node.js基础模块http、网页分析工具cherrio实现爬虫
node.js基础模块http、网页分析工具cherrio实现爬虫
一、前言
说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http、网页分析工具cherrio。 使用http直接获取url路径对应网页资源,然后使用cherrio分析。 这里我主要学习过的案例自己敲了一遍,加深理解。在coding的过程中,我第一次把jq获取后的对象直接用forEach遍历,直接报错,是因为jq没有对应的这个方法,只有js数组可以调用。
二、知识点
①:superagent抓去网页工具。我暂时未用到。
②:cherrio 网页分析工具,你可以理解其为服务端的jQuery,因为语法都一样。
效果图
1、抓取整个网页
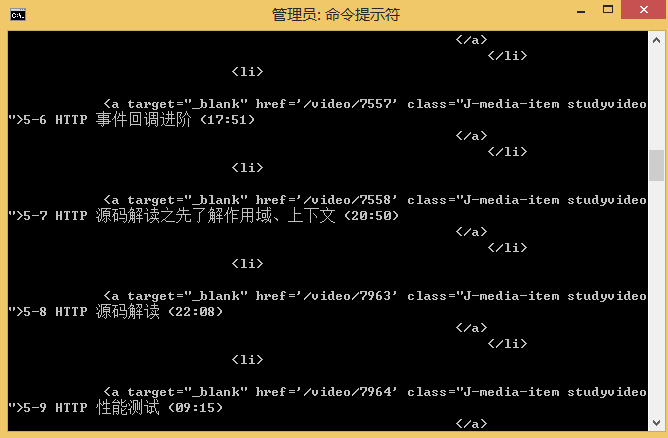
2、分析后的数据,提供的示例为案例实现的例子。
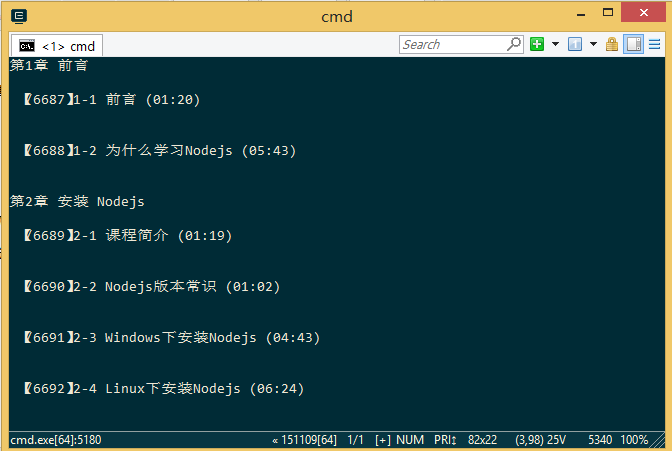
爬虫初探源码分析
var http=require('http');
var cheerio=require('cheerio');
var url='http://www.imooc.com/learn/348';
/****************************
打印得到的数据结构
[{
chapterTitle:'',
videos:[{
title:'',
id:''
}]
}]
********************************/
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle=item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(video){
console.log(' 【'+video.id+'】'+video.title+'\n');
})
});
}
/*************
分析从网页里抓取到的数据
**************/
function filterChapter(html){
var courseData=[];
var $=cheerio.load(html);
var chapters=$('.chapter');
chapters.each(function(item){
var chapter=$(this);
var chapterTitle=chapter.find('strong').text(); //找到章节标题
var videos=chapter.find('.video').children('li');
var chapterData={
chapterTitle:chapterTitle,
videos:[]
};
videos.each(function(item){
var video=$(this).find('.studyvideo');
var title=video.text();
var id=video.attr('href').split('/video')[1];
chapterData.videos.push({
title:title,
id:id
})
})
courseData.push(chapterData);
});
return courseData;
}
http.get(url,function(res){
var html='';
res.on('data',function(data){
html+=data;
})
res.on('end',function(){
var courseData=filterChapter(html);
printCourseInfo(courseData);
})
}).on('error',function(){
console.log('获取课程数据出错');
})
参考资料:
https://github.com/alsotang/node-lessons/tree/master/lesson3
node.js基础模块http、网页分析工具cherrio实现爬虫的更多相关文章
- Node.js Web模块
什么是Web服务器? Web服务器是处理由HTTP客户端发送的,如web浏览器的HTTP请求的软件应用程序,并返回响应于客户端网页. Web服务器通常伴随着图片,样式表和脚本的HTML文档. 大多数W ...
- Node.js基础知识
Node.js入门 Node.js Node.js是一套用来编写高性能网络服务器的JavaScript工具包,一系列的变化由此开始.比较独特的是,Node.js会假设在POSIX环境下运行 ...
- 进击Node.js基础(二)
一.一个牛逼闪闪的知识点Promise npm install bluebird 二.Promise实例 ball.html <!doctype> <!DOCTYPE html> ...
- Node.js之模块机制
> 文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号.  ...
随机推荐
- Java基础知识强化之集合框架笔记42:Set集合之LinkedHashSet的概述和使用
1. LinkedHashSet类的概述: • 元素有序唯一 • 由链表保证元素有序 • 由哈希表保证元素唯一 2. 代码示例: package cn.itcast_04; import java.u ...
- Markdown写接口文档,自动添加TOC
上回说到,用Impress.js代替PPT来做项目展示.这回换Markdown来做接口文档好了.(不敢说代替Word,只能说个人感觉更为方便)当然,还要辅之以Git,来方便版本管理. Markdown ...
- hdu 5073 Galaxy
题意是给定n个点,让求找到一个点p使得sigma( (a[i] - p) ^ 2 ) 最小,其中a[i]表示第i个点的位置.其中有k个点不用算. 思路:发现这道题其实就是求n-k个点方差. 那么推一下 ...
- C# 内存管理优化畅想(二)---- 巧用堆栈
这个优化方法比较易懂,就是对于仅在方法内部用到的对象,不再分配在堆上,而是直接在栈上分配,方法结束后立即回收,这将大大减轻GC的压力. 其实,这个优化方法就是java里的逃逸分析,不知为何.net里没 ...
- hibernate之增删改查demo
package dao; import java.util.ArrayList; import java.util.List; import org.hibernate.Query; import o ...
- Length 和 Width在矩形中的定义.
Length is the longer or longest dimension of a rectangle (or even an object). Ref:http://mathforum.o ...
- GridView中某一列值的总和(web)
protected void GridView1_RowDataBound(object sender, GridViewRowEventArgs e) { if (e.Row.R ...
- mksquash_lzma-3.2 编译调试记录
今天在编译mksquash_lzma-3.2的时候出现了如下问题: /home/test/RT288x_SDK/toolchain/mksquash_lzma-3.2/lzma443/C/7zip/C ...
- Express在windows IIS上部署详解
最近公司在用Express+angularjs+wcf开发系统,让我在windows上部署系统,遇到不少问题,不过最后还是解决了,在IIS上部署系统, 首先windows需安装以下软件: 1.node ...
- [转]Delphi中ShellExecute的妙用
Delphi中ShellExecute的妙用 ShellExecute的功能是运行一个外部程序(或者是打开一个已注册的文件.打开一个目录.打印一个文件等等),并对外部程序有一定的控制. ...