶段就是使用Antlr4,将一条Sql语句解析成语法树。
可能有童鞋没接触过antlr4这个内容,推荐看看《antlr4权威指南》前四章,看完起码知道antlr4能干嘛。我这里就不多介绍了。
这篇首先先介绍调用spark.sql()时候的流程,再看看antlr4在这个其中的主要功能,最后再将探究Logical Plan究竟是什么东西。
初始流程
当你调用spark.sql的时候,会调用下面的方法:
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
parse sql阶段主要是parsePlan(sqlText)这一部分。而这里又会辗转去org.apache.spark.sql.catalyst.parser.AbstractSqlParser调用parse方法。这里贴下关键代码。
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
lexer.legacy_setops_precedence_enbled = SQLConf.get.setOpsPrecedenceEnforced
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
parser.legacy_setops_precedence_enbled = SQLConf.get.setOpsPrecedenceEnforced
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// Try Again.
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
可以发现,这里面的处理逻辑,无论是SqlBaseLexer还是SqlBaseParser都是Antlr4的东西,包括最后的toResult(parser)也是调用访问者模式的类去遍历语法树来生成Logical Plan。如果对antlr4有一定了解,那么对这里这些东西一定不会陌生。那我们接下来看看Antlr4在这其中的角色。
Antlr4生成语法树
Spark提供了一个.g4文件,编译的时候会使用Antlr根据这个.g4生成对应的词法分析类和语法分析类,同时还使用了访问者模式,用以构建Logical Plan(语法树)。
访问者模式简单说就是会去遍历生成的语法树(针对语法树中每个节点生成一个visit方法),以及返回相应的值。我们接下来看看一条简单的select语句生成的树是什么样子。
这个sqlBase.g4文件我们也可以直接拿出来玩,直接复制出来,用antlr相关工具就可以生成一个生成一个解析SQL的图了。
这里antlr4和grun都已经存储成bat文件,所以可以直接调用,实际命令在《antlr4权威指南》说得很详细了就不介绍了。调用完后就会生成这样的语法树。
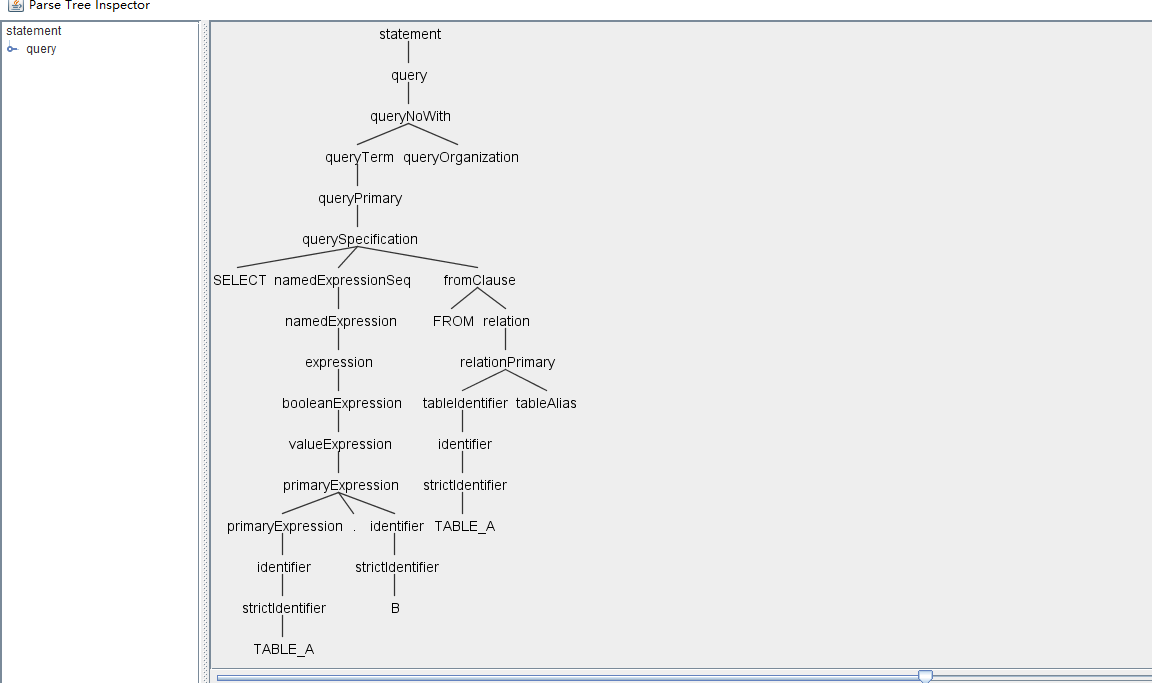
这里,将SELECT TABLE_A.B FROM TABLE_A,转换成一棵语法树。我们可以看到这颗语法树非常复杂,这是因为SQL解析中,要适配这种SELECT语句之外,还有很多其他类型的语句,比如INSERT,ALERT等等。Spark SQL这个模块的最终目标,就是将这样的一棵语法树转换成一个可执行的Dataframe(RDD)。
我们现阶段的目标则是要先生成Logical Plan,Spark使用Antlr4的访问者模式,生成Logical Plan。这里顺便说下怎么实现访问者模式吧,在使用antlr4命令的时候,加上-visit参数就会生成SqlBaseBaseVisitor,里面提供了默认的访问各个节点的触发方法。我们可以通过继承这个类,重写对应节点的visit方法,实现自己的访问逻辑,而这个继承的类就是org.apache.spark.sql.catalyst.parser.AstBuilder。
通过观察这棵树,我们可以发现针对我们的SELECT语句,比较重要的一个节点,是querySpecification节点,实际上,在AstBuilder类中,visitQuerySpecification也是比较重要的一个方法(访问对应节点时触发),正是在这个方法中生成主要的Logical Plan的。
接下来重点看这个方法,以及探究Logical Plan。
生成Logical Plan
我们先看看AstBuilder中的代码:
class AstBuilder(conf: SQLConf) extends SqlBaseBaseVisitor[AnyRef] with Logging {
......其他代码
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) { //如果有FROM语句,生成对应的Logical Plan
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
......其他代码
代码中会先判断是否有FROM子语句,有的话会去生成对应的Logical Plan,再调用withQuerySpecification()方法,而withQuerySpecification()方法是比较核心的一个方法。它会处理包括SELECT,FILTER,GROUP BY,HAVING等子语句的逻辑。
代码比较长就不贴了,有兴趣的童鞋可以去看看,大意就是使用scala的模式匹配,匹配不同的子语句生成不同的Logical Plan。
然后再来说说最终生成的LogicalPlan,LogicalPlan其实是继承自TreeNode,所以本质上LogicalPlan就是一棵树。
而实际上,LogicalPlan还有多个子类,分别表示不同的SQL子语句。
- LeafNode,叶子节点,一般用来表示用户命令
- UnaryNode,一元节点,表示FILTER等操作
- BinaryNode,二元节点,表示JOIN,GROUP BY等操作
这里一元二元这些都是对应关系代数方面的知识,在学数据库理论的时候肯定有接触过,不过估计都还给老师了吧(/偷笑)。不过一元二元基本上也就是用来区分具体的操作,如上面说的FILTER,或是JOIN等,也不是很复杂。这三个类都位于org.apache.spark.sql.catalyst.plans.logical.LogicalPlan中,有兴趣的童鞋可以看看。而后,这三个类又会有多个子类,用以表示不同的情况,这里就不再赘述。
最后看看用一个测试案例,看看会生成什么吧。示例中简单生成一个临时的view,然后直接select查询这个view。代码如下:
//生成DataFrame
val df = Seq((1, 1)).toDF("key", "value")
df.createOrReplaceTempView("src")
//调用spark.sql
val queryCaseWhen = sql("select key from src ")
补充下,这里的sql()方法是做了一些封装的方法,可以直接看成spark.sql(...)。最终经过parse SQL后会变成如下的内容:
'Project ['key]
+- 'UnresolvedRelation `src`
这个Project是UnaryNode的一个子类(SELECT自然是一元节点),表明我们要查询的字段是key。
UnresolvedRelation是一个新的概念,这里顺便说下,我们通过SQL parse生成的这棵树,其实叫Unresolved LogicalPlan,这里的Unresolved的意思说,还不知道src是否存在,或它的元数据是什么样,只有通过Analysis阶段后,才会把Unresolved变成Resolved LogicalPlan。这里的意思可以理解为,读取名为src的表,但这张表的情况未知,有待验证。
总的来说,我们的示例足够简单直接,所以内容会比较少,不过拿来学习是足够了。
下一个阶段是要使用这棵树进行分析验证了,也就是Analysis阶段,这一块留到下篇介绍吧。
以上~
Spark SQL源码解析(二)Antlr4解析Sql并生成树的更多相关文章
- Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
Spark SQL模块,主要就是处理跟SQL解析相关的一些内容,说得更通俗点就是怎么把一个SQL语句解析成Dataframe或者说RDD的任务.以Spark 2.4.3为例,Spark SQL这个大模 ...
- Spark SQL源码解析(三)Analysis阶段分析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Analysis阶段概述 首先 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Spark SQL源码解析(五)SparkPlan准备和执行阶段
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- 第十篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 query
/** Spark SQL源码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache在 ...
- springMVC源码分析--RequestParamMethodArgumentResolver参数解析器(三)
之前两篇博客springMVC源码分析--HandlerMethodArgumentResolver参数解析器(一)和springMVC源码解析--HandlerMethodArgumentResol ...
- MyBatis 源码分析 - 映射文件解析过程
1.简介 在上一篇文章中,我详细分析了 MyBatis 配置文件的解析过程.由于上一篇文章的篇幅比较大,加之映射文件解析过程也比较复杂的原因.所以我将映射文件解析过程的分析内容从上一篇文章中抽取出来, ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
随机推荐
- TensorFlow v2.0实现逻辑斯谛回归
使用TensorFlow v2.0实现逻辑斯谛回归 此示例使用简单方法来更好地理解训练过程背后的所有机制 MNIST数据集概览 此示例使用MNIST手写数字.该数据集包含60,000个用于训练的样本和 ...
- kaggle入门——泰坦尼克之灾
目录 引言 数据认识 总结 特征处理 建模预测 logistic分类模型 随机森林 SVM xgboost 模型验证 交叉验证 学习曲线 高偏差: 高方差 模型融合 总结 后记 引言 一直久闻kagg ...
- Lack of free swap space on Zabbix server
在模板(Template)里找到Linux OS模板,修改触发器 配置>模板>Template OS Linux>触发器 找到swap关键字 修改 {Template OS Linu ...
- Day13 流程控制
Linux中的流程控制语句 一.if语句 1.单分支if条件语句 格式:if [ 条件判断式 ] then 程序 fi 注意:1.在Linux中是以if开头,fi结尾.其他地方一般是{开头,} ...
- localStorage应用(写的时间缓存在本地浏览器)
最近用了下localStorage,于是想记录加深下映象: 有关更详细的介绍,可以去看https://www.cnblogs.com/st-leslie/p/5617130.html: 我这引用了这个 ...
- G - 土耳其冰淇凌 Gym - 101194D(二分答案 + 贪心检验)
熊猫先生非常喜欢冰淇淋,尤其是冰淇淋塔.一个冰淇淋塔由K个冰淇淋球堆叠成一个塔.为了使塔稳定,下面的冰淇淋球至少要有它上面的两倍大.换句话说,如果冰淇淋球从上到下的尺寸是A0, A1, A2,···, ...
- Java 配 Shell 等于美酒加咖啡
化学中我们得知「氢气加氧气在点燃的情况下会生成水」. 生活中我们得知「良辰加美景的情况下会得到千金春宵一刻」. 技术上又何尝不是如此呢?先假设一个场景:BOSS 让你实现一个服务监控的指挥室,能看到每 ...
- Fetch+SpringBoot跨域请求设置
两种方法从SpringBoot的方向解决跨域问题 今天搭建博客的时候,尝试性的传递数据,发现浏览器报了这个错误 -blocked by CORS policy: No 'Access-Control- ...
- VM虚拟机复制文件问题
需要安装好vmtools,安装好后,启动虚拟机环境: 把需要复制的文件拖进虚拟机环境窗口,鼠标指针会变成复制图标,直接左键即可复制: 不能Ctrl+c-Ctrl+v进去.
- 《Three.js 入门指南》3.1.1 - 基本几何形状 - 球体(SphereGeometry)
3.1 基本几何形状 球体(SphereGeometry) 构造函数: THREE.SphereGeometry(radius, segmentsWidth, segmentsHeight, phiS ...