5 kafka整合storm
本博文的主要内容有
.kafka整合storm
.storm-kafka工程
.storm + kafka的具体应用场景有哪些?

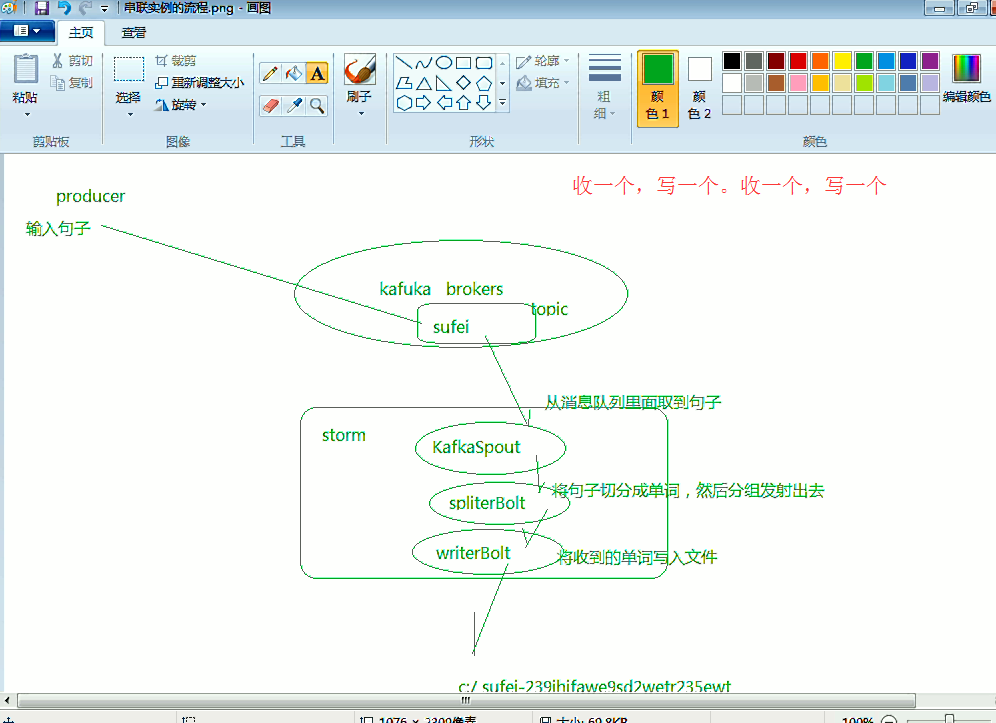
要想kafka整合storm,则必须要把这个storm-kafka-0.9.2-incubating.jar,放到工程里去。
无非,就是storm要去拿kafka里的东西,


storm-kafka工程
我们自己,在storm-kafka工程里,写,
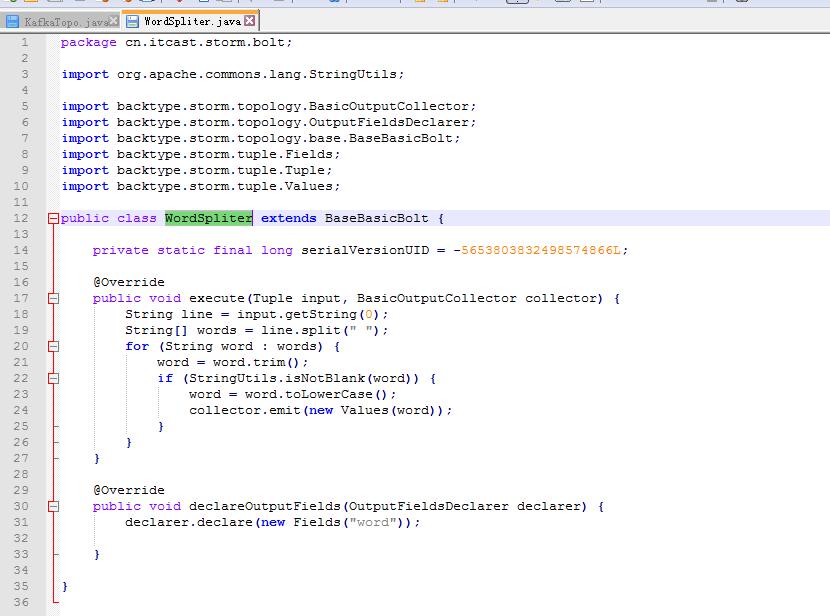
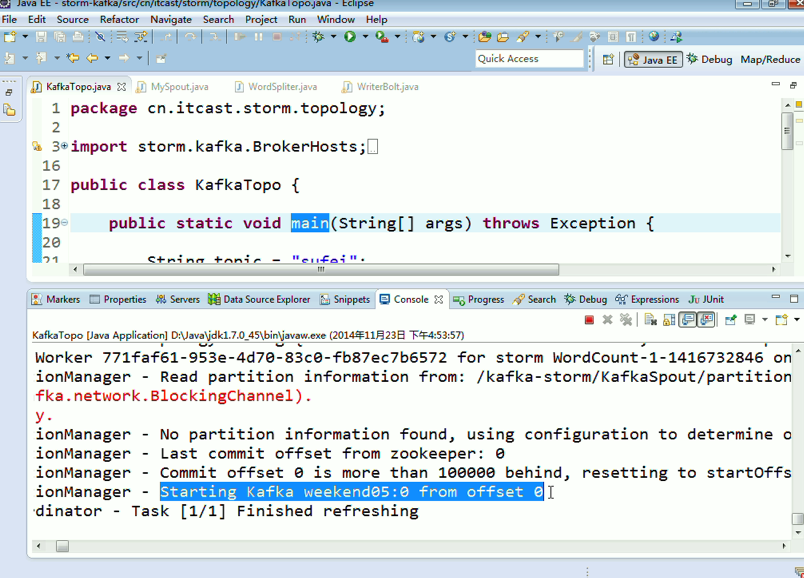
KafkaTopo.java、 WordSpliter.java、WriterBolt.java、
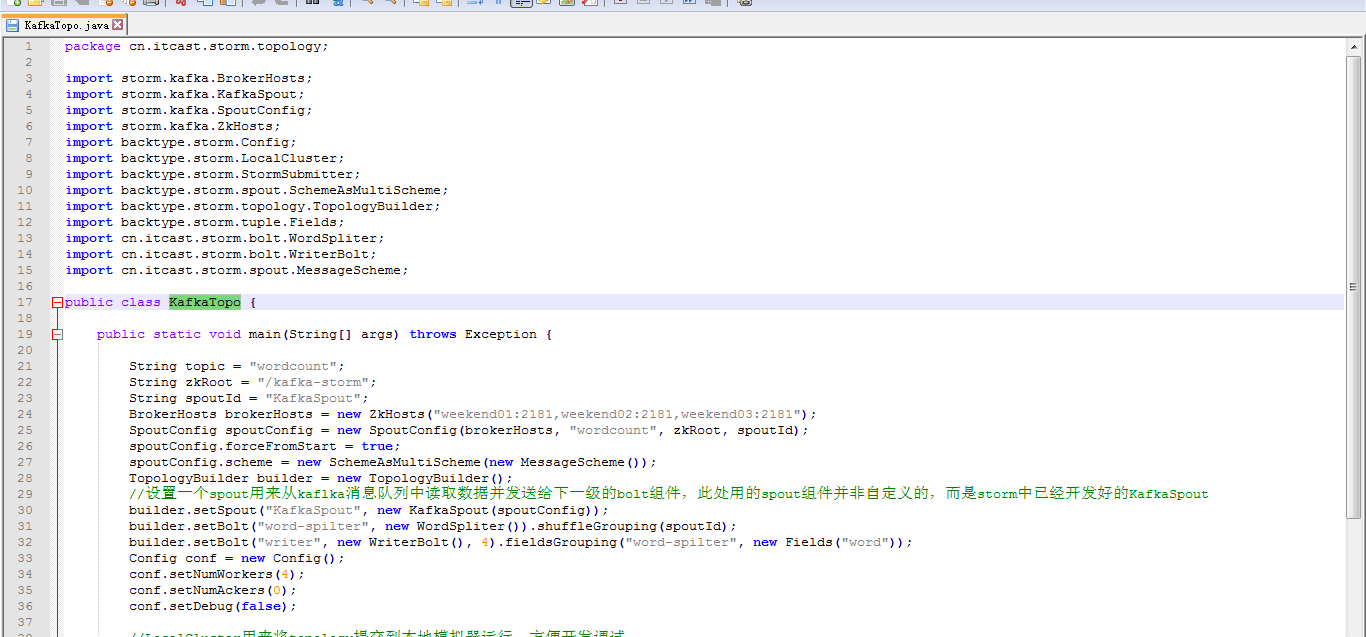

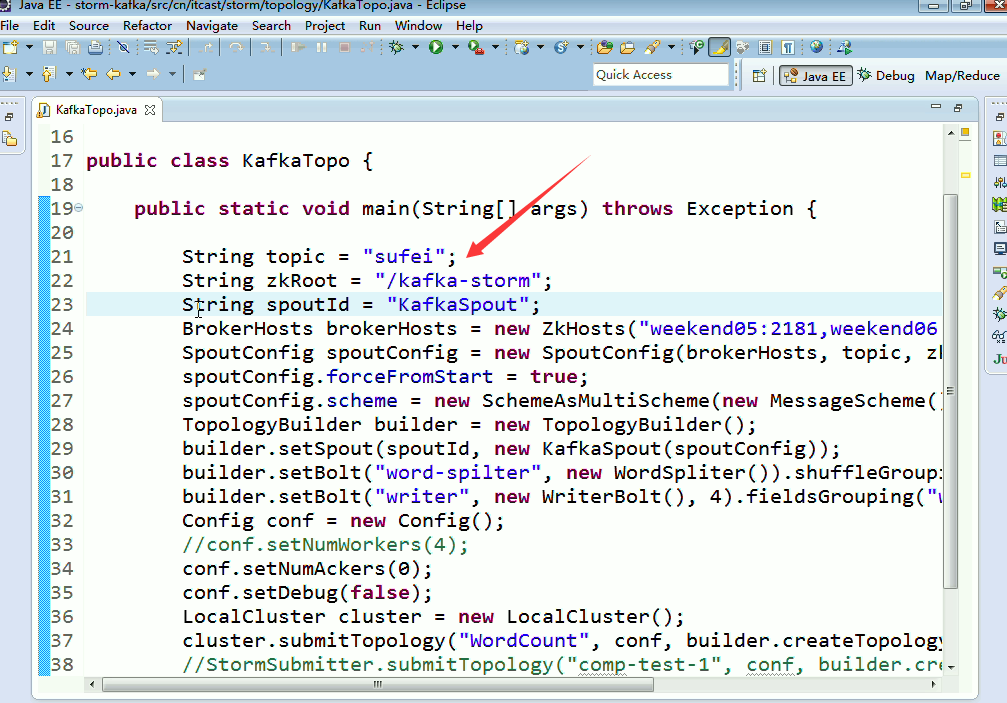
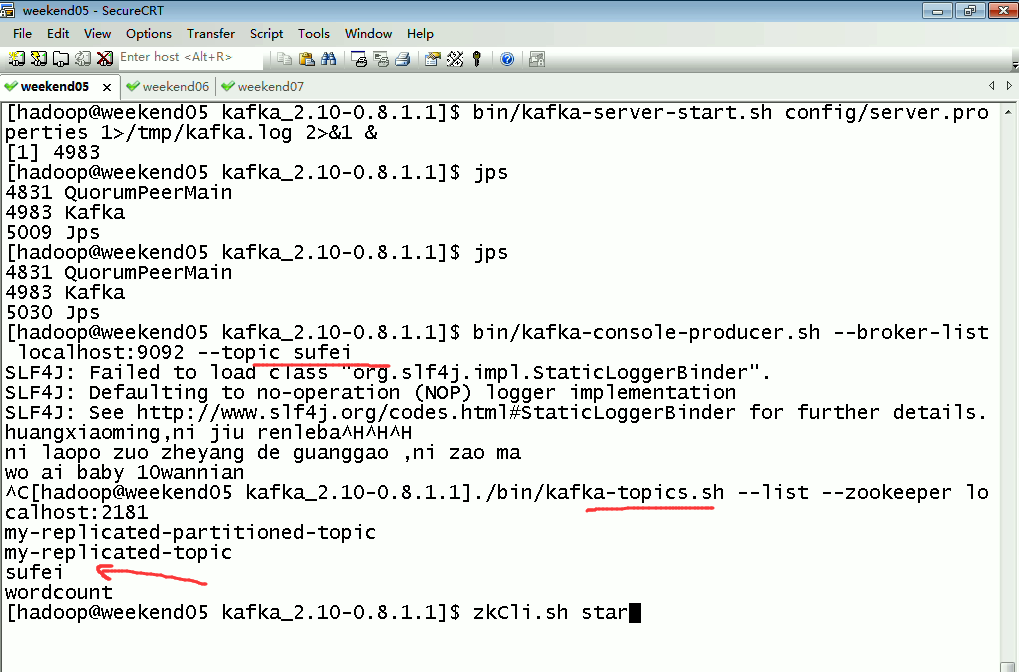
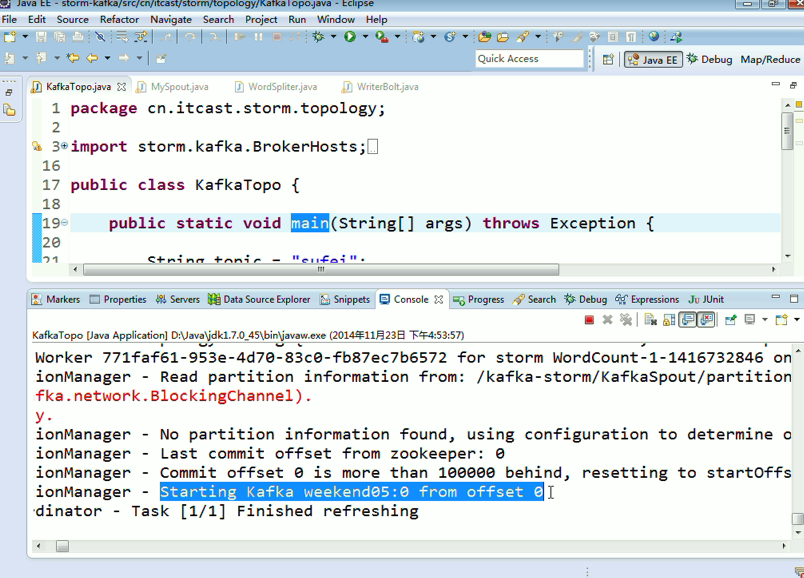
这里,把话题wordcount改为,sufei,即可。









KafkaTopo.java
package cn.itcast.storm.topology;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import cn.itcast.storm.bolt.WordSpliter;
import cn.itcast.storm.bolt.WriterBolt;
import cn.itcast.storm.spout.MessageScheme;
public class KafkaTopo {
public static void main(String[] args) throws Exception {
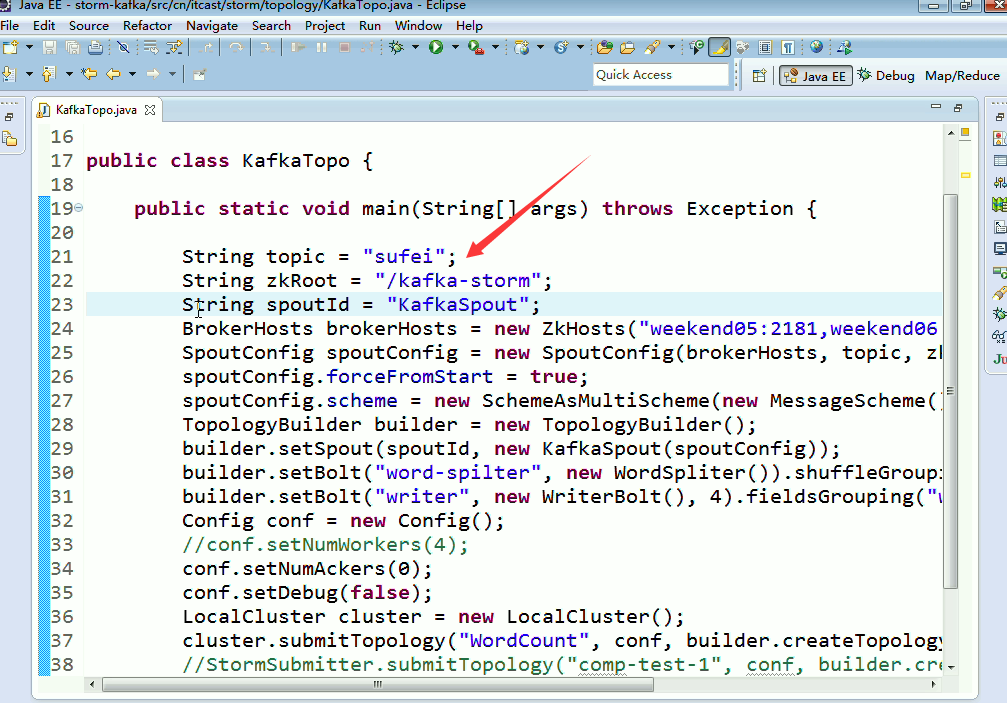
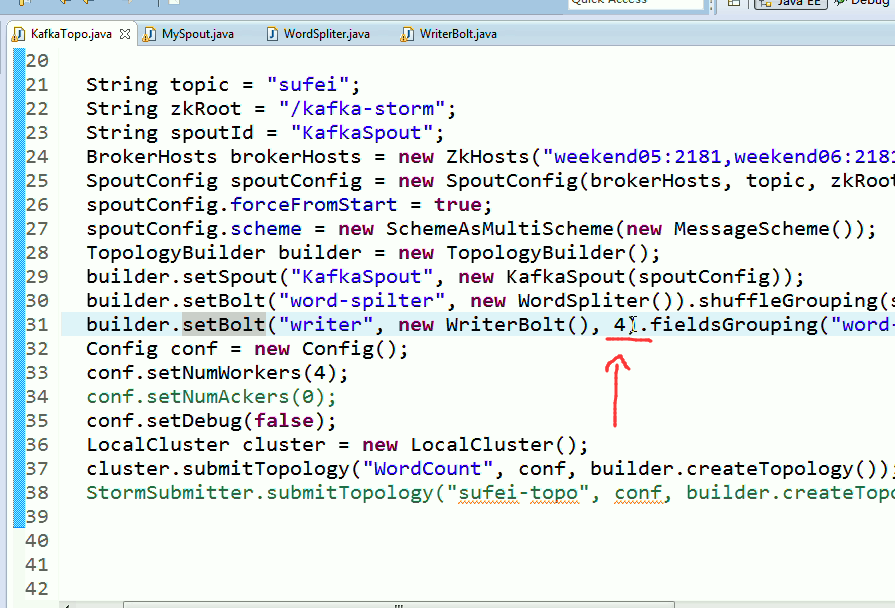
String topic = "wordcount";
String zkRoot = "/kafka-storm";
String spoutId = "KafkaSpout";
BrokerHosts brokerHosts = new ZkHosts("weekend01:2181,weekend02:2181,weekend03:2181");
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "wordcount", zkRoot, spoutId);
spoutConfig.forceFromStart = true;
spoutConfig.scheme = new SchemeAsMultiScheme(new MessageScheme());
TopologyBuilder builder = new TopologyBuilder();
//设置一个spout用来从kaflka消息队列中读取数据并发送给下一级的bolt组件,此处用的spout组件并非自定义的,而是storm中已经开发好的KafkaSpout
builder.setSpout("KafkaSpout", new KafkaSpout(spoutConfig));
builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping(spoutId);
builder.setBolt("writer", new WriterBolt(), 4).fieldsGrouping("word-spilter", new Fields("word"));
Config conf = new Config();
conf.setNumWorkers(4);
conf.setNumAckers(0);
conf.setDebug(false);
//LocalCluster用来将topology提交到本地模拟器运行,方便开发调试
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
//提交topology到storm集群中运行
// StormSubmitter.submitTopology("sufei-topo", conf, builder.createTopology());
}
}
WordSpliter.java
package cn.itcast.storm.bolt;
import org.apache.commons.lang.StringUtils;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordSpliter extends BaseBasicBolt {
private static final long serialVersionUID = -5653803832498574866L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (StringUtils.isNotBlank(word)) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WriterBolt.java
package cn.itcast.storm.bolt;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/**
* 将数据写入文件
*
*
*/
public class WriterBolt extends BaseBasicBolt {
private static final long serialVersionUID = -6586283337287975719L;
private FileWriter writer = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
writer = new FileWriter("c:\\storm-kafka\\" + "wordcount"+UUID.randomUUID().toString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String s = input.getString(0);
try {
writer.write(s);
writer.write("\n");
writer.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
storm + kafka的具体应用场景有哪些?
手机位置的,在基站的实时轨迹分析。
Storm,是可以做实时分析,但是你,若没有个消息队列的话,你那消息,当storm死掉之后,中间那段时间,消息都没了。而,你若采用storm + kafka,则把那中间段时间的消息缓存下。
初步可以这么理解,storm + kafka,把kafka理解为缓存,只不过这个缓存,可以分区域。实际上,处理业务逻辑的是,storm。
5 kafka整合storm的更多相关文章
- SpringBoot整合Kafka和Storm
前言 本篇文章主要介绍的是SpringBoot整合kafka和storm以及在这过程遇到的一些问题和解决方案. kafka和storm的相关知识 如果你对kafka和storm熟悉的话,这一段可以直接 ...
- 大数据入门第十八天——kafka整合flume、storm
一.实时业务指标分析 1.业务 业务: 订单系统---->MQ---->Kakfa--->Storm 数据:订单编号.订单时间.支付编号.支付时间.商品编号.商家名称.商品价格.优惠 ...
- storm和kafka整合
storm和kafka整合 依赖 <dependency> <groupId>org.apache.storm</groupId> <artifactId&g ...
- Flume+Kafka整合
脚本生产数据---->flume采集数据----->kafka消费数据------->storm集群处理数据 日志文件使用log4j生成,滚动生成! 当前正在写入的文件在满足一定的数 ...
- flume与kafka整合
flume与kafka整合 前提: flume安装和测试通过,可参考:http://www.cnblogs.com/rwxwsblog/p/5800300.html kafka安装和测试通过,可参考: ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- SparkStreaming+Kafka整合
SparkStreaming+Kafka整合 1.需求 使用SparkStreaming,并且结合Kafka,获取实时道路交通拥堵情况信息. 2.目的 对监控点平均车速进行监控,可以实时获取交通拥堵情 ...
- Spring Kafka整合Spring Boot创建生产者客户端案例
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 创建一个kafka-producer-master的maven工程.整个项目结构如下: ...
- ambari下的flume和kafka整合
1.配置flume #扫描指定文件配置 agent.sources = s1 agent.channels = c1 agent.sinks = k1 agent.sources.s1.type=ex ...
随机推荐
- .NET 设计模式之简单工厂模式(二)
1:建立接口 namespace Factory { public interface IPerson { } } 2:建立Worker.Student来继承IPerson接口 namespace F ...
- Python:列表
#!/usr/bin/python3 #列表 是可变的,可修改的 listDemo = ["one","two","three"," ...
- java-成员变量的属性与成员函数的覆盖
java中在多态的实现是通过类的继承或者接口的实现来完成的. 在类继承或者接口实现过程中就会涉及到成员属性以及成员函数的重写,需要注意的是,成员函数的重写是直接覆盖父类的(继承中),但是成员变量重写是 ...
- Eclipse debug调试
Eclipse debug调试: F5:跳入方法F6:向下逐行调试F7:跳出方法F8:直接跳转到下一个断点
- 『重构--改善既有代码的设计』读书笔记----Change Reference to Value
如果你有一个引用对象,很小且不可改变,而且不易管理,你就需要考虑将他改为一个值对象.在Change Value to Reference我们说过,要在引用对象和值对象之间做选择,有时候并不容易,有了重 ...
- 深入了解jquery中的键盘事件
很多时候,我们需要获取用户的键盘事件,下面就一起来看看jquery是如何操作键盘事件的. 一.首先需要知道的是: 1.keydown() keydown事件会在键盘按下时触发. 2.keyup() k ...
- php练习——打印半金字塔、金字塔、空心金字塔、菱形、空心菱形
半金字塔 金字塔 空心金字塔 菱形 空心菱形
- Lsp修复
打开电脑,进入命令提示符窗口,快捷键win+r. 在窗口中输入“cmd”进入命令符窗口. 在窗口中输入:输入netsh winsock reset,然后按下回车键. 然后稍等片刻, ...
- Android内的生命周期整理
1. Android App的生命周期: 2. Application的生命周期: 3. Activity的生命周期: 3.1 Fragment的生命周期: 4. Service的生命周期:5. Br ...
- python入门笔记第一天
查询acsii命令 ord(‘A’) 导入模块python执行系统命令显示文件.查找文件方法1import osa = os.popen('目标').read()a 解释output = os.pop ...