SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
select a.id, a.workflowid,a.operator,a.stepid
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
查询结果:
(1327 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
select a.id,a.workflowid,a.operator ,a.stepid
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
执行结果:
(1327 行受影响)
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
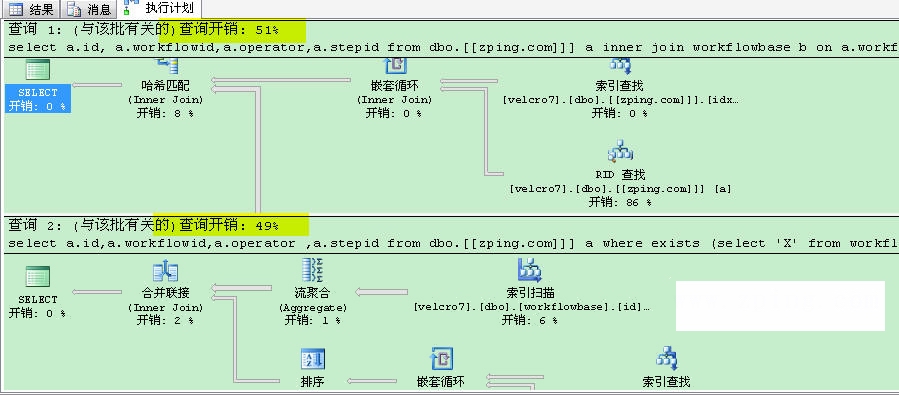
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
select * from workflowbase
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
执行结果:
(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
select * from workflowbase b
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划的更多相关文章
- SQL优化 查询语句中,用 inner join 作为过滤条件和用where作为过滤条件的区别
前段时间遇到一个存储过程,参数之一是一个字符串,在存储过程中,把字符串拆分成一个临时表之后存为一个key值的临时表,作为其中一个查询条件, 逻辑实现上有两种处理方式 insert into #t se ...
- exists改写SQL,使其走正确的执行计划
数据库环境:SQL SERVER 2005 今天看到一条SQL,写得不是很复杂,返回7000多条数据,却执行了15s.SQL文本及各表的数据量如下: SELECT acinv_07.id_item , ...
- 收集统计信息让SQL走正确的执行计划
数据库环境:SQL SERVER 2005 今天在生产库里抓到一条跑得慢的SQL,语句不是很复杂,返回的数据才有800多行, 却执行了34分钟,甚至更久. 先看一下执行结果 我贴一下SQL. SELE ...
- MySQL优化--NOT EXISTS和LEFT JOIN方式差异
在MySQL中,我们可以将NOT EXISTS语句转换为LEFT JOIN语句来进行优化,哪为什么会有性能提升呢? 使用NOT EXISTS方式SQL为: ) FROM t_monitor m WHE ...
- Oracle SQl优化总结
对数据库技术的热爱是我唯一的安慰,毕竟这是自己喜欢的事情,还可以做下去. 因为客户项目的需要,我又开始接触Oracle,大部分工作在工作流的优化和业务数据的排查上.为了更好的做这份工作,我有参考过or ...
- SQL优化注意事项
sql语句优化 性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的 ...
- sql优化点整理
此文是我最早开始sql优化至今整理的小知识点和经常遇到的问题,弄懂这些对优化大型的sql会有不少帮助 ---------------------------------使用了多余的外连接------- ...
- [03] SQL优化
1.SQL优化的实质 充分利用索引: 访问尽量少的数据块: 减少表扫描的I/O次数: 尽量避免全表扫描和其他额外开销: 2.oracle数据库常用的两种优化器 RBO(rule-based-optim ...
- SQL 优化,全
性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的SQL语句,要设 ...
随机推荐
- 网络编程:tcp、udp、socket、struct、socketserver
一.TCP.UDP 一.ARP(Address Resolution Protocol)即地址解析协议,用于实现从 IP 地址到 MAC 地址的映射,即询问目标IP对应的MAC地址. 二.在网络通信中 ...
- 如何在docker和宿主机之间复制文件
如何在docker和宿主机之间复制文件 最近在用Docker布署hadoop,要将文件上传到HDFS首先文件得在Docker容器中吧,网上提供的方法差不多有三种 1.用-v挂载主机数据卷到容器内 ...
- 腾讯云,搭建LAMP服务
lamp (Web应用软件) 编辑 Linux+Apache+Mysql/MariaDB+Perl/PHP/Python一组常用来搭建动态网站或者服务器的开源软件,本身都是各自独立的程序,但是因为常被 ...
- padding填充与box-sizing: border-box配合使用
不管伸缩盒还是浮动盒子,只要使用到padding,就必须使用 box-sizing: border-box; 有图片的时候,需摇与其他文字对齐的时候,在图片的外层加个:vertical-ali ...
- JavaSE 学习笔记之多态(七)
多 态:函数本身就具备多态性,某一种事物有不同的具体的体现. 体现:父类引用或者接口的引用指向了自己的子类对象.//Animal a = new Cat(); 多态的好处:提高了程序的扩展性. 多态的 ...
- 清北学堂模拟赛d5t5 exLCS
分析:比较巧妙的一道题.经典的LCS算法复杂度是O(nm)的,理论上没有比这个复杂度更低的算法,除非题目有一些限制.这道题中两个字符串的长度不一样,f[i][j]如果表示第一个串前i个,第二个串前j个 ...
- [cogs729] [网络流24题#5] 圆桌聚餐 [网络流,最大流,多重二分图匹配]
建图:从源点向单位连边,边权为单位人数,从单位向圆桌连边,边权为1,从圆桌向汇点连边,边权为圆桌容量. #include <iostream> #include <algorithm ...
- EPEL reporsitory
在centos 5上yum install git的时候报错说没有git这个package. 这是因为centos的软件策略非常保守,因为它基本就是redhat企业版的copy.所以想在centos5 ...
- 设计模式->观察者模式
观察者模式能很大的降低模块之前的耦合.详细的观察者模式,客官们能够去看<设计模式>或者<Head first设计模式>等之类的书. 在java中,java.util库中封装了观 ...
- 恳请CSDN的活动可以落实
前言:在CSDN举办的"扒一扒你遇到过最NB开发项目"有奖征文活动中有幸获得"最佳评论奖",可是时至今日.也没有收到书籍,咨询CSDN管理员的时候.居然得到&q ...