Hadoop的FlieSystem类的使用
1.使用FileSystem类需要导入jar包
解压hadoop-2.7.7.tar.gz
复制如下三个jar包和lib下所有jar包到项目文件下的lib文件
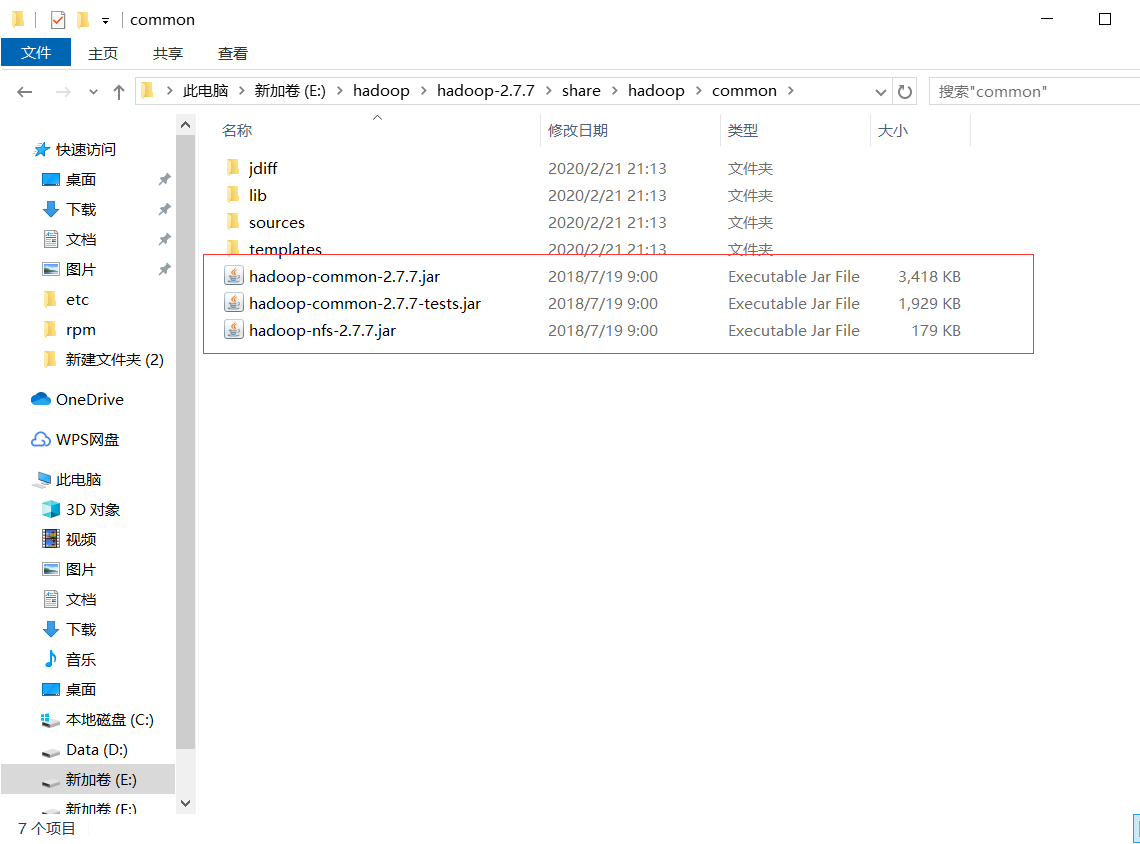
2.查看文件信息
@Test
public void readListFiles() throws Exception {
// 1 创建配置信息对象
Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),configuration, "root"); // 思考:为什么返回迭代器,而不是List之类的容器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName()); //路径
System.out.println(fileStatus.getBlockSize()); //块
System.out.println(fileStatus.getPermission()); //权限
System.out.println(fileStatus.getLen()); //文件大小
System.out.println(fileStatus.isFile()); //是不是一个文件
System.out.println(fileStatus.isDirectory()); //是不是一个目录 BlockLocation[] blockLocations = fileStatus.getBlockLocations(); for (BlockLocation bl : blockLocations) { System.out.println("block-offset:" + bl.getOffset()); String[] hosts = bl.getHosts(); for (String host : hosts) {
System.out.println(host);
}
} System.out.println("----------------------------");
}
}
3.文件下载(get)
@Test
public void download() {
Configuration conf=new Configuration();
try
{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),conf);
FSDataInputStream in = fileSystem.open(new Path("/upload.txt"));
FileOutputStream out = new FileOutputStream(new File("d://lib//updoad.txt"));
byte[]b=new byte[1024];
int len=0;
while((len=in.read(b))!=-1) {
out.write(b,0,len);
}
in.close();
out.close();
} catch (IOException | URISyntaxException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
} }
4.上传文件(create)
@Test
public void upload() {
Configuration conf=new Configuration();
try
{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),conf);
FSDataOutputStream out = fileSystem.create(new Path("/jetbrains-agent.jar"));
FileInputStream in=new FileInputStream(new File("d:\\jetbrains-agent.jar"));
byte[]b=new byte[10240];
int len=0;
while((len=in.read(b))!=-1) {
out.write(b,0,len);
}
in.close();
out.close();
} catch (IOException | URISyntaxException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
5.重命名(rename)
@Test
public void mv() {
Configuration conf=new Configuration();
try
{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),conf);
fileSystem.rename(new Path("/hdp01"), new Path("/HDP01"));
fileSystem.close();
} catch (IOException | URISyntaxException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
6.文件夹删除
@Test
public void deleteAtHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),configuration, "root"); //2 删除文件夹 ,如果是非空文件夹,参数2是否递归删除,true递归
fs.delete(new Path("hdfs://192.168.0.xxx:9000/upload/output"), true);
}
7.创建文件夹
@Test
public void mkdirAtHDFS() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),configuration, "root"); //2 创建目录
fs.mkdirs(new Path("hdfs://192.168.0.xxx:9000/upload/output"));
}
8.遍历所有文件状态
@Test
public void findAtHDFS() throws Exception, IllegalArgumentException, IOException{ // 1 创建配置信息对象
Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.0.xxx:9000"),configuration, "root"); // 2 获取查询路径下的文件状态信息
FileStatus[] listStatus = fs.listStatus(new Path("/")); // 3 遍历所有文件状态
for (FileStatus status : listStatus) {
if (status.isFile()) {
System.out.println("f--" + status.getPath().getName());
} else {
System.out.println("d--" + status.getPath().getName());
}
}
}
Hadoop的FlieSystem类的使用的更多相关文章
- Hadoop之TaskInputOutputContext类
在MapReduce过程中,每一个Job都会被分成若干个task,然后再进行处理.那么Hadoop是怎么将Job分成若干个task,并对其进行跟踪处理的呢?今天我们来看一个*Context类——Tas ...
- Hadoop之TaskAttemptContext类和TaskAttemptID类
先来看看TaskAttemptContext的类图 : Figure1:TaskAttemptContext类图 用户向Hadoop提交Job(作业),Job在JobTracker对象的控制下执行.J ...
- hadoop中Text类 与 java中String类的区别
hadoop 中 的Text类与java中的String类感觉上用法是相似的,但两者在编码格式和访问方式上还是有些差别的,要说明这个问题,首先得了解几个概念: 字符集: 是一个系统支持的所有抽象字符的 ...
- Hadoop中Writable类之四
1.定制Writable类型 Hadoop中有一套Writable实现,例如:IntWritable.Text等,但是,有时候可能并不能满足自己的需求,这个时候,就需要自己定制Writable类型. ...
- Hadoop中Writable类之三
1.BytesWritable <1>定义 ByteWritable是对二进制数据组的封装.它的序列化格式为一个用于指定后面数据字节数的整数域(4个字节),后跟字节本身. 举个例子,假如有 ...
- Hadoop中Writable类之二
1.ASCII.Unicode.UFT-8 在看Text类型的时候,里面出现了上面三种编码,先看看这三种编码: ASCII是基于拉丁字母的一套电脑编码系统.它主要用于显示现代英语和其他西欧语言.它是现 ...
- hadoop之mapper类妙用
1. Mapper类 首先 Mapper类有四个方法: (1) protected void setup(Context context) (2) Protected void map(KEYIN k ...
- Hadoop中Writable类
1.Writable简单介绍 在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的or ...
- 琐碎-关于hadoop的GenericOptionsParser类
GenericOptionsParser 命令行解析器 是hadoop框架中解析命令行参数的基本类.它能够辨别一些标准的命令行参数,能够使应用程序轻易地指定namenode,jobtracker,以及 ...
随机推荐
- P1006 换个格式输出整数
这道题相较于上一题来说就简单了许多.看题. 怎么感觉这道题有点类似P1002写出这个数.流程差不多,思路大致是先求出每一位上的数,然后根据 百十个 的顺序输出结果.题目比较简单,不做赘述,贴代码 代码 ...
- P1003 我要通过!
转跳点:
- NRF51822和NRF52832的主要区别
对于NRF51822和NRF52832的选择性相信大家也是非常困惑的,哪个性价比高?下面为大家讲下NRF51822和NRF52832的一个区别,让大家能够更好的快速选型加快研发产品进度! 主要分为 ...
- dede开启会员功能
登陆后台,找到菜单里面的系统基本参数设置>会员设置>开启会员功能,选择“是”,保存即可
- border-radius 在 浏览器开发者工具移动端里是有效的,在真机是无效的。
border-radius 在 浏览器开发者工具移动端里是有效的,在真机是无效的,怎么解决? 答案是 border-radius:20px !important 加上!important 就好了.
- VMware虚拟机黑屏
引用自:VMware吧 近期很多朋友遇到了VMware Workstation 14开启或新建虚拟机后黑屏的现象,无法关机,软件也无法关闭 用任务管理器结束VMware后这个VMX进程也关不了 解决办 ...
- 逆向-PE导出表
PE-导出表 动态链接库要想给别人用实现加载时或运行时链接就必须提供函数和数据的地址.exe一般不会有这个,大部分是DLL文件的.导出分为名字导出和序号导出. 名字导出先找名字,再通过名字表的索引 ...
- vue学习(八)nextTick[异步更新队列]的使用和应用
nextTick的使用 为了数据变化之后等待vue完成更新DOM,可以在数据变化之后立即使用Vue.nextTick()在当前的回调函数中能获取最新的DOM <div id="app& ...
- c++程序—浮点数
#include<iostream> using namespace std; int main() { //2.单精度float //3.双精度double //默认情况下会输出6位有效 ...
- python---函数定义、调用、参数
1.函数定义和调用 下面def test部分的代码块是函数定义:test(2,3)则是函数调用 def test(a,b): print(a) print(b) test(,) 2.必填参数,即函数调 ...