聚类算法(二)--BIRCH
BIRCH (balanced iterative reducing and clustering using hierarchies)(名字太长不用管了)
无监督,适合大样本的聚类方法。大多数情况只需扫描一次数据集。(文中有下划线的均表示向量)
一句话概括BIRCH,就是根据某种距离度量方法将数据簇已CF形式表现出来,又根据一定规则在CF树上排列(看不懂没关系)
下面我们展开说。
先讲CF
首先CF代表的是数据簇,哪怕是只有一个点,也看做簇
定义CF(N,LS,SS),N代表数据簇的样本点个数,LS表示数据点同一特征之和,SS表示所有样本点特征值平方值和。
举例说明。
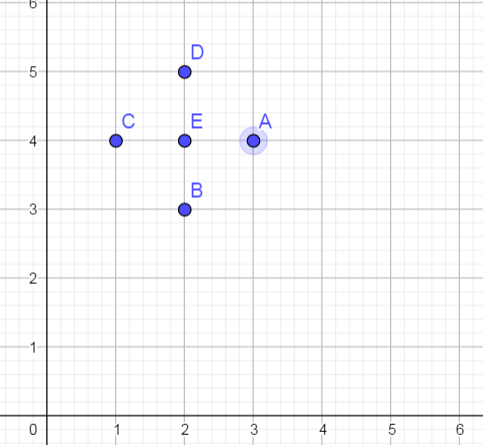
假设上述五点属于一个CF,A(3,4),B(2,3),C(1,4),D(2,5),E(2,4)
N=5,LS=(3+2+1+2+2,4+3+4+5+4)=(10,20),SS=9+16+4+9+1+16+4+25+4+16=104
所以CF=[5,(10,20),104]
那么,CF有个容易理解的性质--可加性,CF1=CF2+CF3=(N2+N3,LS2+LS3,SS2+SS3)
CF还有几个参数:
形心(Centroid):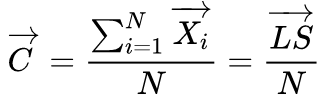
半径(radius):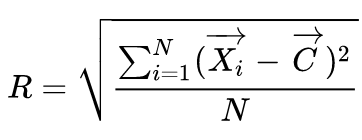 (表示为簇内一点到形心的距离,类似于标准差,所以可以变换成标准差的计算,$\sqrt{\frac{NSS-LS^{2}}{N^{2}}}$)
(表示为簇内一点到形心的距离,类似于标准差,所以可以变换成标准差的计算,$\sqrt{\frac{NSS-LS^{2}}{N^{2}}}$)
(簇内所有点两两之间的平均距离)$\delta =\sqrt{\frac{\sum \sum \left (x_{i}-\overrightarrow{c} \right )^{2}(x_{j}-\overrightarrow{c})^{2}}{N(N-1)}}$
R和δ都表示了簇的紧实度。
某种距离度量方法
即簇与簇之间的距离的度量D,比如
欧几里得距离$\sqrt{(\frac{\sum LS_{1}}{N_{1}}-\frac{\sum LS_{2}}{N_{2}})^{2}}$
曼哈顿距离$\left | \frac{\sum LS_{1}}{N_{1}}-\frac{\sum LS_{2}}{N_{2}} \right |$
一定规则在CF树上排列
一定规则指的是CF树的参数,枝平衡因子β(一个枝节点包含叶节点个数的上限),叶平衡因子λ(一个叶节点包含CF个数的上限),空间阈值τ(簇与簇距离的上限)
这里建造的CF树不保留数据原始信息,只有CF,所以起到压缩数据的作用
现在我们看看如何造树
一棵树一般有根节点(RN,root node),枝节点(BN,branch node),叶节点(LN,leaf node)。
1,首先第一个数据进来,建造CF1,作为根节点。(无任何限制)
2,第二个数据进来,建造CF2,计算簇与簇之间的距离D,若D<τ,将这两点视为同一簇,更新CF1.若D>空间阈值τ,将CF1,CF2都作为枝节点;
3,上面两步只讲到了增加或者膨胀节点,如何分裂节点呢?
举例说明,

在红色情况下设定枝平衡因子β=3,叶平衡因子λ=3,
进来一个新样本点sc8,他与叶节点LN1,2,3中LN1的距离最近,所以应该归入LN1叶节点,
计算sc8与sc1,2,3的距离,均大于空间阈值τ,所以不能并入sc1,2,3,需要给他成为一个独立的簇,
但是由于叶平衡因子λ=3,即一个叶节点包含簇个数的上限为3,所以要将叶节点LN1分裂成两个LN1',LN1''。
但是此时相当于有四个叶节点LN1',LN1'',LN2,LN3,又枝平衡因子β=3,即一个枝节点包含叶节点个数的上限为3,
所以将根节点(本应该为枝节点,此例无枝节点)也一分为二,如下图

还有一个问题,刚才的四个簇sc8,1,2,3,如何分入叶节点LN1',LN1''
求这四个簇相距最远的最为LN1',LN1''的种子CF,将剩余的簇分别计算与种子CF的距离,距离近的归到一个叶节点
具体解释,假设sc8,1,2,3中,sc8和sc2最远,先将这两个簇放入不同的叶节点,然后分别计算sc1,sc3与sc8和sc2的距离,较近的归为种子CF所在的叶节点。
BIRCH适用于大样本,与Mini Batch K-Means类似,但是BIRCH适用于K较大的情况,Mini Batch K-Means适用K适中或较小
当维度较大时,Mini Batch K-Means比BIRCH表现的好。
参考:
https://www.cnblogs.com/pinard/p/6179132.html
https://www.cnblogs.com/tiaozistudy/p/6129425.html
https://en.wikipedia.org/wiki/BIRCH
聚类算法(二)--BIRCH的更多相关文章
- 聚类算法之BIRCH(Java实现)转载
http://www.cnblogs.com/zhangchaoyang/articles/2200800.html http://blog.csdn.net/qll125596718/article ...
- 机器学习:Python实现聚类算法(二)之AP算法
1.算法简介 AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法.AP算法的基本思想是将全部数据点都 ...
- 关于k-means聚类算法的matlab实现
在数据挖掘中聚类和分类的原理被广泛的应用. 聚类即无监督的学习. 分类即有监督的学习. 通俗一点的讲就是:聚类之前是未知样本的分类.而是根据样本本身的相似性进行划分为相似的类簇.而分类 是已知样本分类 ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理.这里我们再来看看另外一种常见的聚类算法BIRCH.BIRCH算法比较适合于数据量大,类别数K也 ...
- 多种聚类算法概述(BIRCH, DBSCAN, K-means, MEAN-SHIFT)
BIRCH:是一种使用树分类的算法,适用的范围是样本数大,特征数小的算法,因为特征数大的话,那么树模型结构就会要复杂很多 DBSCAN:基于概率密度的聚类方法:速度相对较慢,不适用于大型的数据,输入参 ...
- 机器学习:Python实现聚类算法(三)之总结
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作 ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
- ML: 聚类算法-概论
聚类分析是一种重要的人类行为,早在孩提时代,一个人就通过不断改进下意识中的聚类模式来学会如何区分猫狗.动物植物.目前在许多领域都得到了广泛的研究和成功的应用,如用于模式识别.数据分析.图像处理.市场研 ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
随机推荐
- MySQL- 常用的MySQL函数,指令等
MySQL查看版本: status: 或者 select version(); //select @@version MySQL昨天, 一周前 ,一月前 ,一年前的数据 这里主要用到了 DATE_SU ...
- UniDAC 安装教程
翻译: 1.解压后把UniDAC文件夹直接复制到你专门用来存放第三方控件的地方(这一步根据自己的喜好,可以跳过这一步)2.在UniDAC\Source\Delphi21文件夹中找到Make.bat文件 ...
- HashOperations
存储格式:Key=>(Map<HK,HV>) 1.put(H key, HK hashKey, HV value) putAll(H key, java.util.Map<? ...
- VS2013修改resource之后产生designer1.cs
1. Unload project2. Edit the csproj file.3. Search for <LastGenOutput>test1.Designer.cs</La ...
- Python基础-列表推导式
python中列表推导式有三种数据类型可用:列表,字典,集合 列表推导式书写形式: [表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件] 1,列表推导式 ...
- PHP中怎样让数组以字母为键值来递增
//小写字母 $key = 97; $arr = array(); for($i=1;$i<=26;$i++){ $arr[chr($key)] = $i; $key++; } print_r( ...
- 基于libRTMP的流媒体直播之 AAC、H264 推送
这段时间在捣腾基于 RTMP 协议的流媒体直播框架,其间参考了众多博主的文章,剩下一些细节问题自行琢磨也算摸索出个门道,现将自己认为比较恼人的 AAC 音频帧的推送和解析.H264 码流的推送和解析以 ...
- DP小合集
1.Uva1625颜色的长度 dp[i][j]表示前一个串选到第i个 后一个串选到第j个 的最小价值 记一下还有多少个没有结束即dp2 记一下每个数开始和结束的位置 #include<cstdi ...
- HihoCoder1664 01间隔方阵([Offer收割]编程练习赛40)(DP)
给定一个NxM的01矩阵,小Hi希望从中找到一个01间隔的子方阵,并且方阵的边长越大越好. 例如对于 0100100 1000101 0101010 1010101 0101010 在右下角有一个4x ...
- BZOJ1033:[ZJOI2008]杀蚂蚁
我对模拟的理解:https://www.cnblogs.com/AKMer/p/9064018.html 题目传送门:https://www.lydsy.com/JudgeOnline/problem ...