简单的方法爬取b站dnf视频封面步骤解释
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
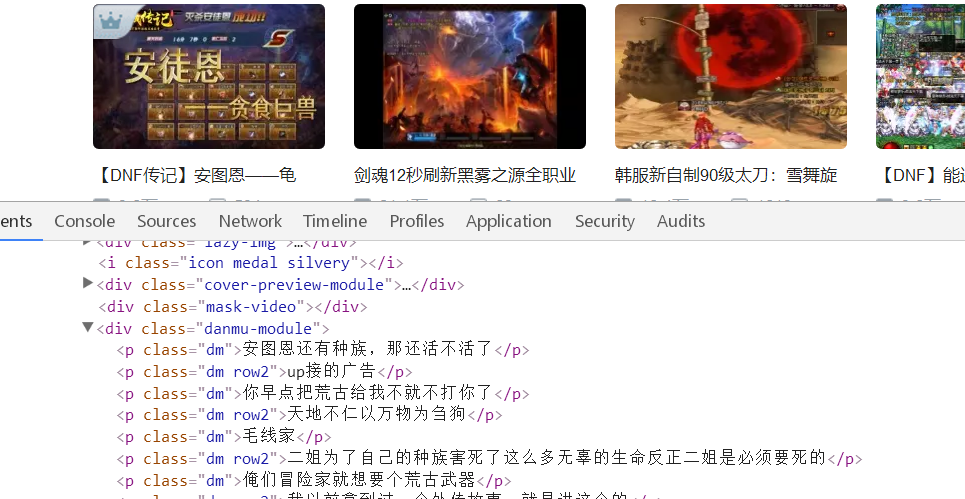
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
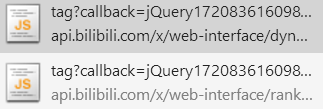

进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?

让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...

查找开头第一个(,然后截取至最后一个),里面不就是了吗?
def instr(keystr):
st=keystr.find('(')+1
strhtml=keystr[st:len(keystr)-1]
return strhtml
def picsave(strJson,number):
global cnt
strdic=strJson['data']['archives']
num=len(strdic)
for i in range(0,num,1):
cnt=cnt+1
strdic=strJson['data']['archives'][i]
print(strdic['pic'])
urllib.request.urlretrieve(strdic['pic'],'E:\图片\dnf\%s.jpg'%(cnt))
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。
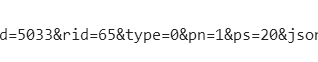
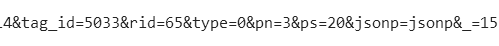
于是...
def urlget(num):
for i in range(1,num,1):
url='https://api.bilibili.com/x/tag/ranking/archives?callback=jQuery172014070206081723846_1514982701564&tag_id=5033&rid=65&type=0&pn='+str(i)+'&ps=20&jsonp=jsonp&_=1514982702144'
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
html=instr(html)
strJson=eval(html)
picsave(strJson,i)
然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码
简单的方法爬取b站dnf视频封面步骤解释的更多相关文章
- Python 简单的方法爬取b站dnf视频封面
import urllib.request cnt=0 def instr(keystr): st=keystr.find('(')+1 strhtml=keystr[st:len(keystr)-1 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 爬取b站互动视频信息
首先分辨视频是不是互动视频可以看 https://api.bilibili.com/x/player.so?id=cid:1&aid=89017 这个api返回的xml中的 <inter ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- Codechef Union on Tree
Codechef Union on Tree https://www.codechef.com/problems/BTREE 简要题意: 给你一棵树,\(Q\)次询问,每次给出一个点集和每个点的\(r ...
- 杂项:grunt-tmod
ylbtech-杂项:grunt-tmod 前端模板预编译工具 tmodjs 的grunt自动化插件. 1.返回顶部 1. grunt-tmod 前端模板预编译工具 tmodjs 的grunt自动化插 ...
- Mybaits整合Spring自动扫描 接口,Mybaits配置文件.xml文件和Dao实体类
1.转自:https://blog.csdn.net/u013802160/article/details/51815077 <?xml version="1.0" enco ...
- [poj1088]滑雪(二维最长下降子序列)
解题关键:记忆化搜索 #include<cstdio> #include<cstring> #include<algorithm> #include<cstd ...
- [codeforces821E]Okabe and El Psy Kongroo
题意:(0,0)走到(k,0),每一部分有一条线段作为上界,求方案数. 解题关键:dp+矩阵快速幂,盗个图,注意ll 关于那条语句为什么不加也可以,因为我的矩阵C,就是因为多传了了len的原因,其他位 ...
- Express的日志模块morgan
morgan 是nodejs的一个日志模块,由 express 团队维护. 这里通过示例简要介绍morgan模块在express中的应用,大部分示例直接来自于.morgan的文档:https://gi ...
- redis 有用 Sorted-Set 应用场景
1.1.1Set数据类型的 使用场景 1.可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息.对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中 ...
- 《精通Spring4.X企业应用开发实战》读后感第七章(创建增强类)
- hdu1063
#include<iostream> #include<string> using namespace std; struct BigReal //高精度实数 { int le ...
- 2、Jquery_事件
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...