Centos下装eclipse测试Hadoop
(一),安装eclipse
1,下载eclipse,点这里
2,将文件上传到Centos7,可以用WinSCP
3,解压并安装eclipse
[root@Master opt]# tar zxvf '/home/s/eclipse-jee-neon-1a-linux-gtk-x86_64.tar.gz' -C/opt ---------------> 建立文件:[root@Master opt]# mkdir /usr/bin/eclipse ------------------》添加链接,即快捷方式:[root@Master opt]# ln -s /opt/eclipse/eclipse /usr/bin/eclipse -----------》点击eclipse,即可启动了
(二),建立Hadoop项目
1,下载hadoop plugin 2.7.3 链接:http://pan.baidu.com/s/1i5yRyuh 密码:ms91
2,解压上述jar包插件,放到eclipse中plugins中,并重启eclipse
2, 在eclipse中加载dfs库,点击Windows 工具栏-------->选择show view如图:
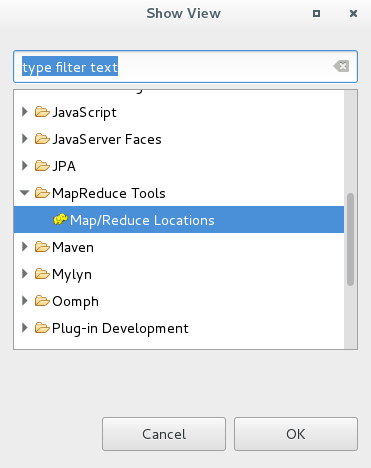
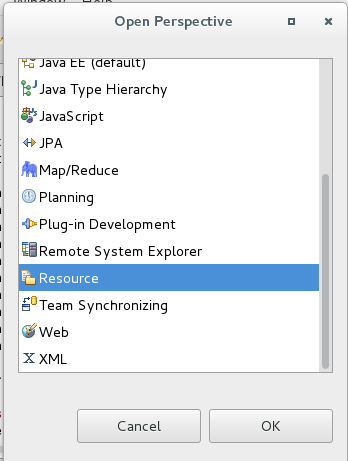
2,打开resource 点击Window ----->Perspective----------->open Perspective 选择resource:
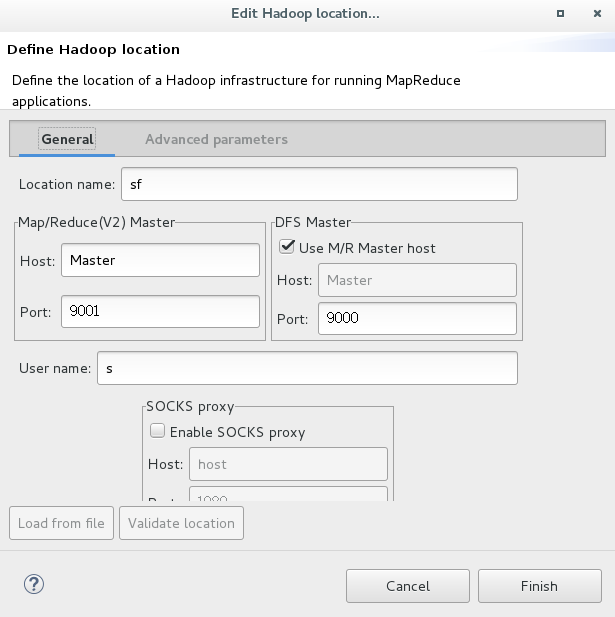
3,配置连接端口,点击eclipse下放的MapResource Location,点击添加:其中port号按照hdfs-site.xml 和core-site.xml来填写。
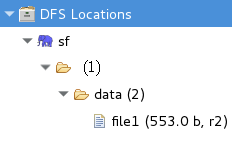
4,上传输入文件:使用hdfs dfs -put /home/file1 /data 即可在eclipse中看到如下:(要确保各个机器的防火墙都关闭,出现异常可以暂时不用关,后面跑下例子就全没了,呵呵)
(三),测试WordCount程序
1,新建项目:点击new ------------》project ----------->Map Reduce,如图:
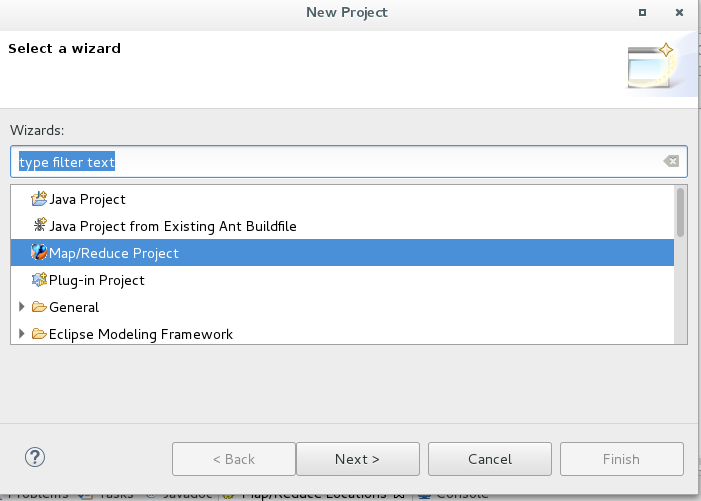
2,给项目配置本地的hadoop文件,圆圈处写本地hadoop的路径:
3,新建个mappert类,写如下代码:
package word; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class mapper { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(otherArgs.length);
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(mapper.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.out.print("ok");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
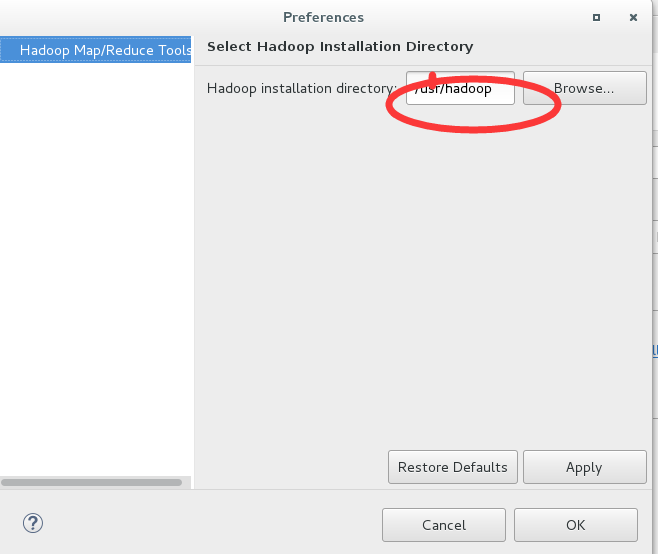
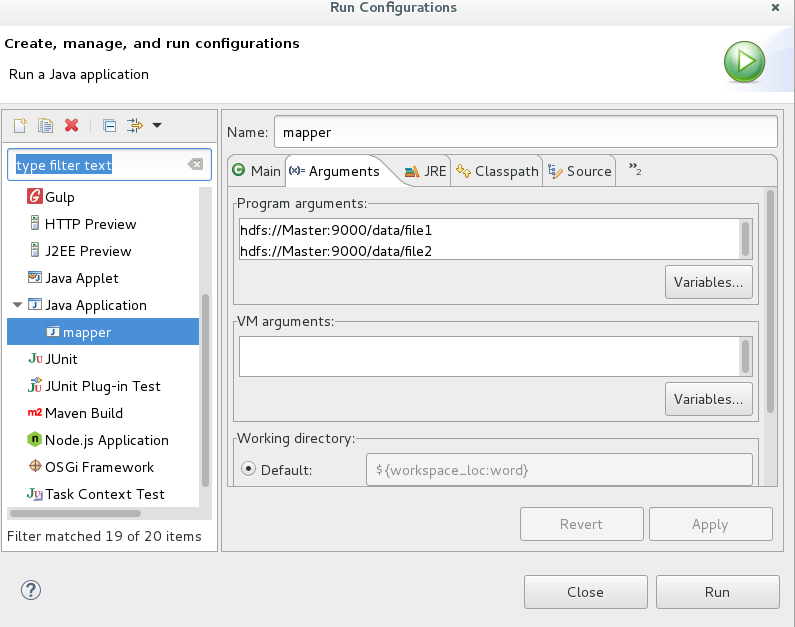
2,点击run as ------------>RunConfigurations ---------->设置input和output文件参数
3,点击run,查看结果
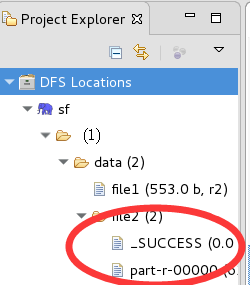
文件的内容:
Centos下装eclipse测试Hadoop的更多相关文章
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- 基于Eclipse搭建Hadoop源码环境
Hadoop使用ant+ivy组织工程,无法直接导入Eclipse中.本文将介绍如何基于Eclipse搭建Hadoop源码环境. 准备工作 本文使用的操作系统为CentOS.需要的软件版本:hadoo ...
- Eclipse导入Hadoop源码项目及编写Hadoop程序
一 Eclipse导入Hadoop源码项目 基本步骤: 1)在Eclipse新建一个java项目[hadoop-1.2.1] 2)将Hadoop压缩包解压目录src下的core,hdfs,mapred ...
- Centos 7 配置单机Hadoop
Centos 7 配置单机Hadoop 2018年10月11日 09:48:13 GT_Stone 阅读数:82 系统镜像:CentuOS-7-x86_64-Everything-1708 Jav ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 基于Eclipse的Hadoop应用开发环境配置
基于Eclipse的Hadoop应用开发环境配置 我的开发环境: 操作系统ubuntu11.10 单机模式 Hadoop版本:hadoop-0.20.1 Eclipse版本:eclipse-java- ...
- Linux下使用Eclipse开发Hadoop应用程序
在前面一篇文章中介绍了如果在完全分布式的环境下搭建Hadoop0.20.2,现在就再利用这个环境完成开发. 首先用hadoop这个用户登录linux系统(hadoop用户在前面一篇文章中创建的),然后 ...
- 获取hadoop的源码和通过eclipse关联hadoop的源码
一.获取hadoop的源码 首先通过官网下载hadoop-2.5.2-src.tar.gz的软件包,下载好之后解压发现出现了一些错误,无法解压缩, 因此有部分源码我们无法解压 ,因此在这里我讲述一下如 ...
- 【Hadoop测试程序】编写MapReduce测试Hadoop环境
我们使用之前搭建好的Hadoop环境,可参见: <[Hadoop环境搭建]Centos6.8搭建hadoop伪分布模式>http://www.cnblogs.com/ssslinppp/p ...
随机推荐
- 一份关于组建.NET Core开源团队的倡议书
组建这个.NET Core开源团队,旨在为社区出一份力,对自己能力也是一个提升,是一个即利于他人,也利于自己的想法和行动.如果你有很多想法,如果你需要认识更多志同道合的朋友,如果你想展示自己的才华,如 ...
- 2005: [Noi2010]能量采集
2005: [Noi2010]能量采集 Time Limit: 10 Sec Memory Limit: 552 MBSubmit: 1831 Solved: 1086[Submit][Statu ...
- wxpython tab切换页面
最近没事学习下wxpython,发现很少有关于页面切换的demo,这边分享下2中切换的方法.第一种:利用wx.Notebook第二种:利用Sizer布局实现(自己写的),代码没有涉及到什么重构之类的优 ...
- kali linux qq 2013
按照网上的教程折腾了好几个小时,都没有搞定的qq for linux 在意外的尝试中成功了 文章有参考网友教程的部分:http://xiao106347.blog.163.com/blog/stati ...
- .NET Core中的包、元包与框架
本文为翻译文章,原文:Packages, Metapackages and Frameworks .NET Core是一个由NuGet包组成的平台.一些产品受益于细粒度包的定义,也有一些受益于粗粒度包 ...
- 关于<context:property-placeholder>的一个有趣现象
转:http://stamen.iteye.com/blog/1926166 先来看下A和B两个模块 A模块和B模块都分别拥有自己的Spring XML配置,并分别拥有自己的配置文件: A模块 A模块 ...
- 深入解读Python的unittest并拓展HTMLTestRunner
unnitest是Python的一个重要的单元测试框架,对于用Python进行开发的同事们可能不需要对他有过深入的了解会用就行,但是,对于自动化测试人员我觉得是要熟知unnitest的执行原理以及相关 ...
- SQL AlawaysOn 之二:添加组织和域用户
1.在管理工具打开Active Directory 用户和计算机 2.在域控制器名称下面右键 选择 新建--组织单位, 3.输入组织名定,点确定 4.在组织右键--新建--用户 5.输入用户信息,点 ...
- iOS开发之使程序在后台运行
方法一(此方法不太可靠): 开启程序后台运行: [application beginBackgroundTaskWithExpirationHandler:^{ //后台运行过期后会调用此block内 ...
- jqzoom插件
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <title> ...