Hadoop Compression
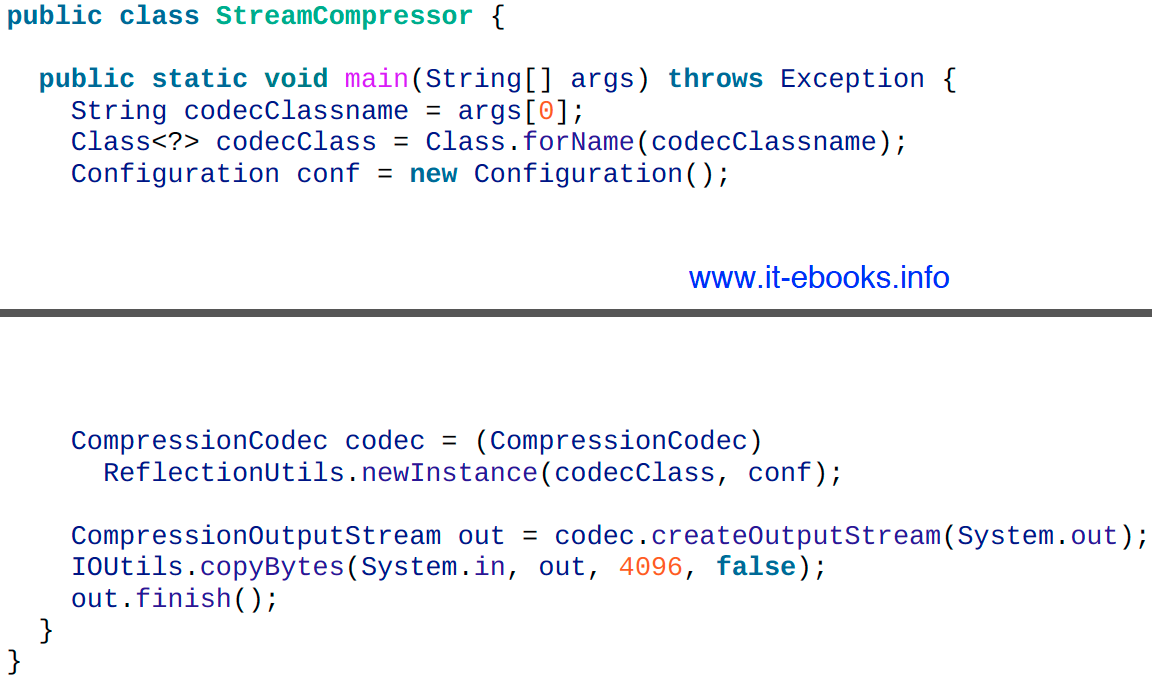
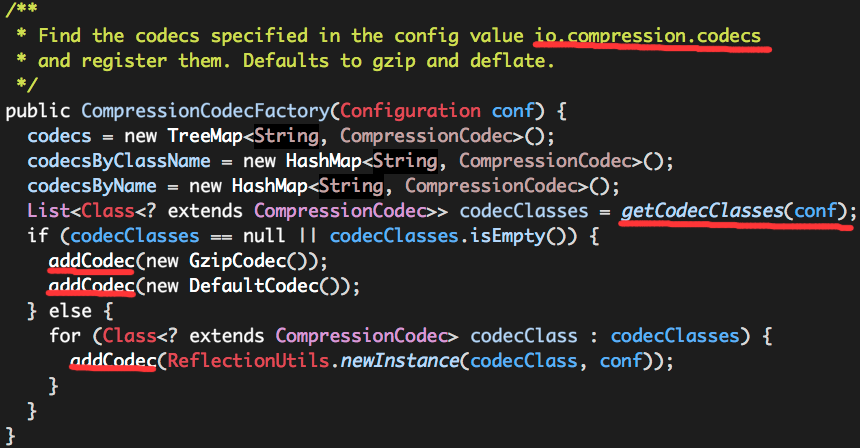
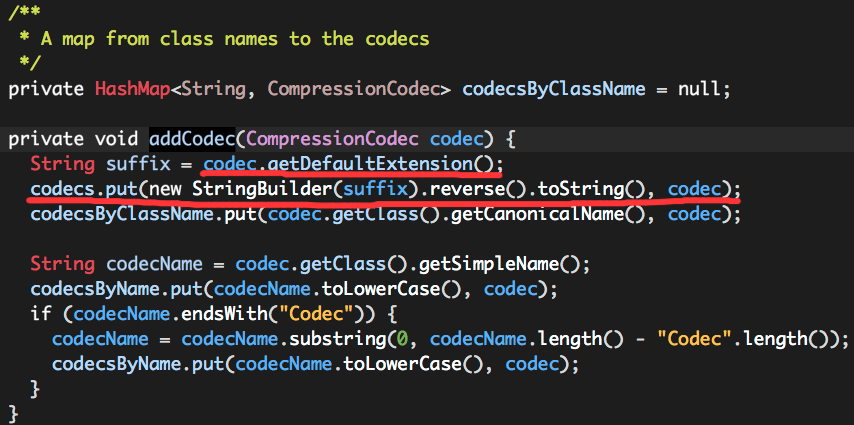
public interface CompressionCodec {
CompressionOutputStream createOutputStream(OutputStream out) throws IOException;
CompressionOutputStream createOutputStream(OutputStream out, Compressor compressor) throws IOException;
Class<? extends Compressor> getCompressorType();
Compressor createCompressor();
CompressionInputStream createInputStream(InputStream in) throws IOException;
CompressionInputStream createInputStream(InputStream in, Decompressor decompressor) throws IOException;
Class<? extends Decompressor> getDecompressorType();
Decompressor createDecompressor();
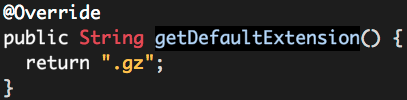
String getDefaultExtension();
}




Hadoop Compression的更多相关文章
- Spark on Yarn出现hadoop.compression.lzo.LzoCodec not found问题发现及解决
问题描述: spark.SparkContext: Created broadcast 0 from textFile at WordCount.scala:37 Exception in threa ...
- [Compression] Hadoop 压缩
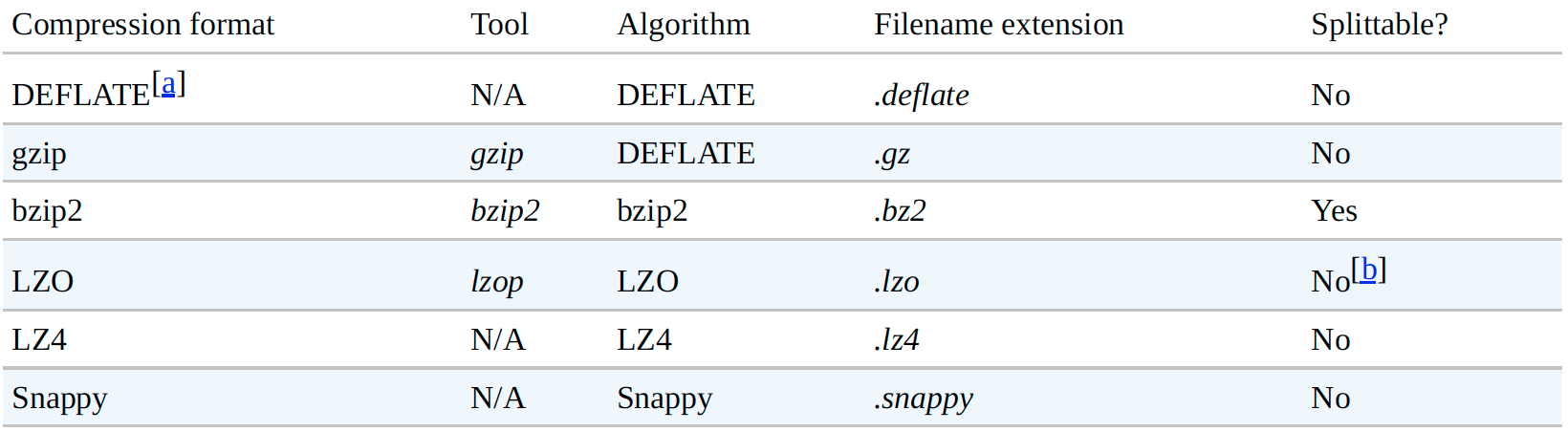
0. 说明 Hadoop 压缩介绍 && 压缩格式总结 && 压缩编解码器测试 1. 介绍 [文件压缩的好处] 文件压缩的好处如下: 减少存储文件所需要的磁盘空间 加速 ...
- hadoop安装遇到的各种异常及解决办法
hadoop安装遇到的各种异常及解决办法 异常一: 2014-03-13 11:10:23,665 INFO org.apache.hadoop.ipc.Client: Retrying connec ...
- Hadoop安装lzo实验
参考http://blog.csdn.net/lalaguozhe/article/details/10912527 环境:hadoop2.3cdh5.0.2 hive 1.2.1 目标:安装lzo ...
- hadoop core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text ...
- Hadoop配置文件
部分内容参考:http://www.linuxqq.net/archives/964.html http://slaytanic.blog.51cto.com/2057708/1100974/ ht ...
- Hadoop使用lzo压缩格式
在hadoop中搭建lzo环境: wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz export CFLAGS ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
- [大牛翻译系列]Hadoop(20)附录A.10 压缩格式LZOP编译安装配置
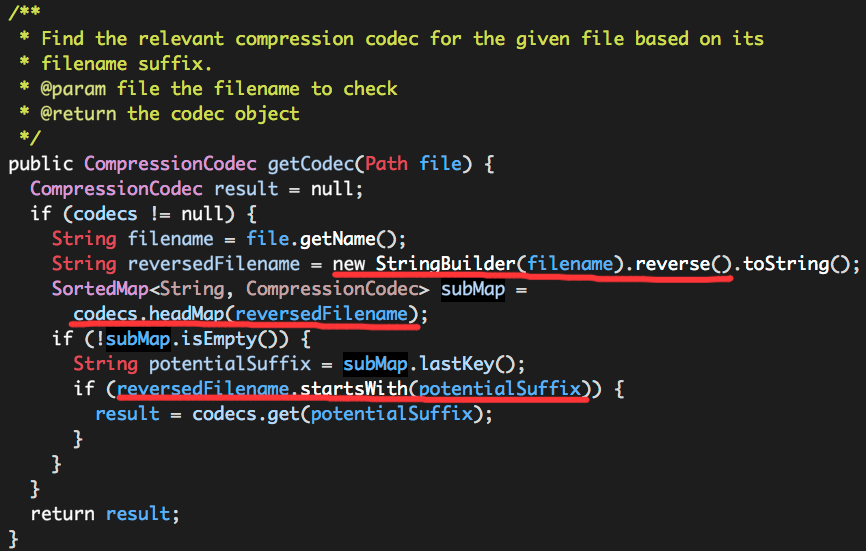
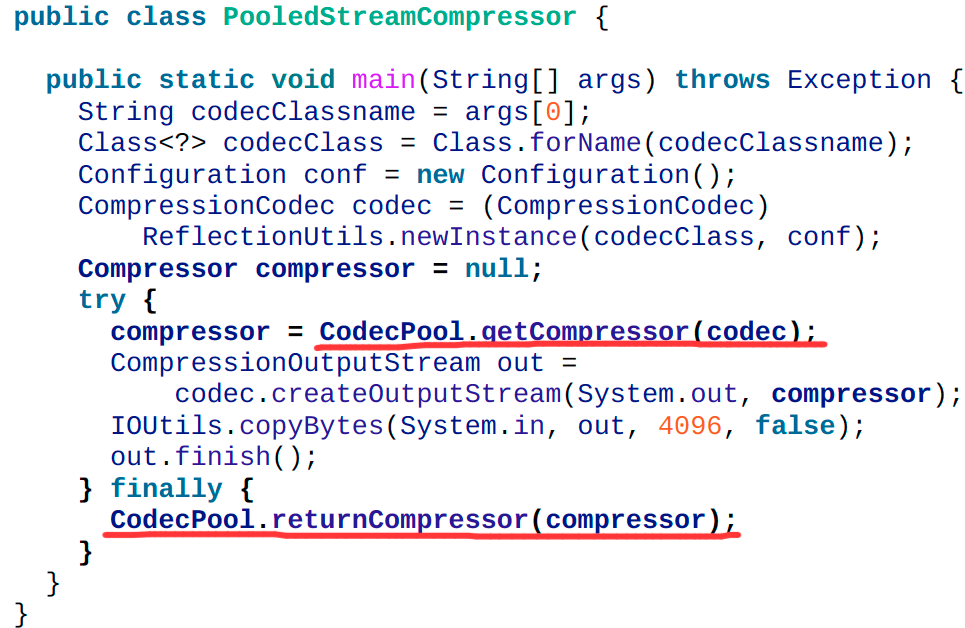
附录A.10 LZOP LZOP是一种压缩解码器,在MapReduce中可以支持可分块的压缩.第5章中有一节介绍了如何应用LZOP.在这一节中,将介绍如何编译LZOP,在集群做相应配置. A.10.1 ...
随机推荐
- 第四篇:SQL
前言 确实,关于SQL的学习资料,各类文档在网上到处都是.但它们绝大多数的出发点都局限在旧有关系数据库里,内容近乎千篇一律.而在当今大数据的浪潮下,SQL早就被赋予了新的责任和意义. 本篇中,笔者将结 ...
- Android中使用HttpGet和HttpPost访问HTTP资源
需求:用户登录(name:用户名,pwd:密码) (一)HttpGet :doGet()方法//doGet():将参数的键值对附加在url后面来传递 public String getResultFo ...
- Ajax 如何提交集合到mvc后台
1,前端请求如下 var apply = { CompanyName: $("[name='corpName']").val(), ContactUser: $("[na ...
- gulp初涉
1.什么是gulp? gulp是前端开发过程中一种基于流的代码构建工具,是自动化项目的构建利器:它不仅能对网站资源进行优化,而且在开发过程中很多重复的任务能够使用正确的工具自动完成:使用它,不仅可以很 ...
- (转)DEDECMS模板原理、模板标签学习 - .Little Hann
本文,小瀚想和大家一起来学习一下DEDECMS中目前所使用的模板技术的原理: 什么是编译式模板.解释式模板,它们的区别是什么? 模板标签有哪些种类,它们的区别是什么,都应用在哪些场景? 学习模板的机制 ...
- Activity之间的数据传递(Arraylist)
1.使用Serialiable方法 实现序列化 2.使用Parcelable方法(这是android自己封装的类) Parcel类是封装数据的容器,封装后的数据通过Intent和IPC传递 实 ...
- singleTask TaskAffinity allowTaskReparenting
关于singleTask TaskAffinity allowTaskReparenting 一.Activity的LaunchMode 1.standard 2.singleTop:FLAG_ACT ...
- Jquery 操作 select
1.判断select选项中 是否存在Value="paraValue"的Item $("#selectid option[@value='paraValue']" ...
- CSS3重要内容翻译
以上是废话 1.3 此处未完全确认,相较于css3和css3的选择器,区别包括: 基础定义改变(选择器.选择器组,简单选择器等),特别的,作为css2中简单选择器,如今被成为简单选择器序列,“简 ...
- chromedriver 与 chrome关联关系
----------ChromeDriver v2.22 (2016-06-06)---------- Supports Chrome v49-52 Resolved issue 1348: Time ...