异构数据库迁移——DATAX
背景
在最近接触到的一个case里面,需要把db2的数据迁移至oracle,客户可接收的停机时间为3小时。
同步方式的比较
一说到停机时间,大家第一时间想到Oracle公司的GoldenGate实时同步工具。但在测试过程中发现,由于无法提前检查,而且初始化时间很久等问题,导致我们最后不得不放弃使用这一神器。
既然OGG不能使用,那能传统导出文本再用sql load导入,那是否可行呢?根据以往的经验,只要数据一落地就存在乱码,数据错位等问题,由于无法进行hash对账,数据质量根本无法保证。
我司的某平台软件,直接从内存中进行数据转换,让我们看到一大希望。由于列的顺序不一,无法满足部分需求,只能又放弃这一神器。
就在此时,提出了一个开源软件——DATAX。
什么是DATAX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
注意,这里说的是离线数据同步工具,就是必须得停机之后再进行数据同步。那DATAX究竟支持哪些数据库进行数据同步呢?以下是GitHub提供的列表:
|
类型 |
数据源 |
Reader(读) |
Writer(写) |
文档 |
|
RDBMS 关系型数据库 |
MySQL |
√ |
√ |
|
|
Oracle |
√ |
√ |
||
|
SQLServer |
√ |
√ |
||
|
PostgreSQL |
√ |
√ |
||
|
DRDS |
√ |
√ |
||
|
通用RDBMS(支持所有关系型数据库) |
√ |
√ |
||
|
阿里云数仓数据存储 |
ODPS |
√ |
√ |
|
|
ADS |
√ |
|||
|
OSS |
√ |
√ |
||
|
OCS |
√ |
√ |
||
|
NoSQL数据存储 |
OTS |
√ |
√ |
|
|
Hbase0.94 |
√ |
√ |
||
|
Hbase1.1 |
√ |
√ |
||
|
MongoDB |
√ |
√ |
||
|
Hive |
√ |
√ |
||
|
无结构化数据存储 |
TxtFile |
√ |
√ |
|
|
FTP |
√ |
√ |
||
|
HDFS |
√ |
√ |
||
|
Elasticsearch |
√ |
DataX3.0核心架构
在这个case里面,我们使用datax3.0的核心架构。DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
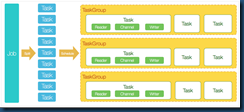
核心模块介绍:
JSON配置
JOB全局配置:
JOB通过配置对同步整个过程进行管控。
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
speed为同步速度限制参数,这里有三个参数channel、record和byte。channel:管道数,可以理解为并行数,需与splitPk一同使用,否则无效果。
record:每次同步多少条数据,取record和byte中的最小值
byte:每次同步多少字节数据,取record和byte中的最小值
errorLimit为错误数据限制,这里有两个参数record和percentage,指当异常数据达到多少时同步取消,取record和percentage的最小值。
Reader线程配置:
RDBMSReader通过JDBC连接器连接到远程的RDBMS数据库,并根据用户配置的信息生成查询SELECT SQL语句并发送到远程RDBMS数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
对于用户配置Table、Column、Where的信息,RDBMSReader将其拼接为SQL语句发送到RDBMS数据库;对于用户配置querySql信息,RDBMS直接将其发送到RDBMS数据库。
DB2被阿里分为通用RDBMS的范畴。配置一个从RDBMS数据库同步抽取数据作业样例:
"content": [
{
"reader": {
"name": "rdbmsreader",
"parameter": {
"username": "xxx",
"password": "xxx",
"column": [
"id",
"name"
],
"splitPk": "pk",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:dm://ip:port/database"
]
}
],
"fetchSize": 1024,
"where": "1 = 1"
}
},
username
源数据库的用户名
password
源数据库的密码
encoding
数据库字符集,GBK,UTF8等
column
所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用代表默认使用所有列配置,例如['']。
支持列裁剪,即列可以挑选部分列进行导出。
支持列换序,即列可以不按照表schema信息进行导出。
支持常量配置,用户需要按照JSON格式: ["id", "1", "'bazhen.csy'", "null", "to_char(a + 1)", "2.3" , "true"] id为普通列名,1为整形数字常量,'bazhen.csy'为字符串常量,null为空指针,to_char(a + 1)为表达式,2.3为浮点数,true为布尔值。
Column必须显示填写,不允许为空!
splitPk
RDBMSReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,不支持浮点、字符串型、日期等其他类型。如果用户指定其他非支持类型,RDBMSReader将报错!
注意:这里并非只能是主键,拥有唯一约束的列也可。
table
所选取的需要同步的表名
jdbcUrl
描述的是到对端数据库的JDBC连接信息,jdbcUrl按照RDBMS官方规范,并可以填写连接附件控制信息。请注意不同的数据库jdbc的格式是不同的,DataX会根据具体jdbc的格式选择合适的数据库驱动完成数据读取。
fetchSize
该配置项定义了插件和数据库服务器端每次批量数据获取条数,该值决定了DataX和服务器端的网络交互次数,能够较大的提升数据抽取性能。
注意,该值最大建议值为2048。
where
筛选条件,RDBMSReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。例如在做测试时,可以将where条件指定为limit 10;在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。
小结: 我司某产品不被我们选用主要是配置中不存在column和where两个条件的参数,无法对部分数据进行过滤。
Writer线程配置:
OracleWriter 插件实现了写入数据到 Oracle 主库的目的表的功能。在底层实现上, OracleWriter 通过 JDBC 连接远程 Oracle 数据库,并执行相应的 insert into ... sql 语句将数据写入 Oracle,内部会分批次提交入库。
OracleWriter 面向ETL开发工程师,他们使用 OracleWriter 从数仓导入数据到 Oracle。同时 OracleWriter 亦可以作为数据迁移工具为DBA等用户提供服务。
OracleWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置生成相应的SQL语句
insert into...(当主键/唯一性索引冲突时会写不进去冲突的行)对于使用datax同步到oracle的表,建议删除主键和唯一索引,数据校验完成后再进行重建。
"writer": {
"name": "oraclewriter",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:oracle:thin:@[HOST_NAME]:PORT:[DATABASE_NAME]",
"table": [
"test"
]
}
]
}
username
目的数据库的用户名
password
目的数据库的密码
encoding
数据库字符集
batchSize
一次性批量提交的记录数大小,该值可以极大减少DataX与Oracle的网络交互次数,并提升整体吞吐量。最大只能设置为1024
column
的表需要写入数据的字段,字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。如果要依次写入全部列,使用表示, 例如: "column": [""]
preSql
执行语句时会先检查是否存在若存在,根据条件删除
jdbcUrl
目的数据库的 JDBC 连接信息
table
目的表的表名称。支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。
同步测试记录
数据转换最高速度一条管道13000rec/s+,通过where手工对部分字段拆分进程进行同步,同步536250880rec大约需要90分钟(容量300GB)的时间。
异构数据库迁移——DATAX的更多相关文章
- 异构数据库迁移 db2---oracle
异构数据库迁移 其他数据库迁移到oracle,以移植db2数据库对象到Oracle的操作说明为例,其他数据库迁移到oracle类似. 移植之平台和相关工具 OS:linux DBMS:db2 Ora ...
- Oracle数据库迁移到AWS云的方案
当前云已经成为常态,越来越多的企业希望使用云来增加基础设施的弹性.减轻基础设施的维护压力,运维的成本等.很多企业使用云碰到的难题之一是如何将现有的应用迁移到云上,将现有应用的中间件系统.Web系统及其 ...
- 转 【TTS】AIX平台数据库迁移到Linux--基于RMAN(真实环境)
[TTS]AIX平台数据库迁移到Linux--基于RMAN(真实环境) http://www.cnblogs.com/lhrbest/articles/5186933.html 各位技术爱好者,看完本 ...
- 从其他数据库迁移到MySQL及MySQL特点
从其他数据库迁移到MySQL Oracle,SQL Server迁移到MySQL 一些变化 不再使用存储过程.视图.定时作业 表结构变更,如采用自增id做主键,以及其他语法变更 业务SQL改造,不使用 ...
- EF Code First Migrations数据库迁移
1.EF Code First创建数据库 新建控制台应用程序Portal,通过程序包管理器控制台添加EntityFramework. 在程序包管理器控制台中执行以下语句,安装EntityFramewo ...
- 2.EF中 Code-First 方式的数据库迁移
原文链接:http://www.c-sharpcorner.com/UploadFile/3d39b4/code-first-migrations-with-entity-framework/ 系列目 ...
- laravel数据库迁移(三)
laravel号称世界上最好的框架,数据库迁移算上一个,在这里先简单入个门: laravel很强大,它把表中的操作写成了migrations迁移文件,然后可以直接通过迁移文件来操作表.所以 , 数据迁 ...
- Code First开发系列之数据库迁移
返回<8天掌握EF的Code First开发>总目录 本篇目录 开启并运行迁移 使用迁移API 应用迁移 给已存在的数据库添加迁移 EF的其他功能 本章小结 自我测试 本系列的源码本人已托 ...
- ABP Migration(数据库迁移)
今天准备说说EntityFramework 6.0+,它与我之前所学的4.0有所区别,自从4.1发布以来,code first 被许多人所钟爱,Dbcontext API也由此时而生.早在学校的时候就 ...
随机推荐
- Kure讲HTML_div标签和table标签
为什么要把这两个标签放在一起讲? 个人认为div标签可以算是一个万能标签,它可以通过CSS(层叠样式表)来模仿表格的形式来生成一个表格.那么很多人可能会疑惑那在开发的时候,到底是用div+css的形式 ...
- Windows 2008 R2 防火墙允许Serv-U通过的方法
在Windows 2008 R2上安装了Serv-U FTP服务端软件之后,无法通过客户端连接,究其原因是Windows 2008的防火墙没有开启FTP端口,而且在防火墙上添加Serv-U程序也不行, ...
- C#窗体控件GroupBox修改边框色
控件Group Box默认的边框的颜色是白色的,在很多时候显得不那么突出.但默认的属性列表里面并没有提供相应的接口.所以只能借助重绘事件. 网上很多都说使用 OnPaint 事件,但是我在事件列表中没 ...
- 动态LINQ(Lambda表达式)构建
using System; using System.Collections.Generic; using System.Linq; using System.Linq.Expressions; us ...
- 谈谈Quartz中遇到的深坑
最近在项目开发的时候,根据业务需求,需要配置为自定义Quartz任务(即:用户可以自定义任务执行时间) 但是在即将写完的时候遇到一个非常头疼的问题: 一个redisTemplate 与 workOrd ...
- Flask文件目录----- auth/blog 文件
import functools from flask import (Blueprint, flash, g, redirect, render_template, url_for, request ...
- 5.jQuery&Ajax
1.jQuery 什么是 jQuery ? jQuery是一个JavaScript函数库.jQuery是一个轻量级的"写的少,做的多"的JavaScript库.包含以下功能: HT ...
- Object-C 语法 字符串 数组 字典 和常用函数 学习笔记
字符串 //取子字符串 NSString *str1=@"今天的猪肉真贵,200块一斤"; NSString *sub1=[str1 substringFromIndex:4]; ...
- MySQL数据库实验二:单表查询
实验二 单表查询 一.实验目的 理解SELECT语句的操作和基本使用方法. 二.实验环境 是MS SQL SERVER 2005的中文客户端. 三.实验示例 1.查询全体学生的姓名.学号.所在系. ...
- Uva 10791 最小公倍数的最小和 唯一分解定理
题目链接:https://vjudge.net/contest/156903#problem/C 题意:给一个数 n ,求至少 2个正整数,使得他们的最小公倍数为 n ,而且这些数之和最小. 分析: ...