利用ARIMA算法建立短期预测模型
周五福利日活动是电信为回馈老用户而做的活动,其主要回馈老用户的方式是让用户免费领取对应的优惠券,意在提升老用户的忠诚度和活跃度。今日,为保证仓库备货优惠券资源充足,特别是5元话费券等,需要对该类优惠券领取效果进行预测,从而指导备货。经研究选用ARIMA算法建立预测模型,对5元话费券进行日领取量的短期预测。数据集收集了2019年1月到2019年2月5元话费券的日领取量数据,并根据此数据做时间序列分析并建立预测模型。
1、进行数据的加载
from statsmodels.tsa.stattools import acf, pacf
import statsmodels.api as sm
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy.stats as stats receive=pd.read_excel(r'E:\Ering\data\HF_5.xlsx')
2、进行一阶差分和检验一阶差分的效果
#设置一下时间索引并进行一阶差分
receive.index=pd.Index(pd.date_range('1/1/2019','31/3/2019',freq='1D'))
receive['number'].plot()
receive['number'].diff(1).plot()

利用自相关系数的白噪声检验差分效果
# 利用自相关系数的白噪声检验差分后的数据是否是平稳序列:
r,q,p=sm.tsa.acf(receive['number'].diff(1).iloc[1:92].values.squeeze(),qstat=True) #squeeze: 除去size为1的维度
mat=np.c_[range(1,41),r[1:],q,p] #np.c_是按行连接两个矩阵,把两矩阵左右相加,要求行数相等,类似pandas的merge()
table=pd.DataFrame(mat,columns=['lag','AC','Q','Prob(>Q)'])
LB_result=table.iloc[[5,11,17]]
LB_result.set_index('lag',inplace=True)
LB_result
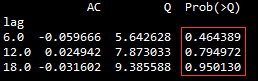
上图是自相关系数白噪声检验的结果,P值均大于0.05,表明白噪声检验不显著,所以数据经过一阶差分后平稳,故此知道一阶差分后所形成的序列是平稳序列。ARIMA算法的一个重要应用前提是保证算法入口的数据是平稳的。差分阶次对应ARIMA(p,d,q)中的d数值,因此本文中的d可以设置为1。
3、确定系数p和q
# 利用BIC最小的模型作为识别的依据,确定参数p和参数q:
order_p,order_q,bic=[],[],[]
model_order=pd.DataFrame()
for p in range(4):
for q in range(4):
arma_model=sm.tsa.ARMA(receive['number'].diff(1).iloc[1:89].dropna(),
(p,q)).fit()
order_p.append(p)
order_q.append(q)
bic.append(arma_model.bic)
print('The BIC of ARMA(%s,%s) is %s'%(p,q,arma_model.bic)) model_order['p']=order_p
model_order['q']=order_q
model_order['BIC']=bic
P=list(model_order['p'][model_order['BIC']==model_order['BIC'].min()])
Q=list(model_order['q'][model_order['BIC']==model_order['BIC'].min()])
print('最好的模型是ARMA(%s,%s)' %(P[0],Q[0]))

根据BIC法则确定可知,当p值和q值分别为1和0的时候,可以取到模型的效果最好。
4、建立ARIMA预测模型
#建立ARIMA模型
model=sm.tsa.ARMA(receive['number'].diff(1).iloc[1:89].dropna(),(1,0)).fit(method='css') #使用最小二乘,‘mle’是极大似然估计
#画图比较一下预测值和真实观测值之间的关系
fig=plt.figure(figsize=(8,6))
ax=fig.add_subplot(111)
ax.plot(receive['number'].diff(1).iloc[1:89],color='blue',label='number')
ax.plot(model.fittedvalues,color='red',label='Predicted number')
plt.legend(loc='lower right')

5、差分值转化为原始值
# 差分数据转化为原始值
def forecast(step,var,modelname):
diff=list(modelname.predict(len(var)-1,len(var)-1+step,dynamic=True))
prediction=[]
prediction.append(var[len(var)-1])
seq=[]
seq.append(var[len(var)-1])
seq.extend(diff)
for i in range(step):
v=prediction[i]+seq[i+1]
prediction.append(v) prediction=pd.DataFrame({'Predicted number':prediction})
return prediction[1:] #第一个值是原序列最后一个值,故第二个值是预测值。
forecast(15,receive['number'][1:89],model)

如图是4月1-5号的预测值。
6、模型残差项的白噪声检验及正态性检验
# 模型残差项的白噪声检验:
resid=model.resid
r,q,p=sm.tsa.acf(resid.values.squeeze(),qstat=True)
mat_res=np.c_[range(1,41),r[1:],q,p] #np.c_是按行连接两个矩阵,把两矩阵左右相加,要求行数相等,类似pandas的merge()
table=pd.DataFrame(mat_res,columns=['to lag','AC','Q','Prob(>Q)'])
LB_result_res=table.iloc[[5,11,17,23]]
LB_result_res.set_index('to lag',inplace=True)
LB_result_res
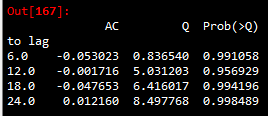
如果ARMA模型估计的好,应当使得估计值后的残差项是白噪声。上图是预测结果的残差的白噪声检验结果,分析可知Prob值均较大,查阅资料显示Prob值较大时,接受原假设-残差是白噪声Prob值接近于0时拒绝原假设;接近于1时接受原假设;Prob值为10%时,表示10%置信区间下通过。
至此模型建立完毕。
利用ARIMA算法建立短期预测模型的更多相关文章
- 利用CART算法建立分类回归树
常见的一种决策树算法是ID3,ID3的做法是每次选择当前最佳的特征来分割数据,并按照该特征所有可能取值来切分,也就是说,如果一个特征有四种取值,那么数据将被切分成4份,一旦按某特征切分后,该特征在之后 ...
- 【数据结构】 最小生成树(四)——利用kruskal算法搞定例题×3+变形+一道大水题
在这一专辑(最小生成树)中的上一期讲到了prim算法,但是prim算法比较难懂,为了避免看不懂,就先用kruskal算法写题吧,下面将会将三道例题,加一道变形,以及一道大水题,水到不用高级数据结构,建 ...
- 利用Manacher算法寻找字符串中的最长回文序列(palindrome)
寻找字符串中的最长回文序列和所有回文序列(正向和反向一样的序列,如aba,abba等)算是挺早以前提出的算法问题了,最近再刷Leetcode算法题的时候遇到了一个(题目),所以就顺便写下. 如果用正反 ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- 利用Apriori算法对交通路况的研究
首先简单描述一下Apriori算法:Apriori算法分为频繁项集的产生和规则的产生. Apriori算法频繁项集的产生: 令ck为候选k-项集的集合,而Fk为频繁k-项集的集合. 1.首先通过单遍扫 ...
- [Tool]利用Advanced Installer建立x86/x64在一起的安装程式
原文 [Tool]利用Advanced Installer建立x86/x64在一起的安装程式 之前使用InstallShield做安装程式时,如果要将程式放在Program Files的话,需要分别针 ...
- opencv利用hough概率变换拟合得到直线后,利用DDA算法得到直线上的像素点坐标
图片霍夫变换拟合得到直线后,怎样获得直线上的像素点坐标? 这是我今天在图像处理学习中遇到的问题,霍夫变换采用的概率霍夫变换,所以拟合得到的直线信息其实是直线的两个端点的坐标,这样一个比较直接的思路就是 ...
- SA:利用SA算法解决TSP(数据是14个虚拟城市的横纵坐标)问题——Jason niu
%SA:利用SA算法解决TSP(数据是14个虚拟城市的横纵坐标)问题——Jason niu X = [16.4700 96.1000 16.4700 94.4400 20.0900 92.5400 2 ...
- 使用LSTM-RNN建立股票预测模型
硕士毕业之前曾经对基于LSTM循环神经网络的股价预测方法进行过小小的研究,趁着最近工作不忙,把其中的一部分内容写下来做以记录. 此次股票价格预测模型仅根据股票的历史数据来建立,不考虑消息面对个股的影响 ...
随机推荐
- “CreateRiaClientFilesTask”任务意外失败。 未能加载文件程序集“System.ComponentModel.DataAnnot...
错误 77 “CreateRiaClientFilesTask”任务意外失败. System.Web.HttpException (0x80004005): 未能加载文件或程序集“System. ...
- 三、IIS通过目录方式部署以供外部调试
一.IIS 下面是通过 gif 为 因项目是bin生成后的,非运行方式的调试,所以断点调试无效,仅修改文件后,右击项目重新生成解决方案即可,好处:启动快,坏处:不可以断点调试查看变量和分步执行语句.
- SQL的子查询与JOIN的小试牛刀
//学生表CREATE TABLE student( ID INT PRIMARY KEY, s_name ) NOT NULL, class_id INT NOT NULL); , "qf ...
- C++11新特性之 Move semantics(移动语义)
https://blog.csdn.net/wangshubo1989/article/details/49748703 这篇讲到了vector的push_back的两种重载版本,左值版本和右值版本.
- 【Http】队头阻塞(Head of line blocking)多路复用(Multiplexing)
图中第一种请求方式,就是单次发送request请求,收到response后再进行下一次请求,显示是很低效的. 于是http1.1提出了管线化(pipelining)技术,就是如图中第二中请求方 ...
- 2019牛客多校第五场G-subsequence 1 DP
G-subsequence 1 题意 给你两个字符串\(s.t\),问\(s\)中有多少个子序列能大于\(t\). 思路 令\(len1\)为\(s\)的子序列的长度,\(lent\)为\(t\)的长 ...
- 【数据库】一篇文章搞掂:MySQL数据库
一.安装 使用版本:5.7(2018/08/03 阿里云的云数据库最高支持5.7,所以这里考虑用5.7) 下载版本:MySQL Community Server 5.7.23 下载地址:https:/ ...
- leetcode上的一些栈、队列问题
20-有效的括号 思路:主要考察栈的一些基本操作,像push()(将数据压入栈顶).top()(取栈顶的数据但不删除).pop()(直接删除栈顶的元素).empty()(判断栈是否为空).这题就是先把 ...
- kafka ProducerConfig 配置
kafka-clients : 1.0.1
- (57)C# frame4 调用frame2
http://msdn.microsoft.com/zh-cn/library/bbx34a2h.aspx https://www.cnblogs.com/weixing/archive/2012/0 ...