caffe 参数介绍 solver.prototxt
转载自 http://blog.csdn.net/cyh_24/article/details/51537709
solver.prototxt
net: "models/bvlc_alexnet/train_val.prototxt"
test_iter: 1000 #
test_interval: 1000 #
base_lr: 0.01 # 开始的学习率
lr_policy: "step" # 学习率的drop是以gamma在每一次迭代中
gamma: 0.1
stepsize: 100000 # 每stepsize的迭代降低学习率:乘以gamma
display: 20 # 每display次打印显示loss
max_iter: 450000 # train 最大迭代max_iter
momentum: 0.9 #
weight_decay: 0.0005 #
snapshot: 10000 # 没迭代snapshot次,保存一次快照
snapshot_prefix: "models/bvlc_reference_caffenet/caffenet_train"
solver_mode: GPU # 使用的模式是GPU test_iter
在测试的时候,需要迭代的次数,即test_iter* batchsize(测试集的)=测试集的大小,测试集的 batchsize可以在prototx文件里设置。test_interval
训练的时候,每迭代test_interval次就进行一次测试。momentum
灵感来自于牛顿第一定律,基本思路是为寻优加入了“惯性”的影响,这样一来,当误差曲面中存在平坦区的时候,SGD可以更快的速度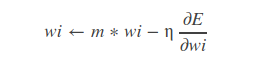
train_val.prototxt
layer { # 数据层
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN # 表明这是在训练阶段才包括进去
}
transform_param { # 对数据进行预处理
mirror: true # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param { # 设定数据的来源
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 256
backend: LMDB
}
}layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST # 测试阶段
}
transform_param {
mirror: false # 是否做镜像
crop_size: 227
# 减去均值文件
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_val_lmdb"
batch_size: 50
backend: LMDB
}
}lr_mult
学习率,但是最终的学习率需要乘以 solver.prototxt 配置文件中的 base_lr .如果有两个 lr_mult, 则第一个表示 weight 的学习率,第二个表示 bias 的学习率
一般 bias 的学习率是 weight 学习率的2倍’decay_mult
权值衰减,为了避免模型的over-fitting,需要对cost function加入规范项。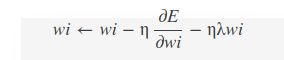
num_output
卷积核(filter)的个数kernel_size
卷积核的大小。如果卷积核的长和宽不等,需要用 kernel_h 和 kernel_w 分别设定
stride
卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。pad
扩充边缘,默认为0,不扩充。扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。
也可以通过pad_h和pad_w来分别设定。weight_filler
权值初始化。 默认为“constant”,值全为0.
很多时候我们用”xavier”算法来进行初始化,也可以设置为”gaussian”
weight_filler {
type: "gaussian"
std: 0.01
}- bias_filler
偏置项的初始化。一般设置为”constant”, 值全为0。
bias_filler {
type: "constant"
value: 0
}bias_term
是否开启偏置项,默认为true, 开启
group
分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集内。
卷积分组可以减少网络的参数,至于是否还有其他的作用就不清楚了。每个input是需要和每一个kernel都进行连接的,但是由于分组的原因其只是与部分的kernel进行连接的
如: 我们根据图像的通道来分组,那么第i个输出分组只能与第i个输入分组进行连接。pool
池化方法,默认为MAX。目前可用的方法有 MAX, AVE, 或 STOCHASTICdropout_ratio
丢弃数据的概率
caffe 参数介绍 solver.prototxt的更多相关文章
- Caffe solver.prototxt学习
在solver解决下面的四个问题: a.训练的记录(bookkeeping),创建用于training以及test的网络结构: b.使用前向以及反向过程对training网络参数学习的过程: c.对t ...
- Caffe的solver参数介绍
版权声明:转载请注明出处,谢谢! https://blog.csdn.net/Quincuntial/article/details/59109447 1. Parameters solver.p ...
- [转]caffe中solver.prototxt参数说明
https://www.cnblogs.com/denny402/p/5074049.html solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是so ...
- 4.caffe:train_val.prototxt、 solver.prototxt 、 deploy.prototxt( 创建模型与编写配置文件)
一,train_val.prototxt name: "CIFAR10_quick" layer { name: "cifar" type: "Dat ...
- caffe 中的一些参数介绍
转自:http://blog.csdn.net/cyh_24/article/details/51537709 solver.prototxt net: "models/bvlc_alexn ...
- caffe solver.prototxt 生成
from caffe.proto import caffe_pb2 s = caffe_pb2.SolverParameter() path='/home/xxx/data/' solver_file ...
- 人工智能深度学习Caffe框架介绍,优秀的深度学习架构
人工智能深度学习Caffe框架介绍,优秀的深度学习架构 在深度学习领域,Caffe框架是人们无法绕过的一座山.这不仅是因为它无论在结构.性能上,还是在代码质量上,都称得上一款十分出色的开源框架.更重要 ...
- caffe简单介绍
从四个层次来理解caffe:Blob.Layer.Net.Solver. 1.BlobBlob是caffe基本的数据结构,用四维矩阵 Batch×Channel×Height×Weight表示,存储了 ...
- Caffe源代码中Solver文件分析
Caffe源代码(caffe version commit: 09868ac , date: 2015.08.15)中有一些重要的头文件,这里介绍下include/caffe/solver.hpp文件 ...
随机推荐
- SQL Server对数据进行删除
SQL Server对数据进行删除,把页面的信息从数据库删除. auto"> <tr style="background:red"> <td> ...
- 设计包含min()函数的栈
题目:定义栈的数据结构,要求添加一个min函数,能够得到栈的最小元素.要求函数min.push以及pop的时间复杂度都是O(1). 分析:这是去年google的一道面试题. 我看到这道题目时,第一反应 ...
- 新书《计算机图形学基础(OpenGL版)》PPT已发布
为方便有些老师提前备课,1-10章所有章节已发布到本博客中. 欢迎大家下载使用,也欢迎大家给我们的新书反馈与意见,谢谢!
- Node.js标准的回调函数
Node.js标准的回调函数:第一个参数代表错误信息,第二个参数代表结果. function (err, data) 当正常读取时,err参数为null,data参数为读取到的String.当读取发生 ...
- codeforces 427D Match & Catch(后缀数组,字符串)
题目 参考:http://blog.csdn.net/xiefubao/article/details/24934617 题意:给两个字符串,求一个最短的子串.使得这个子串在两个字符串中出现的次数都等 ...
- Bamboo Django Celery定时任务和时间设置
1.Celery加入定时任务 Celery除了可以异步执行任务之外,还可以定时执行任务.在实例代码的基础上写个测试方法: 1 #coding:utf-8 2 from celery.task.sche ...
- uwsgi部署django,里的request调用的接口响应慢解决方法
解决方法,增加2个线程 uwsgi.ini 配置如下 chdir=/var/www/Ultramanpidfile=/tmp/uwsgi.pidmodule=Ultraman.wsgimaster=t ...
- ldap 禁止匿名登录(5)
[root@zabbix1 ~]# cat disable_anon.ldif dn: cn=config changetype: modify add: olcDisallows olcDisall ...
- 关于虚拟机中克隆的linux为什么不能开启网络服务
将centos克隆了一份,启动后并配置好文件,发现网络服务中只有lo(loopback),而网卡(eth0)没有启动,一开始以为是通信模式(bridged,NAT,host-only)的选择问题,最后 ...
- 继续聊WPF——进度条
ProgressBar控件与传统WinForm使用方法完全一样,我们只需关注: Minimum——最小值,默认为0: Maximum——最大值,默认为100. Value——当前值. 关键是它的控 ...