python爬虫框架(1)--框架概述
框架概述
其中比较好用的是 Scrapy 和PySpider。pyspider上手更简单,操作更加简便,因为它增加了 WEB 界面,写爬虫迅速,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy自定义程度高,比 PySpider更底层一些,适合学习研究,需要学习的相关知识多,不过自己拿来研究分布式和多线程等等是非常合适的。
PySpider
PySpider是binux做的一个爬虫架构的开源化实现。主要的功能需求是:
- 抓取、更新调度多站点的特定的页面
- 需要对页面进行结构化信息提取
- 灵活可扩展,稳定可监控
pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫
- 通过python脚本进行结构化信息的提取,follow链接调度抓取控制,实现最大的灵活性
- 通过web化的脚本编写、调试环境。web展现调度状态
- 抓取环模型成熟稳定,模块间相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展
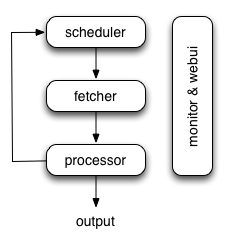
pyspider的架构主要分为 scheduler(调度器), fetcher(抓取器), processor(脚本执行):
- 各个组件间使用消息队列连接,除了scheduler是单点的,fetcher 和 processor 都是可以多实例分布式部署的。 scheduler 负责整体的调度控制
- 任务由 scheduler 发起调度,fetcher 抓取网页内容, processor 执行预先编写的python脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
- 每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作。
Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
- 然后,爬虫解析Response
- 若是解析出实体(Item),则交给实体管道进行进一步的处理。
- 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
python爬虫框架(1)--框架概述的更多相关文章
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
- python爬虫之scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 【转】Python爬虫(6)_scrapy框架
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html 性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下 ...
- 适合新手练习的Python项目有哪些?Python爬虫用什么框架比较好?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. Python爬虫一般用什么框架比较好?一般来讲,只有在遇到比较大型的需求时 ...
- (转)python爬虫----(scrapy框架提高(1),自定义Request爬取)
摘要 之前一直使用默认的parse入口,以及SgmlLinkExtractor自动抓取url.但是一般使用的时候都是需要自己写具体的url抓取函数的. python 爬虫 scrapy scrapy提 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- python爬虫中scrapy框架是否安装成功及简单创建
判断框架是否安装成功,在新建的爬虫文件夹下打开盘符中框输入cmd,在命令中输入scrapy,若显示如下图所示,则说明成功安装爬虫框架: 查看当前版本:在刚刚打开的命令框内输入scrapy versio ...
- python爬虫之Scrapy框架(CrawlSpider)
提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpi ...
随机推荐
- SQL授权语句(MySQL基本语句)
看他们网上的,写得都是千篇一律,同时,好多也写得不是很好,下面是我自己总结的有关mysql的使用细节,也是我在学习过程中的一些记录吧,希望对你有点帮助,后面有关存储过程等相关操作还没有总结好,下次总结 ...
- C# WPF DataGrid 隔行变色及内容居中对齐
C# WPF DataGrid 隔行变色及内容居中对齐. dqzww NET学习0 先看效果: 前台XAML代码: <!--引入样式文件--> <Window.Resourc ...
- vue项目组件的全局注册
在vue-cli项目中,我们经常会封装自己的组件,并且要在多个界面中引用它,这个时候就需要全局注册组件. 首先我们会封装自己的组件,比如twoDimensionTable文件夹下的index.vue: ...
- mysql 关联关系
一 单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 二 关键 ...
- MySQL 索引 视图 触发器 存储过程 函数
1.索引 索引相当于图书的目录,可以帮助用户快速的找到需要的内容. 数据库利用各种各样的快速定位技术,能够大大提高查询效率.特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万 ...
- Redis-简单动态字符串
这是读redis设计与实现的一系列读书笔记 1.SDS定义 C语言字符串:用一个 \0 结尾的 char 数组来表示 SDS:redis自己定义的简单动态字符串(simple dyanmic stri ...
- https页面 和 http请求的问题
(1)强制升级http 静态资源地址为https地址 https页面中不能使用http请求,http页面中可以使用https请求. 关于在https 页面有一些http的请求,可以在<head& ...
- [基本操作]决策单调性优化dp
一般的式子都是 $f_i = max\{g_j + w_{(i,j)}\}$ 然后这个 $w$ 满足决策单调性,也就是对于任意 $i < j$ ,$best_i \leq best_j$ 这样就 ...
- 洛谷 P3904 三只小猪
题目背景 你听说过三只小猪的故事吗?这是一个经典的故事.很久很久以前,有三只小猪.第一只小猪用稻草建的房子,第二个小猪用木棍建的房子,第三个小猪则使用砖做为材料.一只大灰狼想吃掉它们并吹倒了稻草和木棍 ...
- spark gateway引发:跟踪Cloudera安装服务异常日志跟踪
spark gateway是用于接收cloudera管理的应用:可以上报数据,不影响正常使用.启动gateway失败,我觉得可能是因为配置问题? 这个问题可能比较深,因为我通过查看日志(clouder ...