FM
1、FM (因子分解机)
2、FM的作用:
(1)特征组合是许多机器学习建模过程中遇到的问题,如果对特征直接进行建模,很可能会忽略掉特征与特征之间的关联信息,因此,可以通过构建新的交叉特征这一特征组合方式提高模型的效果。
(2)高维的稀疏矩阵是实际工程过程中常见的问题,并直接回导致计算量过大,特征权值更新缓慢。试想一个10000*100的表,每一列都有8种元素,经过one-hot独热编码之后,会产生一个10000*800的表。因此表中每行元素只有100个值为1,700个值为0。
而FM的优势就在于这两方面问题的处理。首先是特征组合,通过对两两特征组合,引入交叉项特征,提高模型得分;其次是高维灾难,通过引入隐向量,(对参数矩阵进行矩阵分解),完成对特征的参数估计。
3、FM适应场景:
FM可以解决特征组合以及高维系数矩阵问题,而实际业务长江汇总,电商、豆瓣等推荐系统场景是使用最广的领域。
4、FM的样子:
首先,看一下线性表达式:
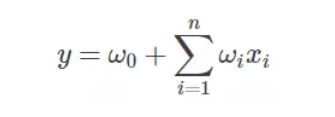
其中w0为初始权值,wi为每个特征xi对应的权值。可以看到,这种线性表达式值描述了每个特征与输出的关系。
FM表达式:(引入了交叉项)

5、FM交叉项的展开
5.1、寻找交叉项
FM表达式的求解核心在于对交叉项的求解。



5.3、交叉项展开式





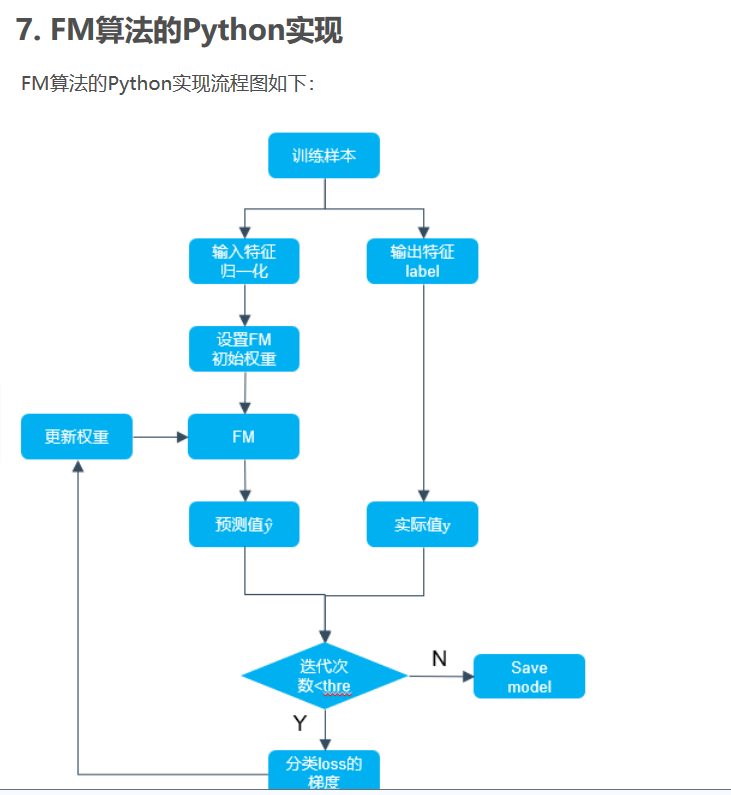

代码数据集的获取:https://pan.baidu.com/s/1TcCV55sgUbjmMVmipJUgSQ
from __future__ import division
from math import exp
import numpy as np
from numpy import *
from random import normalvariate
from datetime import datetime
import pandas as pd trainData = 'diabetes_train.txt'
testData = 'diabetes_test.txt' def preprocessData(data):
feature = np.array(data.iloc[:,:-1])#取特征,最后一列之前的列为特征列
label = data.iloc[:,-1].map(lambda x :1 if x==1 else -1)#取标签并转化为+1,-1
# 将数组按行进行归一化,按列axis=0取每一列的最大值和最小值
zmax,zmin = feature.max(axis=0),feature.min(axis = 0)
feature = (feature -zmin )/(zmax-zmin)
label = np.array(label)
# print(type(feature),label)
return feature,label def sigmoid(inx):
return 1.0/(1+exp(-inx)) def SGD_FM(dataMatrix,classLabels,k,iter):
'''
dataMatrix特征矩阵
classLabels类别矩阵
k辅助向量的大小
iter迭代次数
return
'''
# dataMatrix用的是mat,classLabels是列表
m,n = shape(dataMatrix) #矩阵的行列数,即样本数和特征数
alpha = 0.01
#初始化参数
# w = random.randn(n,1) #n是特征的个数
w = zeros((n,1))#一阶特征的系数,初始为1 n行1列
# print (w)
w_0 = 0.
v = normalvariate(0,0.2)*ones((n,k)) #即生成辅助向量用来训练二阶交叉特征的系数 for it in range(iter):
for x in range(m):
inter_1 = dataMatrix[x] * v # *表示矩阵的点乘
inter_2 = multiply(dataMatrix[x],dataMatrix[x]) * multiply(v,v)
interaction = sum(multiply(inter_1,inter_1) - inter_2) /2
p = w_0 + dataMatrix[x] *w + interaction
loss = 1-sigmoid(classLabels[x]*p[0,0])
w_0 = w_0 + alpha * loss *classLabels[x]
for i in range(n):
if dataMatrix[x,i] !=0:
w[i,0] = w[i,0] +alpha *loss *classLabels[x] *dataMatrix[x,i]
for j in range(k): v[i,j] = v[i,j] + alpha *loss*classLabels[x] * (dataMatrix[x,i]*inter_1[0,j]-v[i,j]*dataMatrix[x,i]*dataMatrix[x,i])
print("第{}次迭代后的损失为{}".format(it,loss))
return w_0,w,v def getAccuracy(dataMatrix,classLables,w_0,w,v):
m,n = shape(dataMatrix)
allItem = 0
error = 0
result = []
for x in range(m):
allItem +=1
inter_1 = dataMatrix[x] *v
inter_2 = multiply(dataMatrix[x],dataMatrix[x])*multiply(v,v)
interaction = sum(multiply(inter_1,inter_1)-inter_2)/2
p = w_0 + dataMatrix[x]*w +interaction pre = sigmoid(p[0,0])
result.append(pre) if pre < 0.5 and classLables[x] == 1.0:
error +=1
elif pre >= 0.5 and classLables[x] == -1.0:
error += 1
else:
continue
return float(error) / allItem if __name__ == '__main__':
train = pd.read_csv(trainData)
test = pd.read_csv(testData)
dataTrain,labelTrain = preprocessData(train)
dataTest,labelTest = preprocessData(test)
date_startTrain = datetime.now()
print("开始训练")
w_0,w,v = SGD_FM(mat(dataTrain),labelTrain,20,60)
print("训练准确率为:%f"%(1-getAccuracy(mat(dataTrain),labelTrain,w_0,w,v)))
date_endTrain = datetime.now()
print("训练用时为:%s"%(date_endTrain-date_startTrain))
print("开始测试")
print("测试准确性为:%f"%(1-getAccuracy(mat(dataTest),labelTest,w_0,w,v)))
参考:https://blog.csdn.net/sun_wangdong/article/details/86505011
FM的更多相关文章
- SAP(ABAP) 显示等待图标的FM:SAPGUI_PROGRESS_INDICATOR-SAP进度条
在执行一些数据量大的报表时候,为了防止用户认为是死机,可以再程序中添加正在处理的图标,可以CALL一个 FM来实现. CALL FUNCTION 'SAPGUI_PROGRESS_INDICATOR' ...
- 喜马拉雅FM抓包之旅
一.概述 最近学院组织安排大面积实习工作,今天刚刚发布了喜马拉雅FM实习生招聘的面试通知.通知要求:公司采用开放式题目的方式进行筛选,申请的同学须完成如下题目 写程序输出喜马拉雅FM上与"卓 ...
- FM四舍五入_从小数点最后一位进位
原贴地址:http://jiahongguang12.blog.163.com/blog/static/334665720071060551591/ 输入参数12.5445,因此FM从小数点最后一位进 ...
- 豆瓣FM 歌词跟随插件
一直在用豆瓣FM,发现老是没有歌词很不方便,今天找了下.找到一个不错的插件. 插件原文地址:http://www.douban.com/group/topic/47559280/ 插件下载地址:htt ...
- python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书
1.初衷:想在网上批量下载点听书.脱口秀之类,资源匮乏,大家可以一试 2.技术:wireshark scrapy jsonMonogoDB 3.思路:wireshark分析移动APP返回的各种连接分类 ...
- 通信原理实践(三)——FM调制
一.FM调制 1.代码如下: clc,clear; fm = ; % 调制信号频率(Hz) Am = 0.5; % 调制信号幅度 fc = 5e3; % 载波频率(Hz) Ac = ; % 载波幅度 ...
- Ubantu下面命令听歌(豆瓣fm)
在Linux下一直是不太方便的事情,下面推荐一个方法: 终端中输入以下命令安装豆瓣fm: >> sudo pip install douban.fm >> sudo apt-g ...
- Android FM模块学习之四源码分析(3)
接着看FM模块的其他几个次要的类的源码.这样来看FM上层的东西不是太多. 请看android\vendor\qcom\opensource\fm\fmapp2\src\com\caf\fmradio\ ...
- Android FM模块学习之四源码学习(2)
前几章我们分析了FM模块的几个主要的类文件,今天要分析的是:FMTransceiver.java // 某些工程中名称为FMRadioService.java public class FmTra ...
- Android FM 模块学习之四 源码解析(1)
Normal 0 7.8 磅 0 2 false false false EN-US ZH-CN X-NONE MicrosoftInternetExplorer4 前一章我们了解了FM手动调频,接下 ...
随机推荐
- js 在输出到页面的5中方式
1.alert("要输出的内容"); ->在浏览器中弹出一个对话框,然后把要输出的内容展示出来 ->alert都是把要输出的内容首先转换为字符串然后在输出的 2.doc ...
- 170831-关于JdbcTemplate声明式事务-操作步骤-例子
创建一个动态web工程 加入jar包 3.创建一份jdbc.properties文件 4.在spring配置文件中配置数据源 5.测试数据源: 6.配置jdbcTemplate: 7.创建Dao类 & ...
- 关于c++ error : passing " "as" " discards qualifiers
http://www.cppblog.com/cppblogs/archive/2012/09/06/189749.html 今天写了一段小代码,本以为正确,但运行后,就somehow ”discar ...
- Qualcomm 8X camera过程解析【转】
本文转载自:http://blog.csdn.net/gabbzang/article/details/19906687 http://www.01yun.com/mobile_development ...
- docker 提高效率 network-bridging 桥接
安装的时间顺序 bit3 192.168.107.128 wredis 192.168.107.129 wmysql 192.168.107.130 wslave 192.168.107.131 w ...
- fedora23安装firefox中的flash插件-最终解决问题是: 要给libflashplayer.so以777权限, 开始给的755权限没有实现!
下载的flash插件是一个rpm包. ===================================== rpm查看文件属于哪个包? 要看这个rpm包安装过还是没有安装过? (如果不用-p就是 ...
- 启动tomcat报错One or more listeners failed to start,却找不到任何错误日志的临时解决方案
在整合spring和quartz时,启动tomcat,服务台报以上错误,却找不到任何错误日志…… 参考了https://www.cnblogs.com/sxdcgaq8080/p/8005886.ht ...
- 阶段1 语言基础+高级_1-3-Java语言高级_1-常用API_1_第4节 ArrayList集合_14-ArrayList集合的常用方法和循环
常用的方法记下来 刚创建好,什么都不放的 add添加方法肯定是成功的. 加了这么多的值都没有用返回值,输出的结果可以看到都是添加成功的 获取索引值 ALT+回车键,推荐使用本地变量去接收 这样左边就会 ...
- 类String
1字符串声明和创建 boolean contains(String str) 判断大字符串中是否包含小字符串 boolean endsWith(String str) 判断字符串是否以某个指定的字符串 ...
- Notepad++的tab设置为四个空格
参考:https://www.cnblogs.com/jyfootprint/p/9409934.html 1.Python使用缩进来组织代码块,坚持使用4个空格的缩进. 在文本编辑器中,需要设置把T ...