count(1),count(*)和count(列)的比较
转自:https://www.cnblogs.com/Caucasian/p/7041061.html
1.关于count(1),count(*),和count(列名)的区别
相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快。一直有很大的疑问,有的人说count(*)更快,也有的人说count(列名)更快,那到底是谁更快,我将会在本文中详细介绍一下到底是count(1),count(*)和count(列明)的区别,和更适合的使用场景。
往常在工作中有人会说count(1)比count(*)会快,或者相反,首先这个结论肯定是错的,实际上count(1)和count(*)并没有区别。
接下来,我们来对比一下count(*)和count(列)到底谁更快一些
首先我们执行以下sql,来看一下执行效率(下面sql针对的是ORACLE数据库,大致逻辑为先删除t别,然后在根据dba_objects创建t表,在更新t表根据rownum)

1 drop table t purge;
2 create table t as select * from dba_objects;
3 --alter table T modify object_id null;
4 update t set object_id =rownum ;
5 set timing on
6 set linesize 1000
7 set autotrace on --开启跟踪
8
9 select count(*) from t;
10 /
11 select count(object_id) from t;
12 /
然后咱们分别看一下“select count(*) from t”和“select count(object_id) from t”语句的执行计划。(执行计划是指sql的一个执行顺序和耗费的资源,耗费的资源越少越快,如果在plsql中,使用F8可以查看sql的执行计划)
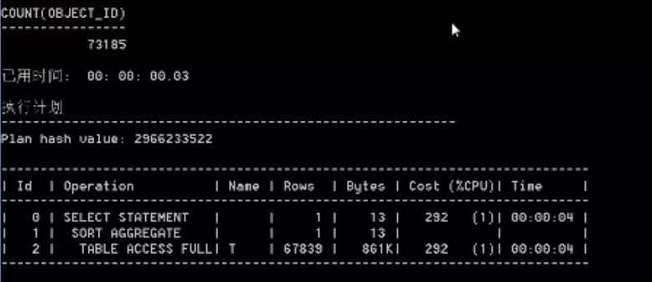
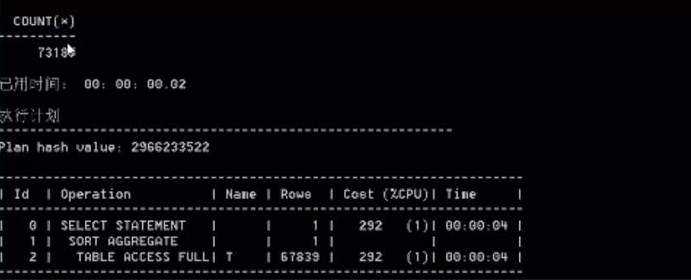
通过我们执行sql的实验来说,count(*)和count(列)消耗的资源是一样的,说面他们是一样快的,但是真的是这样么。那么咱们接着以下的实验。
这次咱们给object_id这一列加一个索引试一下。我们执行一下索引sql
1 create index idx_object_id on t(object_id);
2 select count(*) from t;
3 /
4
5
6 select count(object_id) from t;
7 /
然后我们在分别看一下两条sql的执行计划
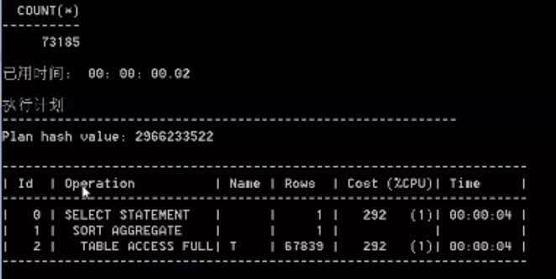
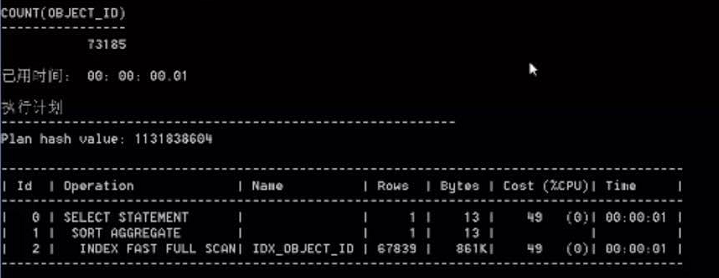
通过我们建完索引后。突然发现count(列)变快了好多,但是count(*)还是和以前一样的。这说明了count(列)可以用到索引,而count(*)不行,但是真的这样么,咱们在往下看。
接下来我们给object_id这个字段加上不可为空条件。我们执行以下sql
1 create index idx_object_id on t(object_id);
2 select count(*) from t;
3 /
4
5
6 select count(object_id) from t;
7 /
接下来我们在来看一下count(*)的执行计划

现在count(*)和count(列)一样快了,由此我们得出了这个结论:count(列)和count(*)其实一样快,如果索引列是非空的,count(*)可用到索引,此时一样快。
总结:但是真的结论是这样的么。其实不然。其实在数据库中count(*)和count(列)根本就是不等价的,count(*)是针对于全表的,而count(列)是针对于某一列的,如果此列值为空的话,count(列)是不会统计这一行的。所以两者根本没有可比性,性能比较首先要考虑写法等价,这两个语句根本就不等价。也就失去了去比较的意义!!!
2.关于表中字段顺序的问题
首先我们建一张有25个字段的表并加入数据在进行count(*)和count(列)比较。由于建表语句和插入语句和上面雷同。就不贴出代码了。
然后我们分别执行count(*)和count每一列的操作来看一下到底谁更快一些,由于执行计划太多,就不一一贴图了。我整理了一个excel来给大家看一下执行的结果
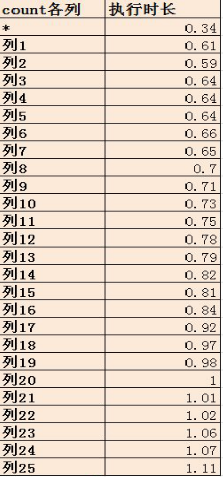
经过实验我们看出,count(列)越往后。我们的执行效率越慢。所以,我们得出以下结论:
1.列的偏移量决定性能,列越靠后,访问的开销越大。
2.由于count(*)的算法与列偏移量无关,所以count(*)最快。
总结:所以我们在开发设计中。越常用的列,要放在靠前的位置。而cout(*)和count(列)是两个不等价的用法,所以无法比较哪个性能更好,在实际的sql优化场景中要根据当时的业务场景再去考虑是使用count(*)还是count(列)(其中的区别上文有提到)。
以下内容来自个人总结:
1.数据库中只有一个字段:count(*)快
2.数据库中有索引:
count(1),count(*)和count(列)的比较的更多相关文章
- 【优化】COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)
[优化]COUNT(1).COUNT(*).COUNT(常量).COUNT(主键).COUNT(ROWID).COUNT(非空列).COUNT(允许为空列).COUNT(DISTINCT 列名) 1. ...
- SQLSERVER 里SELECT COUNT(1) 和SELECT COUNT(*)哪个性能好?
SQLSERVER 里SELECT COUNT(1) 和SELECT COUNT(*)哪个性能好? 今天遇到某人在我以前写的一篇文章里问到 如果统计信息没来得及更新的话,那岂不是统计出来的数据时错误的 ...
- count(*)、count(1)和count(列名)的区别
count(*).count(1)和count(列名)的区别 1.执行效果上: l count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL l count(1)包 ...
- COUNT(*)、COUNT(主键)、COUNT(1)
MyISAM引擎,记录数是结构的一部分,已存cache在内存中; InnoDB引擎,需要重新计算,id是主键的话,会加快扫描速度: 所以select count(*) MyISAM完胜! MyISA ...
- COUNT(*),count(1),COUNT(ALL expression),COUNT(DISTINCT expression)
创建一个测试表 IF OBJECT_ID( 'dbo.T1' , 'U' )IS NOT NULL BEGIN DROP TABLE dbo.T1; END; GO )); GO INSERT INT ...
- hql中不能写count(1)能够写count(a.id)
hql中不能写count(1)能够写count(a.id)里面写详细的属性 String hql="select new com.haiyisoft.vo.entity.cc.repo.Bu ...
- 今天犯了个小错误:_dataArray.count>1 和_dataArray.count>0搞混淆了
_dataArray.count>1 和_dataArray.count>0搞混淆了:当数据为一条时,条件不成立.应该_dataArray.count>=1 或者>0 ( ...
- oracle count(*) 和count(列)性能
一直以为oracle中count(列)比count(*) 快,这篇文件解释了一下: http://blog.csdn.net/szstephenzhou/article/details/8446481
- select count(1)和select count(*)的区别
select count(1) from 表a //查询时会对常数列进行统计行数select count(*) from 表a //查询时会找表a中最短的列进行统计行数 因为使用count(*)查询会 ...
- COUNT(*),count(1),COUNT(ALL expression),COUNT(DISTINCT expression) BY Group by
select column_2,count(column_2) as 'count(column_2)' ,count(column_1) as 'count(column_1)' ,count(*) ...
随机推荐
- NIO组件Channel
基本介绍 NIO的通道类似于流, 但有些区别: 通道可以同时进行读写, 而流只能读或者只能写 通道可以实现异步读写数据 通道可以从缓冲区(Buffer)读数据, 也可以写数据到缓冲区 BIO中的str ...
- Centos 8双网卡设置
原理:不管开发板是通过直连.路由器还是交换机连接到PC机,最终都是接到PC的以太网网卡(对笔记本来说,一般存在两个网卡,一个WIFI网卡和以太网网卡):因此要实现PC机与虚拟机的互ping,必须把虚拟 ...
- dedecms 标签使用 runphp=php 获取文章静态地址
[field:id runphp='yes'] $url=GetOneArchive(@me); @me=$url['arcurl']; [/field:id]
- Adapter之自定义Adapter
前言: 在我们写程序是经常会用到适配器,当系统自带的适配器不够用时即可自己定义适配器 正文: 因为我们用到的ListView视图所以我们先初始化ListView,在我们的主活动中添加如下代码 < ...
- windows下移植别人配置好的python环境
一般来说,我们在windows下配置python环境的时候可能会比较推荐用anaconda,那么有一个比较方便的anaconda环境移植方法,也就是说,如果我已经在windows上安装好了anacon ...
- RabbitMQ消息队列帮助类
调用 //消息队列发消息 MqConfigInfo config = new MqConfigInfo(); config.MQExChange = "DrawingOutput" ...
- 【BZOJ2400】Optimal Marks
题意 定义无向图中的一条边的值为:这条边连接的两个点的值的异或值. 定义一个无向图的值为:这个无向图所有边的值的和. 给你一个有 \(n\) 个结点 \(m\) 条边的无向图.其中的一些点的值是给定的 ...
- HDU 4921 Map DFS+状态压缩+乘法计数
算最多十条链,能截取某前缀段,每种方案都可以算出一个权值,每种方案的概率都是总数分之一,问最后能构成的所有可能方案数. 对计数原理不太敏感,知道是DFS先把链求出来,但是想怎么统计方案的时候想了好久, ...
- opencv.js双边滤波 磨皮处理
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta http ...
- 错误:selenium.common.exceptions.SessionNotCreatedException: Message: Unable to find a matching set of capabilities
错误再现 原因:firefox浏览器版本和浏览器驱动版本不匹配 解决办法:卸载高版本浏览器,安装低版本浏览器