Opencv中K均值算法(K-Means)及其在图像分割中的应用
K均值(K-Means)算法是一种无监督的聚类学习算法,他尝试找到样本数据的自然类别,分类是K由用户自己定义,K均值在不需要任何其他先验知识的情况下,依据算法的迭代规则,把样本划分为K类。K均值是最常用的聚类技术之一,通过不断迭代和移动质心来完成分类,与均值漂移算法的原理很相似。
K均值算法的实现过程:
- 1. 对于一组未知分类的数据集合,指定其分类数K;
- 2. 随机分配K个类别的中心点位置,分配的原则是各个类别的中心点距离彼此越远越好。
- 3.将数据集中的每一个点进行类别划分,划分的距离N个初始的类别中心点中哪一个的距离最近,就划入哪一类;
- 4.根据上一步中初步划分的N个类别,分别计算当前每一类的样品中心,并移动初始中心点到当前集合所在的中心。
- 5.去除数据集合中每个点的归类属性,依据上边产生的中心点,转到第3步,迭代执行,直到中心点收敛。
K均值的核心就是不断移动类别划分的中心点,直到该点稳定下来或者达到所设置的最大迭代次数,这时当前中心点所划分的类别就是最终的K均值对样本数据的聚类。
下图是对K-Means迭代过程的简单演示。假设有n 个数据样本需要进行分类,这里k取值 为2:
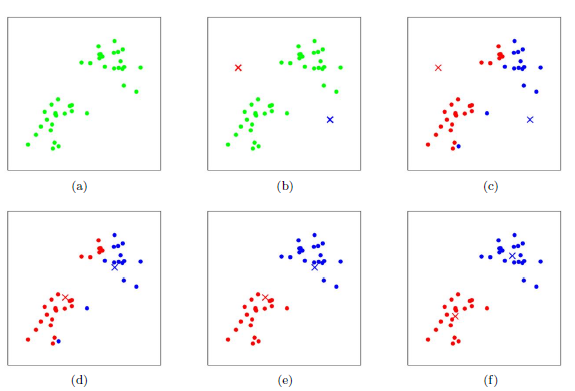
(a)初始数据集合
(b)随机选取两个点作为初始聚类中心
(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(d)计算每个聚类中所有点的坐标平均值,并将这个平均值 作为新的聚类中心
(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(f) 重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心,直到满足迭代条件。
虽然K-Means算法原理简单,也有自身的缺陷:
- 1.K值的选择需要用户指定,实际中K值 的估计很难做到准确,并且不同的K值得到的结果可能差别很大。
- 2.初始的聚类中心点的设定对结果影响较大。不同的初始聚类中心可能导致完全不同的聚类结果,并且不能保证K-Means算法收敛于全局最优解,极端情况下有可能达到局部收敛。
- 3.时间复杂度高0(nkt),其中n是对象总数,k是簇数,t是迭代次数。数据库较大的时候,收敛会比较慢。
#include <iostream>
#include <opencv2/core/core.hpp>
#include <imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
using namespace cv;
using namespace std;
int main(int argc, char* argv[])
{
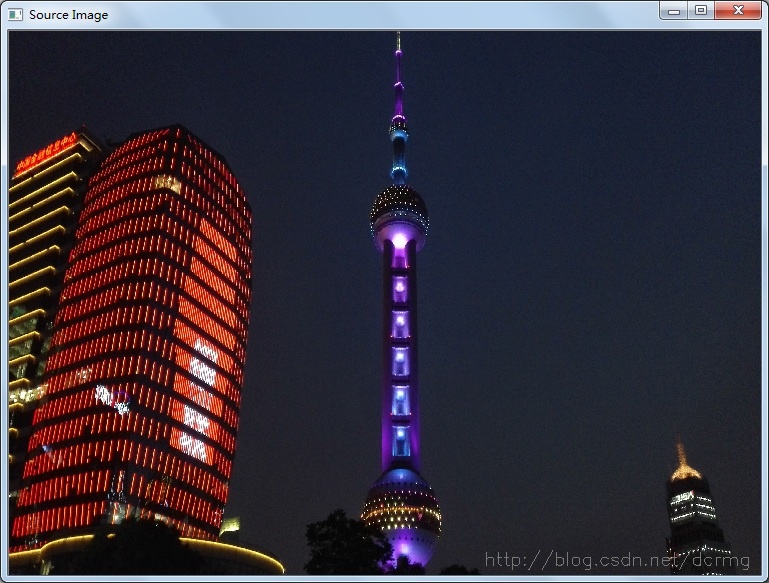
Mat img =imread("Sky.jpg");
namedWindow("Source Image",0);
imshow("Source Image", img);
//生成一维采样点,包括所有图像像素点,注意采样点格式为32bit浮点数。
Mat samples(img.cols*img.rows, 1, CV_32FC3);
//标记矩阵,32位整形
Mat labels(img.cols*img.rows, 1, CV_32SC1);
uchar* p;
int i, j, k=0;
for(i=0; i < img.rows; i++)
{
p = img.ptr<uchar>(i);
for(j=0; j< img.cols; j++)
{
samples.at<Vec3f>(k,0)[0] = float(p[j*3]);
samples.at<Vec3f>(k,0)[1] = float(p[j*3+1]);
samples.at<Vec3f>(k,0)[2] = float(p[j*3+2]);
k++;
}
}
int clusterCount = 4;
Mat centers(clusterCount, 1, samples.type());
kmeans(samples, clusterCount, labels,
TermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, 10, 1.0),
3, KMEANS_PP_CENTERS, centers);
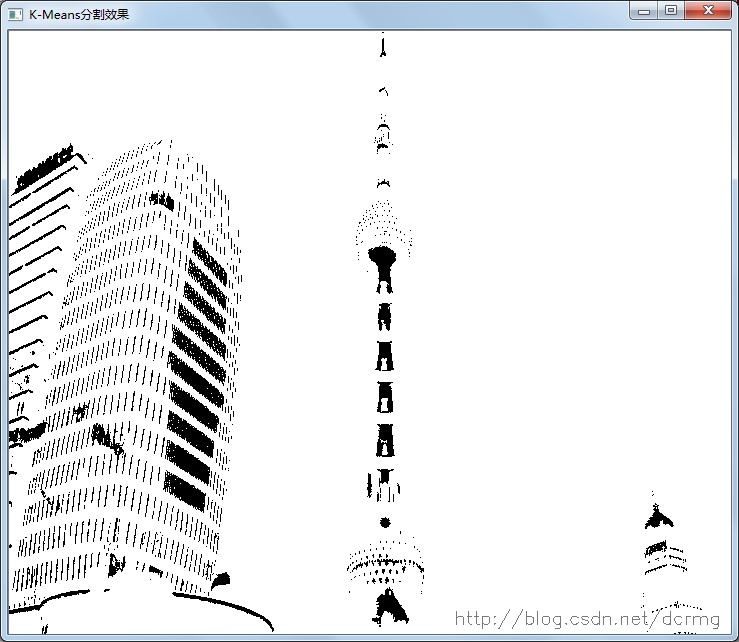
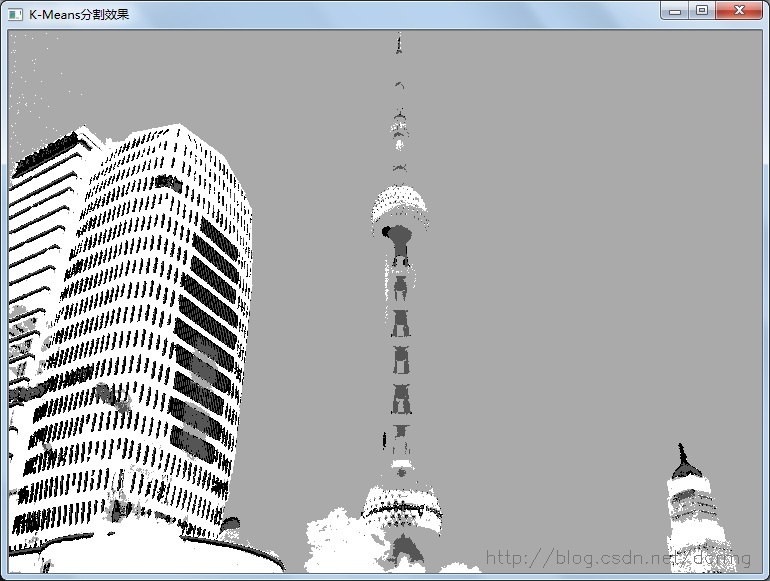
//我们已知有3个聚类,用不同的灰度层表示。
Mat img1(img.rows, img.cols, CV_8UC1);
float step=255/(clusterCount - 1);
k=0;
for(i=0; i < img1.rows; i++)
{
p = img1.ptr<uchar>(i);
for(j=0; j< img1.cols; j++)
{
int tt = labels.at<int>(k, 0);
k++;
p[j] = 255 - tt*step;
}
}
namedWindow("K-Means分割效果",0);
imshow("K-Means分割效果", img1);
waitKey();
return 0;
}

Opencv中K均值算法(K-Means)及其在图像分割中的应用的更多相关文章
- 使用K均值算法进行图片压缩
K均值算法 上一期介绍了机器学习中的监督式学习,并用了离散回归与神经网络模型算法来解决手写数字的识别问题.今天我们介绍一种机器学习中的非监督式学习算法--K均值算法. 所谓非监督式学习,是一种 ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
随机推荐
- 通过双重for循环来找到JSON中不反复的数据
//通过双重for循环来找到JSON中不反复的数据 var count = 0; for ( i=0; i<json.length; i++) { for ( j=0; j<i; j++) ...
- mjpg-streamer摄像头远程传输UVC
mjpg-streamer摄像头远程传输UVC 1 下载源代码 mjpg-streamer的源代码地址 https://github.com/codewithpassion/mjpg-streame ...
- 高性能 Python —— vectorization
首先来看一段判断一个整数数是否为素数的函数,然后从计算机内部计算流程的角度对其进行分析: import math def check_prime(number): sqrt_number = math ...
- Android JNI -基础篇
JNI(Java Native Interface,JAVA本地接口) 可以使Java代码和其他语言写的代码(如C/C++代码)进行交互.为什么要进行交互? 首先,Java语言提供的类库无法满足要求, ...
- 【CF706C】Hard problem
Description Vasiliy is fond of solving different tasks. Today he found one he wasn't able to solve h ...
- Qt 模仿QQ截图 动态吸附直线
最近在学Qt.学东西怎么能不动手. 就写了些小程序.看QQ截图能够动态吸附直线的功能挺有意思,所以就模仿了一个. 先上效果图 界面很简单..呵呵 移动鼠标,会把鼠标所在最小矩形选中.把没有选中的地方给 ...
- [转至云风的博客]谈谈陌陌争霸在数据库方面踩过的坑( Redis 篇)
« 谈谈陌陌争霸在数据库方面踩过的坑(芒果篇) | 返回首页 | linode 广告时间 » 谈谈陌陌争霸在数据库方面踩过的坑( Redis 篇) 注:陌陌争霸的数据库部分我没有参与具体设计,只是参与 ...
- ospf基本配置协议
OSPF(开放最短路径优先)协议是链路状态路由协议类.对于 IPv4 的 OSPF 当前版本号 OSPFv2,的版本号 John Moy 在 RFC 1247 中引入,并在 RFC 2328 中 ...
- 窗体背景的绘制(Windows窗体每次都会重绘其窗体背景,所以我们可以通过拦截窗体重绘背景的消息(WM_ERASEBKGND),并自定义方法来实现重绘窗体背景)
核心思想:由于Windows窗体每次都会重绘其窗体背景,所以我们可以通过拦截窗体重绘背景的消息(WM_ERASEBKGND),并自定义方法来实现重绘窗体背景.通过TImage组件也可以实现,但是重写W ...
- Java堆/栈/常量池以及String的详细详解(转)------经典易懂系统
一:在JAVA中,有六个不同的地方可以存储数据: 1. 寄存器(register). 这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部.但是寄存器的数量极其有限,所以寄存器由编译器根据 ...