Python之-爬虫
1、得到页面的HTML代码


第一个参数是URL
第二三个参数可以不传送,数据和时间
2、request请求
HTTP是基于请求和应答的,客户端发出请求,服务端做出响应,所以urllib2创建一个request对象,代表发送的HTTP请求。

3、数据传送POST和GET
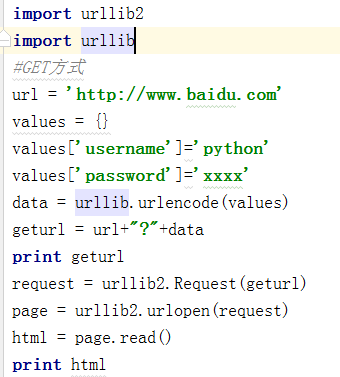
GET方式
直接把参数写到URL当中。
和我们平常GET访问方式一模一样,用一个问号连接传送的数据
POST方式

4、Headers
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性。

5、异常处理
【1】URLEeeor
产生的原因:
网络无连接
服务器不存在
连接不到服务器
在代码中,我们需要用try-except语句来包围并捕获相应的异常

【2】HTTPEeeor
每个来自服务器的HTTP应答都包含一个数值的状态码。有时候,状态码表明服务器不能满足我们做出的请求。默认的handlers将会帮我们处理一些应答(例如,应答是一个重定向,要求客户端从不同的URL抓取资源,urllib2将会替你处理好)。但是总有一些不能处理好,urloprn将会抛出一个HTTPError异常。典型的异常有404(页面丢失),403(请求被禁止),401(要求验证)


注意,HTTPError一定要放在最前面进行捕获。因为HTTPError是URLError的子集,不然的话会一直捕获到的是URLError

6、Cookie
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
但是URLopen只接受三个参数:url、data、timeout
urllib2库.官方文档翻译 - 莫利斯安的博客 - 博客频道 - CSDN.NET http://blog.csdn.net/u014343243/article/details/49308043
Python之-爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
随机推荐
- Critical Links
UVA 796 Critical Links http://acm.hust.edu.cn/vjudge/contest/view.action?cid=82833#overview 题目大意:给你一 ...
- CocoaPods中pod search报错的解决办法
pod search报错的原因: 每次使用pod search命令的使用会在该目录下生成一个search_index.json文件,会逐渐的增大,文件达到一定大小后,ruby解析里面的json字符就会 ...
- python中常犯错误之字符串列表下标问题
下标用得是中括号[] 不是小括号() 1,python中的小括号( ):代表tuple元组数据类型,元组是一种不可变序列.创建方法很简单,大多时候都是用小括号括起来的. 2.python中的中括号[ ...
- JVM调优(三)——基于Btrace的监控调试
JVM调优(三)--基于Btrace的监控调试 简介 Btrace可以动态地向目标应用程序的字节码注入追踪代码 用到的技术: JavaComplierApi.JVMTI.Agent.Instrumen ...
- HttpCanary——最强Android抓包工具!
迎使用HttpCanary——最强Android抓包工具! HttpCanary是一款功能强大的HTTP/HTTPS/HTTP2网络包抓取和分析工具,你可以把他看成是移动端的Fiddler或者Char ...
- 头疼3-4次的问题,数据从DB导出到EXCEL,再从EXCEL导入到DB,数据格式发生错误 ,导致 程序出错。
反思: 1 解决 问题的思路 绕远了: 在这个问题出现前,程序是运行正确 的 问题出现前,我误删了DB 的 testcase表的所有 case ,然后 再把邮件 中的excel数据导入到 DB 然后 ...
- UITableView 支持左右滑动(一)
原理如下: SwipeTableView subView 1 : UIScrollView作为容器, 主要负责左右滑动, 每个tableView的顶部设置相同的contentInset subVie ...
- Spring中ApplicationContext加载机制和配置初始化
Spring中ApplicationContext加载机制. 加载器目前有两种选择:ContextLoaderListener和ContextLoaderServlet. ...
- selenium,webdriver模仿浏览器访问百度 基础1
这是一种比较好的反反爬技术 #安装:pip install selenium=2.48.0 #显示:pip show selenium #卸载:pip uninstall selenium #模拟用户 ...
- vue中使用videojs打包后体积过大优化
videojs 是一个非常好的js库,可以支持各种格式的视频播放,也能做直播流.官网地址 https://videojs.com/ 在vue项目中也可以使用 vue-video-player ,更好的 ...