SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
select a.id, a.workflowid,a.operator,a.stepid
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
查询结果:
(1327 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
select a.id,a.workflowid,a.operator ,a.stepid
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
执行结果:
(1327 行受影响)
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
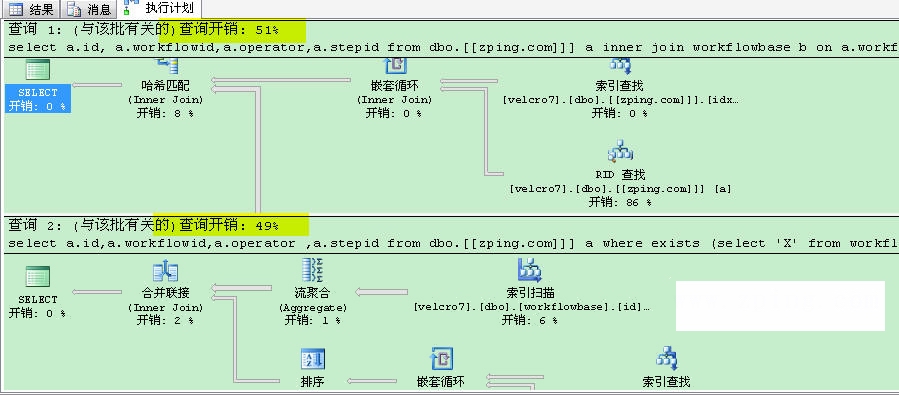
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
select * from workflowbase
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
执行结果:
(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
select * from workflowbase b
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划的更多相关文章
- SQL优化 查询语句中,用 inner join 作为过滤条件和用where作为过滤条件的区别
前段时间遇到一个存储过程,参数之一是一个字符串,在存储过程中,把字符串拆分成一个临时表之后存为一个key值的临时表,作为其中一个查询条件, 逻辑实现上有两种处理方式 insert into #t se ...
- exists改写SQL,使其走正确的执行计划
数据库环境:SQL SERVER 2005 今天看到一条SQL,写得不是很复杂,返回7000多条数据,却执行了15s.SQL文本及各表的数据量如下: SELECT acinv_07.id_item , ...
- 收集统计信息让SQL走正确的执行计划
数据库环境:SQL SERVER 2005 今天在生产库里抓到一条跑得慢的SQL,语句不是很复杂,返回的数据才有800多行, 却执行了34分钟,甚至更久. 先看一下执行结果 我贴一下SQL. SELE ...
- MySQL优化--NOT EXISTS和LEFT JOIN方式差异
在MySQL中,我们可以将NOT EXISTS语句转换为LEFT JOIN语句来进行优化,哪为什么会有性能提升呢? 使用NOT EXISTS方式SQL为: ) FROM t_monitor m WHE ...
- Oracle SQl优化总结
对数据库技术的热爱是我唯一的安慰,毕竟这是自己喜欢的事情,还可以做下去. 因为客户项目的需要,我又开始接触Oracle,大部分工作在工作流的优化和业务数据的排查上.为了更好的做这份工作,我有参考过or ...
- SQL优化注意事项
sql语句优化 性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的 ...
- sql优化点整理
此文是我最早开始sql优化至今整理的小知识点和经常遇到的问题,弄懂这些对优化大型的sql会有不少帮助 ---------------------------------使用了多余的外连接------- ...
- [03] SQL优化
1.SQL优化的实质 充分利用索引: 访问尽量少的数据块: 减少表扫描的I/O次数: 尽量避免全表扫描和其他额外开销: 2.oracle数据库常用的两种优化器 RBO(rule-based-optim ...
- SQL 优化,全
性能不理想的系统中除了一部分是因为应用程序的负载确实超过了服务器的实际处理能力外,更多的是因为系统存在大量的SQL语句需要优化. 为了获得稳定的执行性能,SQL语句越简单越好.对复杂的SQL语句,要设 ...
随机推荐
- ssm 数据库连接池配置
1.工程引入druid-1.1.2.jar包2.修改spring-common.xml文件 <!-- 1. 数据源 : DruidDataSource--> <bean id=&qu ...
- mysql-索引、导入、导出、备份、恢复
1.索引 索引是一种与表有关的结构,它的作用相当于书的目录,可以根据目录中的页码快速找到所需的内容. 当表中有大量记录时,若要对表进行查询,没有索引的情况是全表搜索:将所有记录一一取出,和查询条件进行 ...
- mongoDB全文索引
相关文章:php使用Coreseek实现全文索引 Introduction Mongo provides some functionality that is useful for text sear ...
- hdu_1020_Encoding_201310172120
Encoding Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total S ...
- 洛谷—— P2424 约数和
https://www.luogu.org/problem/show?pid=2424 题目背景 Smart最近沉迷于对约数的研究中. 题目描述 对于一个数X,函数f(X)表示X所有约数的和.例如:f ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- Ambari-部署常见问题
重新启动ambari-server端后调用install.start API后返回200 导致该问题的解决办法是server在启动后没有收到agent的心跳即没有与agent建立连接,在此时进行API ...
- password加密的算法
加密原理:採用不同的加密算法对字符串进行加盐加密处理. 用以防止密文被md5字典进行反向暴力破解. 採用美国家安全局发布的加密算法(RFC 4357)加密,不採用自己创建的加密算法,以避免有安全漏洞. ...
- Android热更新实现原理
最近Android社区的氛围很不错嘛,连续放出一系列的android动态加载插件和热更新库,这篇文章就来介绍一下Android中实现热更新的原理. ClassLoader 我们知道Java在运行时加载 ...
- B1588 [HNOI2002]营业额统计 set||平衡树
平衡树题,求每个点的前驱,照例可以用set水过...(平衡树还是不会写) 又新学了一个用法: set <int> ::iterator s1; 这样s1就可以直接附为set中的地址了.但是 ...